|
[2005 年 7 月号] |
|
[2005 年 7 月号] |
[技術講座]
株式会社 オージス総研
オブジェクトテクノロジーソリューション第三部
更谷 暢哉
エンタープライズシステムのような大量の情報管理を行うシステムにおいては、データベースシステムは必須です。現在、データベースシステムには、リレーショナルデータベース(RDBMS)以外にも、XML データベースやオブジェクト指向データベースと選択肢も増えています。しかし、既存リソースの再利用や使い勝手、性能、製品のブランド等を考慮すると、RDBMS が選択されることが多いと思います。
Java 側のオブジェクトと、RDBMS 側のレコードを対応付けて相互に変換することを O/R マッピングと言います。Java では O/R マッピングに関する処理は、DataAccessObject (DAO) パターン [3] によって局所化し、 DAO 内で JDBC によって RDBMS にアクセスするような設計がよく使われます(図 1-1)。
JDBC を使った O/R マッピングは、単調で煩雑な作業です。問合せでは Statement に対して SQL 文とパラメータをセットして実行し、検索結果の ResultSet からカラムの値を 1 つ 1 つ取得して、永続クラスにセットします。 更新、挿入では、永続クラスのフィールドの値を 1 つ 1 つ Statement にセットしなければなりません。これらの処理を自動化できないか、と考えている方や、実際に何らかの方法で自動化している方も多いのではないでしょうか。
この O/R マッピング部分をフレームワークとして提供してくれるのが O/R マッピングツールです。 O/R マッピングツールを用いると、単調で煩雑な作業から解放されることと、 自動化されることによってバグが入り込む隙が無くなることの 2 重のメリットがあります。 O/R マッピングツールは商用製品、オープンソースと多数存在します。
本稿ではその中でも最近人気が高まりつつあり、非常に使いやすいオープンソースの O/R マッピングツールである Hibernate を取り上げます。 基本的な使い方から始まり、よりよい設計の提案や、独自に拡張したツールの紹介等、Hibernate は現場で使えるツールか、という観点で解説していきます。
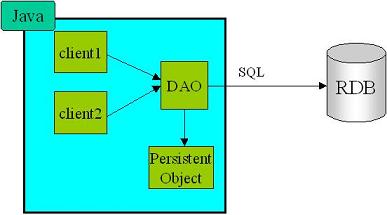 |
| 図 1-1. DAO パターン |
Hibernate (https://www.hibernate.org/) は、オープンソースの軽量O/Rマッピングツールです。Hibernate を使うことで、次のようなメリットが得られます。
Hibernate では、XML 形式のマッピングファイルによって、 Java オブジェクトと RDBMS のレコードのマッピングを定義します(図2-1)。 アプリケーションコードは、パーシステンスを Hibernate から非常に簡単に行えます。 マッピングやデータベースの操作といったパーシステンスに関する詳細が隠蔽されていることで、 アプリケーションプログラマはデータベースを意識しなくて済みます。
マッピング情報だけでなく、データソースやトランザクション戦略等全てのコンフィギュレーションを XML や properties ファイルによってアプリケーションコードの外部で定義できます。 コンフィギュレーションをコードと分離することは、拡張性を高めることにつながります。
軽量であるとは、対象とする分野に集中し、シンプルで使いやすいという意味です。 Hibernate の扱う対象は JDBC を介して RDBMS へのパーシシテンスを行うことです。 オブジェクトデータベースや XML データベース等を扱えませんが、 1 つのことに集中することで非常に使いやすいフレームワークとなっています。 Hibernate はパーシステンスに関しては、レイジーローディングやキャッシュ等をサポートし、非常に高機能です。 軽量であるというのは、高機能ではない、ということを意味するのではなく、 EJB のように広い範囲を対象とした重量級のツールではない、ということです。 Hibernate の内部では、周辺的な問題には積極的に既存のフレームワークを利用しています。 例えば、ログには Apache Commons、ネーミングインタフェイスには JNDI を使用しています。
