WEBマガジン
「<オージス総研をとりまく>人工知能技術の過去と現在(4)」
2017.07.20 株式会社オージス総研 乾 昌弘
1.はじめに
(2)次に、長い歴史を持つ統計解析の一分野でもある機械学習の概要について述べます。この種の機械学習は、ビッグデータの時代を迎えて、ディープラーニングに先んじて注目されるようになりました。
(3)最後に、機械学習の一種でもあり、「教師あり学習」ディープラーニングの基になるニューラルネットワーク(Back Propagation)について説明します。
(4)図1に上記のキーワードの関係を示します。範囲が広いキーワードほど、定義も厳密さを欠く内容となってしまいます。
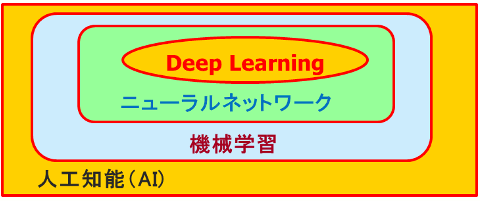
図1.キーワードの関係図
2.第2次AI冬の時代
(1)1995年頃~2010年頃を冬の時代とみなせば、この頃発展した技術は何だったのか。それはWindows95が普及のきっかけとなった、インターネットの世界であった。
(2)梅田望夫著「ウェブ進化論」では、インターネットの世界を「あちらの世界」と呼んだ。仮想コミュニティ「セカンドライフ」が話題となった。
(3)ハードウェアでは、パソコンから携帯電話、スマートフォーンに広がる
(4)Mushupなどインターネット独特の技術が生まれた。ASPを衣替えしたSaaSから○aaSという言葉が流行るようになった。
(5)Amazonが書籍のインターネット販売を始めた後、クラウド事業AWSに参入して、クラウドの時代を迎える。ビッグデータが話題になり、ディープラーニングへと繋がっていく。
3.従来の機械学習
3-1.機械学習とは、
(2)特定の目的に対する厳密なプログラムを用意しなくてもよい。
(3)機械学習の種類は多くありますが、ここでは典型的な3つの手法を紹介します。
3-2.回帰分析
(2)それぞれのデータと近似する直線(曲線)との目的変数の差の2乗和が最小になるように直線(曲線)を決めること(最小二乗法)。線形回帰の場合は、図2のようになる。
(3)図2右のような状態になってくると、回帰分析の意味がなくなってくる。一般的に決定係数という指標が用いられるが、決定係数が1に近いほど精度がよい近似となる。
(4)0~1の値の確率を求めたい場合は、ロジスティック回帰を用いる場合もある。
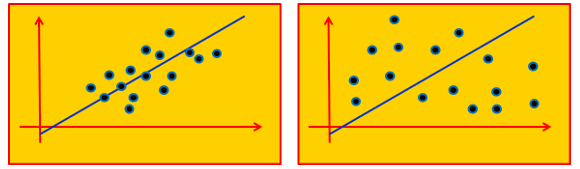
図2.線形回帰分析
3-3.クラスター分析(「参考文献」1)
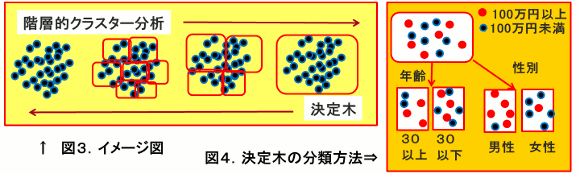
(2)階層的クラスター分析には、データ間の距離と取り方により(A)最短距離法 (B)最長距離法 (C)群平均法 (D)重心法 (E)ウォード法など がある。
(3)最短距離法の場合 (A)最短距離の2つのデータどうしをグループ化する (B)グループどうしのあるデータが最短距離のものをさらにグループ化する (C)一つのグループになるまで繰り返す。
(4)非階層的クラスター分析で代表的なものは、k-means法(k個のグループに分類する方法)である。
具体的には (A)各データをランダムにk個のグループに割り当てる (B)各グループの重心を計算する (C)各グループのデータを一番近い重心のグループに変更する (D)変化がなければ終了。そうでなければ(B)に戻り繰り返す。
3-4.決定木<Decision Tree>(「参考文献」1)
(2) いろいろな特徴を持ったデータのグループから不純度を減らすように分割。指標としてジニ係数を用いる。0~1の値をとり、低い値をとるように分類していく。
(3)例えば、販売額が100万円以上、100万円未満を分類したい場合、図4の例では不純度の少ない性別で分類する。
4.ニューラルネットワーク(Back Propagation)
4-1.Back Propagationについて
(2)ニューロ・ファジーで1980年代後半及び1990年代前半のブームの牽引となる。
(3)CNN (Convolutional Neural Network)のような前処理的な部分がないため、画像処理とともに入力層各ノードに特徴定義が必要になる。(ピクセルごとの値を入力にすることも可能である)
4-2.Back Propagation―仕組みの概要(詳細は「参考文献」2)
(2)まず、出力層j番目ノードの誤差指標Djは、主に(A) 出力層j番目の入力の総和 (B) 出力層j番目の出力値と正解の差、から求められる。次にDjとN層目i番目ノードの出力値から新たな(N層目i番目と出力層j番目との)リンクの重み付けWijを決定することができる。
