 |
[2010 年 5 月号] |
|
[2010 年 5 月号] |
[レポート]
2010 年 4 月 19 日(月)〜 20 日(火)の2日間にかけて、東京ミッドタウン カンファレンスにて「 QCon Tokyo 2010 」が開催されました。この記事では、カンファレンス全体の様子と、筆者が参加したセッションの内容をレポートします。1日目は浅井、2日目は齋藤がレポートしています。
QCon は、技術情報サイト InfoQ 主催のカンファレンスです。InfoQ は海外では有名な技術情報サイトで、特定の技術・方法論に偏らず、Java 、.NET 、LL 言語から、アーキテクチャ、SOA /クラウド、アジャイル、RIA まで、あらゆる最先端の技術的話題が発信され、技術者同士のコミュニケーションの場になっています。QCon は現在のソフトウェア開発の最先端を担う著名スピーカーが数多く集まることで人気を博しています。また、こうした著名人同士の交流の場にもなっているようです。
QCon Tokyo は昨年に引き続き第2回目の開催となりました。
筆者らが、参加したセッションをご紹介いたします。
今回、全体を通して著者が感じたテーマは「クラウドコンピューティングを支える技術、開発手法」でした。1日目、2日目の key noteはそれぞれ twitter と facebook のスケーラリングに関するセッションであり、地球規模で展開される超大規模システムを支える分散キャッシュなどのスケーラリング技術に関心が集まっているのを感じました。また、もう1つのテーマとして、Scala や Groovy など『ポスト Java 言語』の話題が多くありました。それもただ言語の特徴を述べるだけでなく、実際にシステム構築に利用した際の知見を紹介しており、「ポスト Java 」の時代が近付いているように思います。
『GoF Design Patterns』の著者である Eric Gamma 氏と『Developing Enterprise Web Services - An Architect's Guide』の著者である Jim Webber 氏がアイスランド火山の噴火の影響により参加することができなくなってしまいました。Gammna 氏のデザインパターンに関するセッションや、Webber 氏のセッション「The Confusing Part of REST」は、ともに注目度大のセッションだったので、これらがキャンセルになってしまったことはとても残念でした。
Nick Kallen( Twitter システムエンジニア)
Java や .NET の開発者の間では知名度があまり高くないかもしれませんが、Kallen 氏は Ruby on Rails のデータアクセスフレームワークである ActiveRecord を拡張する named_scope 機能の実装や、arel、cache money といった数々の関連プロジェクトを手がけた経歴がある他、ScrewUnitという振る舞いベースで JavaScript の単体試験を記述するフレームワークの開発も行っています。このように、Ruby に関連する OSS 開発者の間では名前の通ったハッカーです。
今回の講演でも明らかにされましたが、ツイッターの基盤は最初は意外にも Ruby on Rails + MySQL というごく当たり前の Ruby ベースのWebアプリケーションのアーキテクチャからスタートしました。(当然、cache money など Kallen 氏作成の基盤も利用しているはずです。)しかし、ここ数年のツイッターの爆発的な利用人口の増大に対して、いかに高速なレスポンスやスループットを維持させるかという難しい技術課題を抱えています。このような背景を考えると、彼の経歴から Kallen 氏に白羽の矢が立ったのであろうことが容易に想像されます。
セッションでは
といったツイッターの基本機能を題材として、秒間数千を超えるスループットを維持しながらも、数ミリ秒のレスポンスタイムを実現するための手法として、
といったテクニックが紹介されました
詳しい講義の内容は講義資料とともに以下に詳しく解説されていますのでここでは割愛させていただきます。
https://www.atmarkit.co.jp/news/201004/19/twitter.html