Hibernate は透明性を守りながらパーシステンスを行ってくれます。 透明性とは、ビジネスドメインモデルからパーシステンスサービスやトランザクションサービスを独立させることです。 これによって、ビジネスドメインモデルが理解しやすく、メンテナンスや要求の変化への対応がしやすくなります。 Hibernate では、Java オブジェクトにパーシステンスのためのインタフェースの実装を強制せず、 サービスと独立した POJO(Plain Old Java Object:通常のJavaBeans) を使用することができます。
また、Hibernate は、小規模プロジェクトから大規模プロジェクトまで対応可能です。 Hibernate のアーキテクチャは非常に柔軟です。 簡単なアプリケーションでは、Hibernate が提供する JDBC コネクションとトランザクション管理を使うことができます。 一方、JTA を用いた高度なトランザクションを使いたい、JDBC コネクションへ直接アクセスしたい、 各 RDBMS の持つ SQL の拡張機能を使いたい、といった要求にも対応します。 そういった拡張可能な部分はインタフェースとして抽象化されており、 既に多くの実装が提供されていますが、 開発者が独自に実装することも可能にしています。
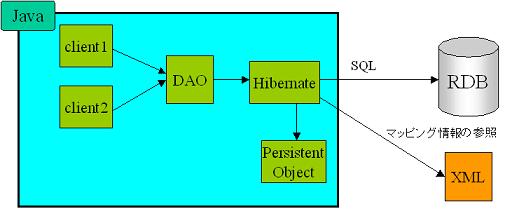 |
| 図 2-1.Hibernate による O/R マッピング |
Hibernate を利用するための準備は非常に簡単です。https://www.hibernate.org/の Download より、Hibernate と HibernateExtensions をダウンロードしてください。 本稿の解説は Hibernate 2.x を前提にしていますが、 最新版の Hibernate 3.x を使用する場合でも基本的なところはほぼ同じです。
以下の jar ファイルを、クラスパスの通っているプロジェクトの適当なフォルダにコピーします。
Hibernate によるアプリケーション構築の流れは以下のようになります。
以下の解説では図 3-0-1 のような従業員と部門というエンティティを用います。
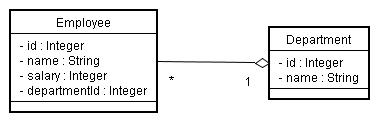 |
| 図 3-0-1.クラス図:従業員と部門 |
Hibernate では、Java クラス、RDBMS のテーブル、そのマッピング定義ファイルの 3 つが必要です。 Hibernate では、この中の 1 つを作ることで残りの 2 つを自動で生成することが可能です。 生成ツールには、Hibernate メインパッケージに含まれているもの、 Hibernate 拡張パッケージ(Hibernate Extensions)に含まれているもの、 サードパーティ製のものがあります。
Hibernate メインパッケージ
- hbm2ddl ・・・マッピングファイルから DDL を生成します。
Hibernate 拡張パッケージ
- hbm2java ・・・マッピングファイルから Java ファイルを生成します。
サードパーティ製ツール
- middlegen ・・・ DDL からマッピングファイルを生成します。
- XDoclet ・・・Java ファイルからマッピングファイルを生成します。
新規に開発を行う場合は、マッピングファイルを作り、それを元に Java ファイルと DDL を生成すると良いと思います。 ただし、どのツールも若干機能的に不充分な面があります。 例えば、hbm2ddl では外部キーが暗号のような文字の羅列で生成されますし、 hbm2javaは、コメントの生成が若干貧弱であるという面や、 以前生成したすべてのファイルを上書きしてしまうという面があるため注意が必要です。 プロジェクトによっては、充分な場合もあるでしょうが、現実的にはツールのカスタマイズを行うか、 マッピングファイルからの自動生成ツールを自作するべきかもしれません。 第 4 章では、hbm2java のカスタマイズの例を詳しく紹介します。
従業員クラスのマッピングファイル EMPLOYEE.hbm.xml と部門クラスのマッピングファイル DEPARTMENT.hbm.xml をご覧ください。
<hibernate-mapping>
この中にマッピング情報を記述していきます。package は、ここで定義するクラスが entity パッケージであることを指定しています。<class>