(3)同様にK層目j番目のDjは、主に(A) K層目j番目の入力の総和 (B) K+1層目の各ノードのDとその2層間のリンクの重み付け、から求められる。そのDjとK-1層目i番目の出力値から同様に新たなリンクの重み付けWijを決定することができる。
(4)(3)を繰り返す。このように比較的実用的なアルゴリズムで実現できる。
(5)中間層のノード数が多すぎると過学習になり、少なすぎると充分学習しない。適切なノード数を試行錯誤で決める必要がある。
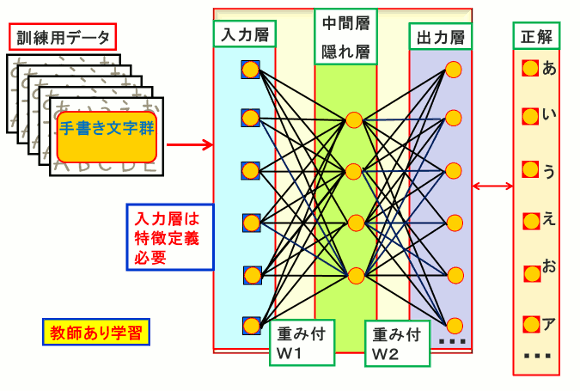
図5.ニューラルネットワーク(Back Propagation)の例
4-3.考察
(1)理論上は中間層が多層になっても学習ができるはずであるが、中間層(隠れ層)が多い場合、(活性化関数にシグモイド関数を用い)Back Propagationが前まで伝わらないという欠点もあり、中間層は1層~2層が中心であった。(2)この考え方は、改良されてディープラーニングに引き継がれていく。
5.オージス総研の状況
「参考文献」
| 1. | 秋光淳生「データ分析と知識発見」放送大学(番組プログラム)2012年 |
| 2. | 涌井良幸、涌井貞美著「ディープラーニングがわかる数学入門」技術評論社(2017年4月初版) |
| 3. | 河本薫著「会社を変える分析の力」講談社現代新書(2013年7月初版) |
| 4. | 乾昌弘「人工知能の概要と現状について」社内資料(2016年) |
(謝辞)私が2012年から3年半、データサイエンスセンター長を務めていた時、初代「データサイエンティスト・オブ・ザ・イヤー」を受賞された河本薫氏(元大阪ガス 現 滋賀大学データサイエンス学部教授)に多大なる御指導及び御支援をいただきました。それに対し感謝の意を表します。また、「参考文献」3は、仕事を進める上で大変参考になりました。
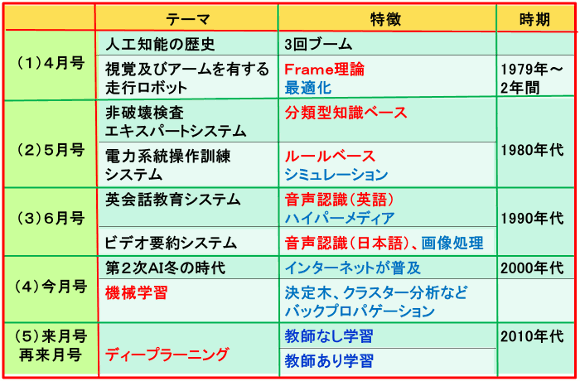
図6.掲載テーマ及び予定(御参考)
*本Webマガジンの内容は執筆者個人の見解に基づいており、株式会社オージス総研およびさくら情報システム株式会社、株式会社宇部情報システムのいずれの見解を示すものでもありません。
『WEBマガジン』に関しては下記よりお気軽にお問い合わせください。
同一テーマ 記事一覧
 「人工知能技術の過去と現在(最終回)」
「人工知能技術の過去と現在(最終回)」
2019.03.15 製造 株式会社オージス総研 乾 昌弘
「<Part 2>人工知能技術の過去と現在(5)」
2018.11.12 製造 株式会社オージス総研 乾 昌弘
「<Part 2>人工知能技術の過去と現在(4)」
2018.09.13 製造 株式会社オージス総研 乾 昌弘
「<Part 2>人工知能技術の過去と現在(3)」
2018.08.10 製造 株式会社オージス総研 乾 昌弘
<Part 2>人工知能技術の過去と現在(2)
2018.07.19 製造 株式会社オージス総研 乾 昌弘
「<Part 2>人工知能技術の過去と現在(1)」
2018.06.15 製造 株式会社オージス総研 乾 昌弘
「人工知能技術の過去と現在(下)」
2018.03.19 製造 株式会社オージス総研 乾 昌弘
「人工知能技術の過去と現在(上)」
2018.02.20 製造 株式会社オージス総研 乾 昌弘
「スマートグリッド社会成熟度モデルと人工知能」
2018.01.24 製造 株式会社オージス総研 乾 昌弘
「AIなどを通じて経験したGlobal Business」
2017.12.15 製造 株式会社オージス総研 乾 昌弘
「ビジネスを解析する手法とその比較(AI含めて)」
2017.11.17 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(7)」
2017.10.25 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(6)」
2017.09.15 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(5)」
2017.08.28 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(3)」
2017.06.19 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(2)」
2017.05.19 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(1)」
2017.04.17 製造 株式会社オージス総研 乾 昌弘