これらのテクニックの一つ一つはどれもデータアクセスのチューニング手法としては一般的なものであり、なにか非常に特別なテクニックを期待して話を聴いているとちょっと拍子抜けするような内容だったのですが、天下り的に最初から与えられた特別なテクニック(あるいは製品)を銀の弾丸として問題を解決しようとするのではなく、既存の解法を状況に応じて組み合わせて一つ一つ確実に解決していくという姿勢はまさにエンジニアリングの原点であり我々も大いに見習うべきではないでしょうか。
今回の講演の中では明示的に紹介されることはありませんでしたが、Twitter 社では最近になって、MySQL をバックエンドとする分散グラフ DB である FlockDB、および、これらの DB に Web アプリケーションからアクセスするための中間レイヤを提供する基盤であるGizzardをオープンオースのフレームワークとして公開しています。(もちろん Kallen 氏はこれらのプロジェクトの中心的な開発メンバとして加わっています)。Gizzard は Web アプリと DB との間に介在し、sharding という考え方に基づいてデータアクセスを水平分散させるための基盤として使われます。
こららはまさにツイッターのビジネスを支える中心的な基盤となるところであり、それを惜しげもなくオープンソースとして公開してしまうというところは一般企業の常識から考えると驚くべきことなのですが、このような技術を OSS として公開することで早期に基盤の品質を高め、また、新しいアイデアを社外からも積極的に取り入れることで会社としてもメリットを得られるということでしょうか? Gizzard および sharding については Kallen 氏自身の以下の紹介記事を参照してください
https://engineering.twitter.com/2010/04/introducing-gizzard-framework-for.html
FlockDB も Gizzard も共に Scala 言語で構築されています。Kallen 氏自身、最近は Scala 言語に非常に関心を寄せているのか、夕方の BOF セッションでも真っ先に Scala の紹介コーナに足を運んでいました。JVM 上で動作する多数の軽量言語の中でも、静的な型付けを行う Scala は性能面で比較的有利と想定されますが、ツイッターのような極端な性能要件が求められる環境で、コア基盤の実装言語として実際に応用されているという点は非常に興味深い事実です。
森屋 英治氏(株式会社アークウェイ 代表取締役)
森屋英治氏は、元々マイクロソフトのプリンシパル コンサルタントとして勤めた後、2004年に独立企業し、現在は、.NET を基盤とするアプリケーション開発のコンサルティングをはじめ、アーキテクチャ策定、トレーニング サービスなどの手がける株式会社アークウェイを率いる代表取締役です。
.NET でコンサルティングと聞くとコーディングなどとは縁の薄い、仕事を想像しがちですが、同社では NAgile と呼ばれる.NET でのアジャイル開発の研究も行っており、「シンプルな設計を重視」「開発の無駄をなくす」「開発者の幸せの追求」など XP などでも重視される技術者よりの実践的な姿勢を大切にしているようです。
講演ではアーキテクトとしての森屋氏の思想が語られた後、現在研究開発中というソフトウェアファクトリーに基づく開発を支援する製品のデモが行われました。ソフトウェアファクトリーとはもともと 2004 年にマイクロソフトが提唱した考え方で、概要は以下に説明されています。
https://msdn.microsoft.com/ja-jp/library/cc947737
この考え方では、特定の業務ドメインのシステムに対して、「機能要求」「DB 設計」「SLA 設計」のようなさまざまなビューポイントから分析を行い、各工程における成果物とのマッピングを行うためのスキーマを定義しておきます。また、ドメイン固有のモデリング言語(DSL)や開発ツール、パターンなどをあらかじめテンプレートとして用意し、これを再利用することで同種のシステムがコーディングなしで効率的に生成できるとする考え方です。
ソフトウェアファクトリーの考え方自体は、現在のところ開発手法として主流になっているとはいえない状況ですが、筆者が思うにソフトウェアファクトリーだけでなく、一般的には OSS やクラウドの浸透も含めて、ソフトウェアのコモディティ化は確実に進んできています。業務システムの開発についても、少なくとも単純な CRUD を行うようなシステムであれば、基盤やモデルなど特別な設計やコーディングなしで開発を行うようなツールも提供されるようになってきています。