クラス名とそれに対応するテーブル名を記述します。<hibernate-mapping>の中には複数の <class> を定義できますが、実際のプロジェクトでは 1 つのクラス定義でもかなりの情報量になりますので、 1 つのクラスにつき 1 つのマッピングファイルとする方が現実的です。<id>
主キーを記述します。<generator> は、ユニークな識別子を生成するために使うジェネレータ Java クラスを指定するための、必須の子要素です。ここで指定するジェネレータは、net.sf.hibernate.id.IdentifierGenerator インターフェイスを実装していなければなりません。
Hibernate は、組込みの実装を多数提供しています。 それらはクラスのフルパスの代わりとなるショートカット名で指定することが可能です。 assigned は、レコードを保存する前にアプリケーションが識別子を代入することを可能にするジェネレータです。 他にもいくつか組み込み実装が用意されており、例えば Oracle などでシーケンスを利用したい場合は、sequence というショートカットを使用します。
<property>
主キー以外の属性を記述します。name には小文字で始まる Java クラスのフィールド名を、type にはフィールドの型を、column には DB テーブルのカラム名を指定します。type に指定できる型には以下のものがあります。
- Hibernate の基本型の名前(例 integer, string, character, date,...)
- デフォルトの基本型のJava クラス名(例 int, java.lang.String, java.util.Date, java.lang.Integer, ...)
- PersistentEnum のサブクラスの名前
- シリアライズ可能な Java クラスの名前
- カスタム型のクラス名
関連
EMPLOYEE.hbm.xml の<many-to-one> は、多対 1 の関連を定義します。 ここでは、DEPARTMENT_ID によって参照される部門クラスのインスタンスをフィールドとして持つことになります。
DEPARTMENT.hbm.xml の<one-to-many> は、逆に 1 対多の関連を定義します。 ここでは、ID と等しい DEPARTMENT_ID を持つ従業員クラスのインスタンスを コレクション Set のフィールドとして持っています。
他に、多対多の関連を定義する <many-to-many >や、1 対 1 の関連を定義する <one-to-one> があります。
<query>
Hibernate は SQL に似たオブジェクト指向クエリ言語 HQL を備えています。 HQL は、JDBC での SQL 同様コード内に記述できますが、マッピングファイル内に定義した HQL を呼び出すこともできます。 クエリをアプリケーションコードの外部で定義することで、ソースコードとクエリを分離することができるため、 この機能は非常に役に立ちます。
レイジーローディング
関連を定義することにより、 Hibernate は自動的に関連するクラスのインスタンスの取得を行ってくれます。 しかし、使用するつもりのない関連まで常に問い合わせが行われることは、パフォーマンス上問題となります。
レイジーローディング(lazy 初期化とも言います)は、 必要になるまで関連するクラスのインスタンスを取得しない機能です。 DEPARTMENT.hbm.xml には、2 種類のレイジーローディングの設定をしています。
1 つは <set> に対する lazy 指定です。 配列以外のコレクションに対しては、このように lazy 指定をすることで 実際にコレクションの getter メソッド(ここでは getEmployees メソッド)が呼ばれるまで コレクションの実際のインスタンス取得を行いません。
多対 1 の関連では、コレクションではなく直接関連するクラスのインスタンスをフィールドとして持ちます。 この場合lazy指定ができないため、もう 1 つの方法である lazy 初期化プロキシを使用します。 lazy 初期化プロキシは、オブジェクトに対する操作を行う直前に、 DBから実際のオブジェクトの取得を行ってくれます。
