WEBマガジン
「<オージス総研をとりまく>人工知能技術の過去と現在(7)」
2017.10.25 株式会社オージス総研 乾 昌弘
1.はじめに
(2)ここでは、1対1対戦のゲームを取り上げます。(麻雀などは含まない)
(3)後半で、第3次AIブームの象徴的な存在である「α碁の戦略」の概要について述べます。
2.ゲームの理論(基本)
2-1.概要
(2)ゲームの世界は、ルールがはっきり決まっており相手も同じルールで、目標も同じなので、(強いプロフラムが書けるかは別として)取り扱いやすいテーマである。
(3)相手のルールも同じで繰り返してプレーするので、プログラム的には、図1のようにRecursive Callが基本である。

図1.ゲームプログラムの基本形
2-2.MiniMax
(2)数手先の状況について評価関数を使って正しく判断することが必要である。自分の手が最大値になり、相手も最大値(自分にとっては、最悪値)の手を打つと仮定して、自分の手を決める。この手法をMiniMaxと呼んでいる。
(3)さらに値によっては、他の分岐を調べなくてもよい場合があり、枝刈りができる。この方法をαβと呼んでいる。
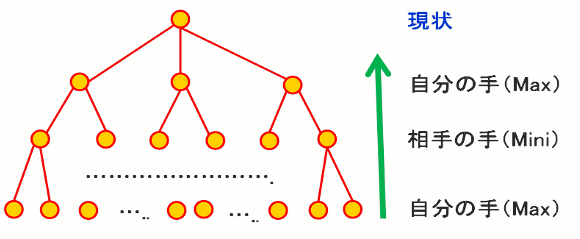
図2.ゲームの探索木
2-3.評価関数
(2)仮想的なパターンを想定するが、図3のようなパターンができた時に有利になると仮定する。評価関数は図3のように表される。
(3)コンピュータの最大の武器の一つはシミュレーションである。例えば、パラメータの違うもの通しを何回も自己対戦させて、勝率の良い方のパラメータを採用することも可能である。

図3.評価関数の例(仮想的なパターン)
3.α碁の戦略(「参考文献」1)
3-1.「教師あり学習」ディープラーニング
(2)局面を入力とするCNN(Convolutional Neural Network)で教師あり学習をした。
CNNは9月号を参照。
(3)出力は「(強い棋士による)次の各手の確率」である。これが次の入力(局面)になる。
3-2.強化学習
(2)「3-1」節のCNNを用いて自己対戦して勝敗を決める。(3000万データ使用)
3-3.モンテカルロ木探索
(2)ある手の試行回数の全体の試行回数に対する割合が小さく(バイアスが大きく)なれば、その手を試行してみる。
3-4.各手法の組み合わせ
(2)<バイアス+「3-1」節>の高い手を優先的に選択する。
(3)モンテカルロ木検索のよる結果の勝率及び、「3-2」節の結果による勝率の評価、の併用により勝率評価を改善する。
(4)「局面での勝率予測値」により、囲碁の世界で「2-3」節で述べた「評価関数」に対応する内容が作成されていることになる。
※詳細は、「参考文献」1を参照のこと。
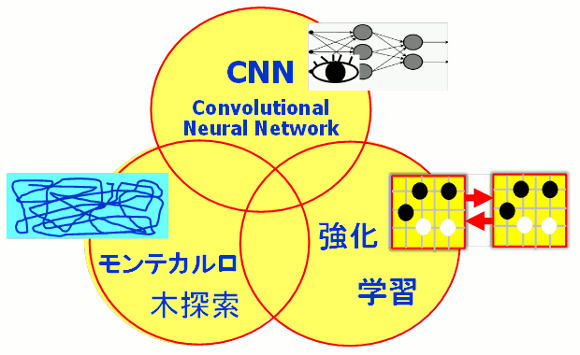
図4.α碁の「評価関数」作成手法
3-5.考察
(2)「計算力とデータ力の勝利!Brute Force AI」と言う人がいる。しかし、それだけではない深みのあるものとなっている。
(3)α碁の戦略は非常に複雑なようなであるが、次のように単純化すれば理解しやすい。 (A)序盤:「(強い棋士の16万局による)次の各手の確率」を主に使用 (B)中盤:「(3000万データで強化学習した)局面での勝率予測値」を主に使用 (C)終盤:「モンテカルロ木探索」を主に使用
「参考文献」
| 1. | 大槻知史著「最強囲碁AIアルファ碁解体新書」翔泳社(2017年7月) |
| 2. | 乾昌弘「人工知能の概要と現状について」社内資料(2016年)) |
図5.ゲームと人工知能(イメージ図)
「余談」
| 1. | 25年ほど前、ニューラルネットワークを教育システムに応用して、間違いの内容により自動的に次の問題を最適選択するアイデアで特許出願した。少しひねったアイデアであったので、弁理士が「どうやったら、このようなアイデアが出るのか理解できない」と言われたことがある。捻ったネットワークだったので、仕方がないと思うのだが。 |
| 2. | GoogleのソフトにTensor Flowと呼ばれるものがある。今から40年前、大学3年の時に「流体力学、熱力学、材料力学」を統合した「連続体力学」という授業を受けた。「連続体力学」の中心的な表現方法が「テンソル」。内容はもう忘却の彼方であるが、ベクトルやマトリックスを一般的に表現するもので、通常のシグマの表記は(下記)左側であるが、あまりにも変数が多いので共通の変数があると足し込むという右側のルールだったと思う。 |
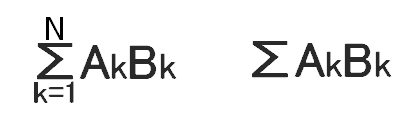
式. シグマの表記
表1.第1回~第7回の掲載のまとめ
*本Webマガジンの内容は執筆者個人の見解に基づいており、株式会社オージス総研およびさくら情報システム株式会社、株式会社宇部情報システムのいずれの見解を示すものでもありません。
『WEBマガジン』に関しては下記よりお気軽にお問い合わせください。
同一テーマ 記事一覧
 「人工知能技術の過去と現在(最終回)」
「人工知能技術の過去と現在(最終回)」
2019.03.15 製造 株式会社オージス総研 乾 昌弘
「<Part 2>人工知能技術の過去と現在(5)」
2018.11.12 製造 株式会社オージス総研 乾 昌弘
「<Part 2>人工知能技術の過去と現在(4)」
2018.09.13 製造 株式会社オージス総研 乾 昌弘
「<Part 2>人工知能技術の過去と現在(3)」
2018.08.10 製造 株式会社オージス総研 乾 昌弘
<Part 2>人工知能技術の過去と現在(2)
2018.07.19 製造 株式会社オージス総研 乾 昌弘
「<Part 2>人工知能技術の過去と現在(1)」
2018.06.15 製造 株式会社オージス総研 乾 昌弘
「人工知能技術の過去と現在(下)」
2018.03.19 製造 株式会社オージス総研 乾 昌弘
「人工知能技術の過去と現在(上)」
2018.02.20 製造 株式会社オージス総研 乾 昌弘
「スマートグリッド社会成熟度モデルと人工知能」
2018.01.24 製造 株式会社オージス総研 乾 昌弘
「AIなどを通じて経験したGlobal Business」
2017.12.15 製造 株式会社オージス総研 乾 昌弘
「ビジネスを解析する手法とその比較(AI含めて)」
2017.11.17 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(6)」
2017.09.15 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(5)」
2017.08.28 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(4)」
2017.07.20 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(3)」
2017.06.19 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(2)」
2017.05.19 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(1)」
2017.04.17 製造 株式会社オージス総研 乾 昌弘