IT 企業は従来のビジネスモデルでは収益を上げにくくなってきているといわれており、「コモディティ化」はこの業界で一般的にはむしろ、危惧すべきものとしてマイナスのイメージで語られることが多いようにも思われます。講義タイトルが、かなり抽象的で広範囲な内容を示唆するものであり、限られた時間の中で講演者の主張が十分に伝わりにくかったきらいがありますが、ソフトウェア開発工程を標準化(コモディティ化)し、開発の無駄を徹底的に省いた先にイノベーションがあるということでしょうか? ソフトウェア技術者、アーキテクトとしては少し考えさせられる内容でした。
Patrick Peralta氏(Oracle Corporation Senior Software Engineer)
講演タイトルに「クラウド」という言葉がついていますが、講義中でも明確に否定されているように EC2 や Google Apps といった一般的なクラウドに関する技術や、オラクルのクラウド戦略についての話ではなく、分散 KVS(=Key Value Store)としてのオラクル Coherence の事例紹介、説明が中心のセッションでした。事例紹介では、ヨドバシドットコムにおける性能改善や楽天証券の株式売買システムにおける板情報配信システムが紹介されました。
講演者の Peralta 氏は、オラクル Coherence のスペシャリストとして Oracle Coherence 3.5 という書籍の共著者の一人でもあり、また、実際のシステム対するプロジェクト支援、顧客サポートを通して実業務での適用経験も豊富なエンジニアです。
オラクルでは従来から同社が提唱してきた Oracle RAD を利用したデータグリッドとは別に、Coherence を応用してミドルウェア層でデータを分散化するアプリケーショングリッドという考え方を推し進めています。Coherence をグローバルなクラウドの基盤として利用する際には、
などのポイントがあることが説明されました。パンフレットを読んだだけではそのように勘違いされてしまいそうですが、今のところ Coherence を導入すれば、魔法のようにクラウド環境上にスケーラブルな基盤が構築できるということではないようですので、実際にグローバルな環境での適用に当たっては注意が必要です。
講義では、ネットワークのレイテンシが無視できないグローバルなネットワーク上に分散した複数の Coherence のクラスタを連携させることで、アメリカとロンドンにまたがったオンラインオークション取引システムのデモが行われました。このデモでは Eventually Consistentいう考え方にしたがって、更新時の競合を解決する手段として、Push Publication というパターンが紹介されています。Coherence に関するいくつかのデザインパターンは以下のサイトでサンプルコードとともに紹介されています。
https://coherence.oracle.com/display/INCUBATOR/Projects
これらのパターンが十分に成熟し、もっと高いレイヤで Coherence を使った仕組みが提供されるようになってくれば別ですが、今のところクラウド環境における分散 KVS として利用することを考えたときに、他の OSS の KVS 製品や既存の Pass プロバイダの提供する仕組みに対して、オラクル Coherence がどのような優位性を持つのかが、残念ながら今回の講義の中からは今ひとつはっきりとは理解することができませんでした。
西脇 資哲氏(マイクロソフト株式会社 テクニカルソリューションエバンジェリスト)
講義の前半では、マイクロソフトが検索サービスとして提供している Bing 上で提供される(予定の)地図検索サービスなど先進的なサービスの取り組みのいくつかについて紹介が行われました。
マイクロソフト社というと、従来からの Windows や Office といった PC 上のソフトウェアを提供している会社というイメージがあまりにも強く、Google などと比較してどうしてもクラウドに関連するイメージが少ないところがあったので、かなり強烈な印象がありました。