ここでは、Employee がフィールドとして持つ Department インスタンスをレイジーローディングするために、 DEPARTMENT.hbm.xml において、<class> に proxy を設定しています。 Hibernate は、Employee のフィールドとして Department のプロキシインスタンスを設定してくれます。 実際の Department インスタンスが取得されるのは、プロキシインスタンスに対して何らかのメソッドが呼ばれた時になります。
lazy 初期化プロキシを使用する場合は、いくつか注意する点があります。
- フィールドに直接アクセスした場合、lazy 初期化は行われない
- proxy に指定したプロキシ・インタフェースのプロキシが生成されるため、 取得されるインスタンスのスーパークラスを proxy に指定した場合にダウンキャストを行うことができまない
- 通常 Hibernate では、同一 Session 内では、インスタンスの参照に関して == が成り立ちますが、 プロキシを使用するとこれが成り立たなくなる
従業員クラスと部門クラスのマッピングファイルから、Java ファイルと DDL を生成します。 hbm2ddl と hbm2java は、Ant をサポートしています。 自動生成のための build.xml をご覧ください。 また、自動生成された従業員クラスの Java ファイル employee.java と、 部門クラスの Java ファイル department.java、 それらの DDL ファイル schema-export.sql をご覧ください。
マッピング情報を準備した後にすべきことは、 SessionFactoryのための構成情報を設定することです。 構成情報には、データベースへの接続情報や使用するマッピングファイルの指定があります。
SessionFactory は、1 つのデータベースに対する構成情報を保持する更新不能でスレッドセーフなクラスです。SessionFactory は、Configuration クラスから生成されます。 もし、複数のデータベースを扱いたいのであれば、データベースそれぞれに対して Configuration と SessionFactory を生成する必要があります。 Configuration は SessionFactory を生成した後は捨てて構いません。SessionFactory の生成は、高価な処理であるため一度生成したら後は 全てのアプリケーションスレッドで共有するようにすべきです。このことについては、第 4 章で詳しく紹介します。
構成情報の設定方法には properties ファイルを用いる方法と、XML ファイルを用いる方法の 2 種類がありますが、 XML ファイルを用いる方がベターであると思います。 XML 形式では、以下のような properties 形式には不可能な設定を行うことができます。
- 1 つのファイルで複数の SessionFactory の構成を定義できる
- 使用するマッピングファイルを指定できる(properties ファイルではアプリケーションコード内でしか指定できない)
ただし、システムの規模が大きくなるとマッピングファイルの数も多くなりますし、 さらに複数の SessionFactory を 1 つのファイルで定義するとなると、ファイルサイズが非常に大きくなります。 そういう場合には、どちらにせよプロジェクトに合った構成情報の管理方法を考えなければならないでしょう。 ファイルの配置場所については、どちらの設定ファイルも CLASSPATH に配置しておくのが最も簡単ですが、 他の場所に配置することも可能です。
XML 形式の設定ファイル hibernate.cfg.xml をご覧ください。
<session-factory>
この中に SessionFactory の情報を記述していきます。 name="java:comp/env/hibernate/SessionFactory" というように name を指定すると JNDI バインドを行うことが可能です。connection.drivaer_class, url, username, password
JDBC ドライバ・クラス、JDBC URL、データベースユーザ、パスワードを指定します。 ここでは、データベースとして MySQL を使用しています。dialect
SQL 方言を指定します。SQL 方言とは、RDBMS 固有の SQL の拡張機能や、表現方法の違いといったものです。 Hibernate では、Oracle や DB2 といった商用製品から PostgreSQL や MySQL といったオープンソースまで多数の RDBMS をサポートしています。transaction.factory_class
トランザクション戦略を設定します。 デフォルトでは、データベーストランザクションを使用する net.sf.hibernate.transaction.JDBCTransactionFactory が指定されます。 JTA を使用したい場合は、net.sf.hibernate.transaction.JTATransactionFactory を指定します。 その場合は、transaction.manager_lookup_class に、 使用するアプリケーションサーバのTransactionManager クラスを指定します。 Hibernate は、JBoss、Weblogic、WebSphere 等多くのアプリケーションサーバをサポートしています。
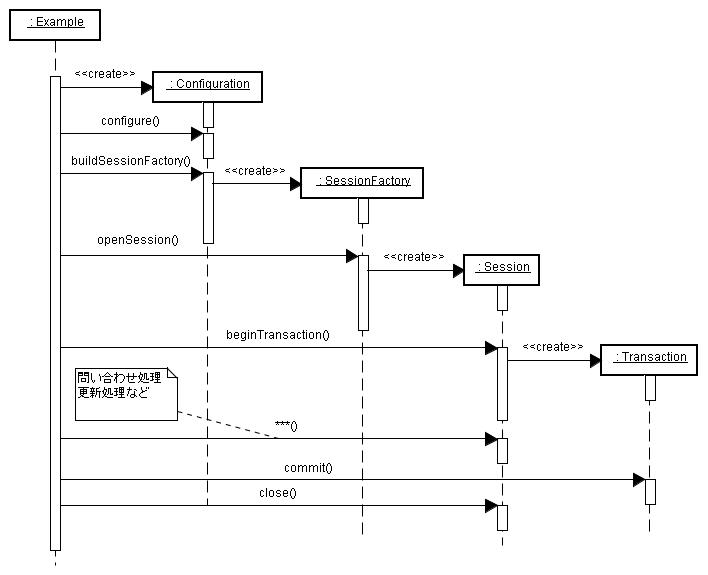
マッピングと構成情報の準備ができれば、アプリケーションコードを作成できます。 アプリケーションコードにおけるパーシステンスは、主に Session クラスを用いて実現します。 Sessionは JDBC コネクションをラッピングしたオブジェクトで、SessionFactory によって生成されます。 Session を中心とした、Hibernate を操作する流れは図3-3-1のようになります。
図3-3-1.シーケンス図:Hibernate による操作の流れ ここでは以下のことを行っています。
- Configuration を生成し、構成情報を取得する
- Configuration によって SessionFactory を生成する
- Session を開始する
- トランザクション制御が必要な場合 Transaction を開始する
- Session に対して、問い合わせや更新を依頼する
- Transaction を終了し、Session を閉じる
例として従業員クラスに対して、一連のパーシステンスを行う DAO を作成します。 ここでは、Hibernate 版の DAO とともに、JDBC 版の DAO もご紹介します。 両者を見比べることで、Hibernate がパーシステンスをいかに簡単にするのかを実感してください。
従業員 DAO の Hibernate 版 HibernateEmployeeDAO.java と、JDBC 版 JdbcEmployeeDAO.java をご覧ください。JDBC 版では SQL をコード内に記述してしまっているということを除いても、Hibernate 版の方がコーディング量が減少することが明らかです。それでは、メソッドごとに見ていきましょう。
get
ID を指定して従業員オブジェクトを取得しています。 Hibernate では、問い合わせに関しての機能が充実しています。 Session クラスが提供する問い合わせメソッドは以下のものです。
- get ・・・ID を指定して対象レコードを取得(見つからない場合に null を返す)
- load ・・・ID を指定して対象レコードを取得(見つからない場合に例外を返す)
- find ・・・HQL と ? クエリ・プレースホルダに指定する値を指定して、結果を List で返す
- iterate ・・・HQL と ? クエリ・プレースホルダに指定する値を指定して、結果を Iterator で返す
その他にも、復元したい行の最大数や復元したい最初の行を指定するといったことが可能な高機能のクエリ・インタフェースである net.sf.hibernate.Query や、 クエリ言語を一切使用せずオブジェクトの組合せのみによって検索を行う Criteria クエリが用意されています。 また、ネイティブの SQL を使用することも可能です。
また、Hibernate ではそれらの問い合わせ時にデータベースのロック機構を利用したロックを行うことができます。 もし、指定したロックモードが、使用している RDBMS でサポートされていない場合は、ロックは行われません。
getListByDepartmentName