講義の後半では、Paas プロバイダとしてマイクロソフトが提供している Windows Azure の紹介とそれに関するデモが行われました。デモでは、従来からあるExcel ベースのアプリケーションや SQL サーバを使ったソリューションを、ほとんどクリックやドラッグアンドドロップだけでそのままクラウド上に展開できるという Windows Azure の特徴が強調されていました。
昨年オラクルからの転職したばかりという西脇氏の経歴にもよりますが、既存の業務システムはやはりオフィスと SQL データベースを利用したシステムが圧倒的に多いのは事実であり、いくら KVS や BigTable などの新しい技術が注目されても、大部分の既存システムがいきなりこれらの新しいアーキテクチャに移行するわけでもありませんので、既存のソリューションからの移行の容易性を主張する同社の主張には説得力を感じました。
ただし、開発モデルに互換性があるといっても、これはあくまでも表面上のことであり、水面下では当然レスポンスなどの性能要件などの特性も違ってくるでしょうし、データの性質上、何でもクラウド上の DB に移行できるわけではありません。われわれ技術者としては、今後クラウドとオンプレミスとの賢い使い分けが必要であると考えられます。
一日目の午後の基調講演は Design Patten で有名な GoF のメンバの一人である Erich Gamma さんが講演を行う予定でしたが、ヨーロッパの火山噴火の影響により、残念ながら不参加となりました。代わりに、Douglas Crockford 氏が JavaScript について講義されることになりました。(筆者は参加していませんでしたが、JSON について講義されているので、2度目の登壇です)。
Crockford 氏は JSON 標準の発案者として知られるだけでなく、Java Script 言語の自他共に認める大家であり、まさに JavaScript の良い面も悪い面も知り尽くしていると言っていいような感じのする技術者です。
Crockford 氏が言うには JavaScript は「Web 開発でもっとも広く使われている人気のある言語」であると同時に「開発者にもっとも嫌われている言語」とのことです。
一見矛盾したことを主張しているようですが、
などの性質を考えると当然のことと納得ができます。
最近になって、JavaScript プログラマが従うべき心得をまとめたJavaScript The Good Parts - 「良いパーツ」によるベストプラクティスという本も著していますので、JavaScript を使って開発される方は一読されてみてはいかがでしょうか。
Java Script はその標準である ECMAScript4 の標準化が長いこと遅延したにもかかわらず、ベンダ間の意見の違いからまとまらず最終的に放棄されたという苦い歴史もありましたが、昨年末になってようやく ECMAScript5 としてまとめられました。(ECMAScript5 は Yahoo が主張していた ECMAScript3.1 をベースにしているため、当然 Crockford 氏の意向も色濃く反映されているものと想定されます)。
https://www.infoq.com/jp/news/2009/12/ecmascript5
また、Crockford 氏は、Web 標準はセキュリティの問題を解決することが大切であるという主張を強調しており、講義からは、まず第一歩として ECMAScript5/Strict を普及させていくという意気込みを感じました。そうした運動の妨げとなるからでしょう、大きな文字で「IE6 Must Die」と書かれたスライドを何度も繰り返し表示させていたところは非常に印象に残りました。
Pit Stop Cafe に会場を移し QCon のスピーカー陣が集まって、「The Future of Software Development」というタイトルについて議論するセッションを行いました。登壇スピーカーは以下の通りです。
ディスカッションの中では以下のような意見があがりました。
ハードウェアやネットワークの急激な進歩により、クラウドコンピューティングなどほんの数年前までは考えられなかったような新しいサービスが求められるようになってきているが、新時代の開発手法については今のところ模索中で、まだ画期的な答えが見出せていないといったところがパネラーの共通認識でしょうか?
| ページのトップへ戻る |
Facebook は現在世界で最も規模の大きい SNS に成長しました。分散メモリキャッシュサーバである memcache は膨大なアクセスを誇る Facebook の基盤となっています。このセッションでは Facebook インフラ(PHP、memcache、MySQL)の概要と、増えるづけるデータに対応する memcache システムについて様々なテクニックが紹介されました。
まず初めに Facebook のシステムがどのくらいの規模のデータを処理しているのか説明がありました。Facebook のユーザ数は約4億人です。Facebook の memcache では、get が秒間 4 億オペレーション、set が秒間 2800 万オペレーション、2 兆を超えるキャッシュアイテムと想像を絶する規模のトランザクション、データを扱っています
このセッションは最初に memcache 利用ルールを紹介し、そのルールを元に様々な工夫、テクニックを紹介していく形式で進んで行きました。なぜそのような工夫が必要になっているのかをアニメーション付きのスライドで説明されていました。詳細な内容については以下の講義資料に詳しく解説されていますので細部まで説明することは割愛させて頂きます。
これらのルールは Memcache+DB の構成をとる場合、最も基本的な考え方といえるでしょう。しかし、このルールだけでは増え続けるデータ、トランザクションに対応できなくなり、様々なテクニック、工夫が段階的に行われています。そのテクニック、工夫は以下の通りです。
オーバヘッドを解消するために、独自の PHP シリアライズを実装したり、PHP を C++ に変換する仕組みを作ってしまうところが流石です。
HotKey とは有名人のページにあるオブジェクトなど、通常のオブジェクトに比べて極端にアクセスが多いもののことです。この HotKey へのアクセスについて memcache ルール 1 をそのまま適用してしまうと、失敗した際、大量のクエリィが DB に発行されてしまいます。この HotKey への対応は次のような工夫が行われています。
Facebook では信頼性よりも新規性、独創性などの方が大事にされる傾向にあるみたいですが、さすがに基盤を支える memcache のプロジェクトは信頼性が重視されているようです。
twitter と同じように Facebook も初期は PHP+MySQL というどこにでもあるアーキテクチャから始まり、膨大なトラフィックに対応するために色々とその形態変えていっていることが印象的でした。スケーラリングのために PHP のシリアライズ、memcache を拡張し、そのフレームワークを OSS として公開している点も twitter と共通しています。これだけの規模の memcache の開発を5、6人(最初は2人)のチームで行っているというのが驚きでした。
Paul King氏(Top Groovy Committer, Co-author: Groovy In Action)
Groovy の第一人者によるテストについてのセッションです。前半は Groovy の言語についての話題で、後半がテストについての話でした。後半の話はテストツールと Groovy を活用することで効率的かつ効果的なテストを実施できるという内容です。
Groovy のエラーの例として紹介されていたのは以下のように途中の状態を表示してくれるメッセージで非常に分かりやすく、著者は Groovy に触れたことがないので是非触ってみようと思わせるものでした。
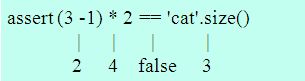
単体テスト(Unit Testing)、結合テスト(Integration Testing)、受入テスト(Acceptance Testing)のテストのフェーズの中で Groovy がどのように役に立つのか説明していました。特に受入テストについてツールと Groovy の Testing DSL の解説を交え、多くの時間を割いていました。詳細な内容は195 ページに及ぶ発表資料にぎっちり詰まっているので割愛いたします。(本当は2時間で話す内容らしいです)
https://qcontokyo.com/pdf/QCon_PaulKing.pdf
この講演資料の後半はテストツールとその活用方法のカタログになっているので非常に有用だと思います。短縮版のセッションで、比較的駆け足で話していたのでもう少し説明がほしい部分もありました。Paul King 氏は Groovy で記述できるTesting DSL の存在を強調していました。テスト自動化、柔軟なテストの記述を行うのに非常に有効だと感じました。
まつもと ゆきひろ氏(Ruby 作者)
書籍「ビューティフルコード」のエッセイ集の中でコードの美しさ自体に触れているのは実は1名(まつもと氏)。それでは「コードの美しさとはなんなのか?」という問いかけからスタートしました。
コードの美しさとはなんでしょうか。「ソフトウェアが何をやっているのかわかる」、「統一感がある」、「簡潔である」、色々思いつくかと思いますが、まつもと氏はコードの美しさは思想と表現によって決まる、と定義しています。思想と表現では、思想の方が大事。どんなに優れた表現でも、思想がよくなければ美しいコードとは言えません。