ここでは、EMPLOYEE.hbm.xml で作成した外部定義の HQL を使用しています。 HQL の概観は SQL に非常に似ていますが、HQL は完全なオブジェクト指向のクエリ言語です。 SQL がデータベース側の視点でありテーブルに対するクエリであるのに対し、 HQL は Java 側の視点であり Java クラスに対するクエリです。 このような視点の違いから、HQL には SQL とは異なる部分、SQL にはない高度な機能がありますので注意してください。 特に注意すべき点は、SELECT 句、FROM 句、JOIN です。
SELECT 句
FROM 句で指定したクラスを取得したいだけであれば省略可能です。 また、例えば従業員名をチェックする NameChecker というクラスを用意すれば、SELECT new NameChecker(e.name) FROM entity.Employee AS eというように、検索結果としてオブジェクトを生成することもできます。 また、HQL は基本的に大文字、小文字を区別しませんが、 クラス名とそのプロパティに関しては区別する点も注意してください。FROM 句
FROM 句はポリモーフィズムをサポートしています。例えば、FROM java.lang.Object oというクエリを実行すると、java.lang.Object を継承しているクラス、 つまり全てのクラスに対して全件取得のクエリを実行したことになります。 これは非常に強力ですが、気をつけなければ意図しない結果を招くことになります。JOIN
HQL がサポートする JOIN は、INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN です。 ただし、あくまで Java クラスの関連での JOIN であることに注意してください。 EMPLOYEE.hbm.xml の クエリentity.Employee.getListByDepartmentName が JOIN できるのは、 マッピング情報で<many-to-one> の関連を指定しているからです。 そのため、SQL のような ON 句は必要ないのです。SQL との違いを意識しない機能
- 集約関数:AVG、MAX、MIN、SUM、COUNT、COUNT(ALL ...)、COUNT(DISTINCT ...)
- 式: 2 項演算子、BETWEEN、IN....
- ORDER BY 句、GROUP BY 句
- 副問い合わせ
insert, update, delete
登録、更新、削除に関しては、JDBC 版との差が特に出ています。 更新に関しては、JDBC 版との比較のためにも一応メソッドは作りましたが、 Hibernate 版は実際には何も処理を行っていません。
Session.update メソッドをコメントアウトしているのは、場合によってはこのメソッドを使用するからです。 それは、ここで渡された従業員オブジェクトが別の Session によって取得されたものである可能性がある場合です。 同一 Session 内であれば update メソッドを呼ぶ必要すらありません。
実際に Hibernate をプロジェクトで使用するときに役立つ手法をご紹介します。 特に、4-2, 4-3 においてはオープンソースの利点を活かし、コードの自動生成に関していくつかの機能を独自に追加しました。 拡張したツールは Hibernate-Extensions-Customize.zip です。
特に Web アプリケーションでは、SessionFactory を Singleton として全てのスレッドで共有する必要があります。 SessionFactory はスレッドセーフなクラスのため、スレッド間で共有しても問題は起きません。 それに対して、Session はスレッドセーフではないため、スレッドごとに生成するべきです。 このため、スレッド間で共有する SessionFactory を管理し、 スレッドごとの Session、Transaction を管理する必要があります。
Hibernate は、そのような管理機能は提供していません。 このような要件を満たし、SessionFactory、Session、Transaction を管理してくれるクラスの一例を作りました。 図 4-1-1 のクラス図と、図 4-1-2 のシーケンス図をご覧ください。
SessionManager はアプリケーション起動時に SessionFactory を生成します。 DAO では、現在のスレッドに対応するセッションを SessionManager から取得して、パーシステンスを行います。 またスレッドのメインクラスでは、トランザクション開始時に beginTransaction、 トランザクション終了時に commit、セッション終了時に closeSession を呼び出します。