Rubyは「優れた表現」を意識して作られた言語で、その具体例として「変数のスコープと命名規約を言語レベルでサポート」、「ブロック」などを挙げていました。著者が最も心に残ったのは「信頼」と「自由」の思想です。
コードの美しさについての考え、優れた表現をするためのRubyの思想、そして「できない」は幻想、といったまつもと氏のメッセージこめられたセッションでした。今まで著者の頭の中ではぼんやりしていた「コードの美しさ」が、まつもと氏の言葉で少しくっきりしてきたのがよかったです。他のセッションのような最新技術についての話ではありませんが、プログラマ、ソフトウェア開発者としての考え方、心構えのようなものを改めて考えさせられました。
三木 隆史氏(株式会社パテントビューロ 研究・開発部 マネージャー)
「ポスト Java」言語として最近注目を集めている Scala とその Scala の Web フレームワーク Lift のお話です。「なぜ Scala なのか?」の問いに対する回答を実践の経験に基づく根拠によって示していました。
Twitter をはじめとし世界中で Scala での開発事例が増えてきています。各企業の導入理由をまとめると次のようになります。
Java の余分なところがない、Java のバイトコードになる、Java にはない便利な機能を搭載、これらの要素は Groovy(Paul King 氏のセッション)でもアピールされていました。これらが「ポスト Java」言語の共通要素になっているのでしょう。
Twitter のコアフレームワークで Scala が利用されているという事実は、Scala が高いポテンシャルを秘めているということを表していると思います。やはり静的型付けにより実行速度が速く、また並列実行できる点が Scala 利用の大きな理由になっていると思います。
講演者の事例によると Java から Scala へリプレースした場合、コード量(ロジック部分)が単純に3分の1になったそうです。
Lift は Rails のような画面からDBまでをサポートするフルスタックフレームワークです。Lift の哲学は「View First」。テンプレートにプログラミングロジックや特別な記号が入らない完全な XHTML としてデザインできるところが特徴です。他には次のような特徴を持っています。
Java プログラマが Scala の勉強を始めるとオブジェクト指向と関数型のミックスなので、どちらを使って良いか迷うことがあります。講演者の周りでは基本的にはオブジェクト指向で考え、関数型が適している部分を直していくというプログラミングスタイルで進めているそうです。また Lisp 使いなどは初めから関数型で作ってしまうみたいです。
Java と比べた時、次のことに留意する必要があります。
一般的な Java プログラマが Scala の勉強を始めると、
最後が?年後なのは、まだその域に達した Scala 使いを見たことがないからだそうです。学習コストの話は経験に基づいており非常に納得できる内容でした。著者が C から C++ へいったときと似ているなと感じました。
Michael Nygard 氏(Author, Release-It!)
講演者のNygard 氏はアプリケーション開発者/アーキテクトして 20 年以上のキャリアを持ち、書籍「Release It!」の著者として名が知られています。リリース後のシステムのトラブル対応の経験から、共通のアンチパターンを見いだし、そのアンチパターンにどう対応するのか、何をやってはいけないのか、をお話されていました。「障害は発生するものとして考える(Failure-Oriented Mindset)」は、とても心に響く言葉でした。
ネットワークや DB、または他のシステムとの連携ポイントは最も障害が発生する可能性が高い。
回避するには、
1つのコンポーネントの故障が他のコンポーネントの故障を引き起こす。
回避するには、
あるシステムの障害が呼び出し側システムを危険にさらす。
回避するには、
連鎖反応(Chain Reaction)と階層構造状に連続した障害(Cascading Failure)の違いは、連鎖反応はシステムの関係が並列になっているときのこと、階層構造状に連続した障害(Cascading Failure)はクライアントとサーバのようにことなる階層間の問題であると著者は理解しています。
悪意あるユーザ。予期しない大量のユーザ(主に B2C の Web システム)。
回避するには、
全てのスレッドがブロックされた状態になったら、それはユーザにとってはクラッシュされたのと同じ状態である。
回避するには、
マーケティングが大々的なキャンペーンを行うことでシステムを停止させてしまう。例えば、Xbox360 の値引きなど。
回避するには、
開発時、QA時、本番時で接続されるサーバ、アクセスの規模が違うことで本番時に予期しなかった問題が起こる。
回避するには、
あるシステムが耐えられるトラフィックであっても、そのシステムのバックエンドで動くシステムがそのトラフィックに耐えられるとは限らない。
回避するには、
あるシステムの SLA が、そのシステムが依存しているシステムのSLAより高い値を要求される。
回避するには、
無限の大きさのデータボリュームを定義できるが、リソースには限りがある。
回避するには、
|
| © 2010 オブジェクトの広場 |
|