SessionManager の実装例 SessionManager.java、 SessionManager を使用した Hibernate 版従業員 DAO HibernateEmployeeDAO.java を用意しました。 なお、ここでは簡略化するために static メソッドで実装しました。
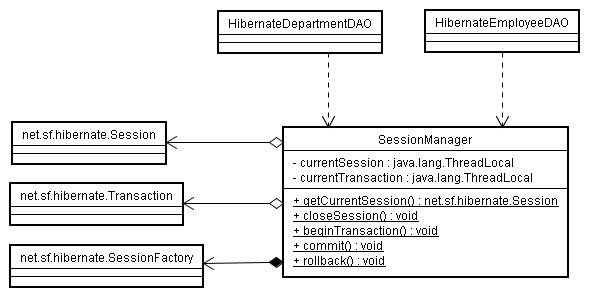 |
| 図4-1-1.SessionManager のクラス図 |
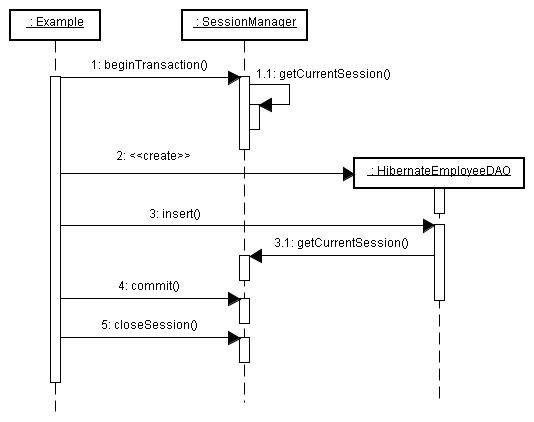 |
| 図4-1-2.SessionManager のシーケンス図 |
マッピングファイルから永続クラスのコードを自動生成することは、作業の効率面で非常に有効です。 自動生成されたクラスに何も手を加えず使う場合であれば、何の問題もありません。
例えば時給と労働時間をカラムとして持ち、 月給を計算するという導出項目を持つ、といった場合を考えてみましょう。 月給計算のメソッドは自動生成されないため、追加で実装しなければなりません。 開発中はテーブル定義が頻繁に変更されます。 変更のたびにコードを再生成することになりますが、 一般的なツールでは以前のコードは再生成後のコードによって上書きされてしまいます。 つまり、月給計算メソッドは消えてしまいます。
このような問題を避けるために、Generation Gap パターン [4] を使用できます。 このデザインパターンは、シンプルです。 自動生成されるコードを Base クラスとします。 実際に使用するのは Base クラスのサブクラスであり、 このクラスに対して拡張コードを実装していきます。
Generation Gap パターンを用いて、 従業員の給与を増減させる addSalary メソッドを追加した場合、 図4-2-1 のようになります。 アクセッサは省略していますが、BaseEmployee は自動生成されるフィールドを持ち、 それを継承する Employee が addSalary メソッドを持っています。
hbm2java は、Generation Gap パターンを適用するための機能がサポートされています。 この機能を使用するためには、そのための設定ファイルを準備する必要があります。 設定ファイルの例 generator-config.xml と、 また Generation Gap 版自動生成のための Ant の build ファイル build.xml をご覧ください。 設定ファイルでは<generate> によって 2 つの自動生成を行っています。 1 つ目の<generate> は、"Base" を接頭句とする Base クラスの生成を指定しています。 2 つ目の<generate>は、Base クラスを拡張する空のサブクラスの生成を指定しています。 再生成を行う場合は、1 つ目の<generate> だけを指定します。 生成された従業員クラス BaseEmployee.java と、 サブクラスに対してメソッドを追加した Employee.java をご覧ください。
hbm2java の機能には現場で利用するにあたって、問題となる点が 2 つあります。 まず、開発が進むに連れてテーブルが追加された場合です。追加分に関してはサブクラスも存在していないため、自動生成することになります。 その時に、既に存在しているサブクラスのファイルまで上書きされてしまいます。拡張したコードが上書きされてしまっては、Generation Gap パターンを使っている意味がなくなります。 かといって、別フォルダに出力し、手作業で追加分のファイルだけ移動させていくのでは自動化のメリットが薄れます。
もう 1 つは、コンストラクタの生成に関してです。 hbm2java は、default、full、minimal の 3 種類のコンストラクタを自動生成してくれます。 空のサブクラス生成に関しても、これらのコンストラクタだけは強制的に生成されます。 しかし、フィールドが増減した場合等には、またコンストラクタを作り直さなければならず、手間がかかります。
これらを防ぐために hbm2java を独自に拡張しました。 追加したのは、既存ファイルの上書き禁止機能と、コンストラクタの生成禁止機能です。 使い方は、以下のようになります。
- Hibernate Extensions の hibernate-tools.jar ファイルを拡張版 Hibernate-Extensions-Customize 内の hibernate-tools.jar と置き換える
- 既存ファイルの上書き禁止は、do-not-overwrite パラメータを true に設定
- コンストラクタの生成禁止は、 do-not-create-constructor を true に設定
使用例として設定ファイル generator-config.xml をご覧ください。
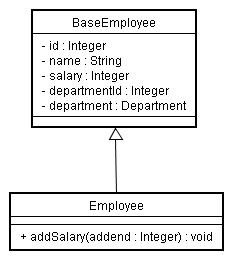 |
| 図4-2-1.Generation Gap パターンを用いた従業員クラス |
これまで紹介してきた例では、プリミティブ型の変数(int, shor, long, boolean等)に関しては、 ラッパークラスを使用してきました。 プリミティブ型をそのまま使用しなかったのは、NULL 値に対応するためです。 Hibernate では、プリミティブ型のフィールドに対応するレコードの値が NULL の場合にエラーとなります。
hbm2java によるコード生成においても、フィールドのプロパティに NOT-NULL="true" が設定されていない限り、 例えば type に int を指定しても、ラッパークラスの Integer が自動生成されます。 このこと自体は理に適っていまが、 実際のコーディングではプリミティブ型を使用したほうが実装が簡単な場合が多いのではないでしょうか。 個人的には setter メソッドに対して値をセットする時に、いちいちラッパークラスを生成するのは面倒だと思います。
そこで、ラッパークラスの setter メソッドが生成される場合に、 プリミティブ型の setter メソッドもオーバーロードして生成するように hbm2java を拡張しました。 使い方は、以下のようになります。
- Hibernate Extensions の hibernate-tools.jar ファイルを拡張版 Hibernate-Extensions-Customize 内の hibernate-tools.jar と置き換える
- overload-primitive-setter パラメータを true に設定
使用例として設定ファイル generator-config.xml をご覧ください。 また、生成された従業員クラス BaseEmployee.java をご覧ください。
本稿では、以下のことを解説しました。
Hibernate のメリット
Hibernate の基本的な使い方
実際に Hibernate を用いた従業員クラスの DAO を作成し、 それを基に実用的な Hibernate の使用方法について解説しました。 また、JDBC 版の DAO と比較することで、Hibernate の効果を強調しました。
Hibernate を現場で使う場合に役立つ拡張機能の紹介
逆に Hibernate を使用することのデメリットもないわけではありません。
Hibernate を使用するデメリット
また、パフォーマンスに関しても、注意が必要です。 例えば、many-to-one 等の関連を、レイジーローディング機能を使用せずに多用した場合、 不要な SQL が大量に発行されることになります。 Hibernate では、どんな SQL が発行されているかを確認する機能が提供されているので、 これを利用することでチューニングを行うことができます。 つまり、一般の開発者は永続層に関して今までよりも DB を意識せずに実装を行うことができるようになりますが、 RDBMS や Hibernate の内部の挙動を熟知し、使用上のガイドラインを決めたり、 チューニングを行ったりする開発者も必要とされるということです。
最後に言いたいことは、Hibernate が唯一の解ではない、ということです。 Hibernate は、現場で利用できるだけの性能と機能を持っています。 しかし、JDO や、EJB、またプロジェクト独自のフレームワークも、 プロジェクトで必要とされる条件によって最適の解になりえます。 本稿が、Hibernate をプロジェクトで使用するかどうかの判断材料となれば幸いです。
| © 2005 OGIS-RI Co., Ltd. |
|