UML 2 コンポーネント図の概要
by Scott
W. Ambler, Copyright 2003
コンポーネントベース開発(component-based development: CBD)とオブジェクト指向開発は一緒に使われるものであり、コンポーネントを構築するための基礎技術としてはオブジェクト技術が好んで使われることがよく知られています。私は通常、UMLコンポーネント図をアーキテクチャレベルの成果物として使います。これはビジネスソフトウェアアーキテクチャや技術ソフトウェアアーキテクチャのモデリングに使いますが、たいていはその両方です。物理アーキテクチャ、特にハードウェアの問題に関しては、UML配置図またはネットワーク図を使うとよいでしょう。実際私の場合は、これらの図を行き来して作業を進めます。
規模の大きなチームではコンポーネント図が特に有効です。サイクル0で行う最初のアーキテクチャモデリング作業では、システムのアーキテクチャがざっとどのようなものになるかを確認することに焦点を合わせます。このためにはUMLコンポーネント図が非常に役立ちます。コンポーネント図を使うことで大雑把なソフトウェアコンポーネントと、さらに重要なことに、そのコンポーネントのインターフェースをモデリングすることができるからです。インターフェースの定義が済み、チーム内で合意が得られれば、サブチーム間で開発作業を分担するのが容易になります。プロジェクトが進み、新しい要求が見つかったり設計が変更されたりすると、それをインターフェースに反映しなければなりませんが、その場合にはサブチーム間でどう変更するかを取り決め、それに応じて実装する必要があります。
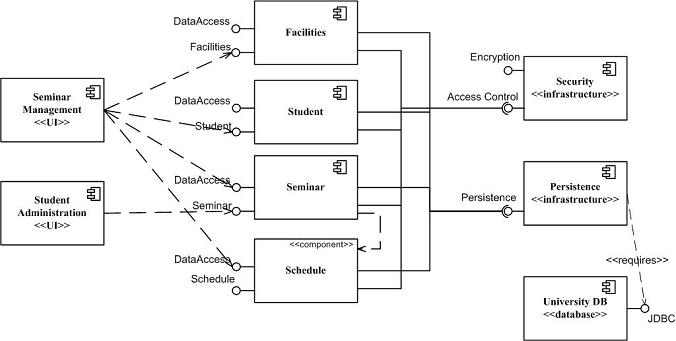
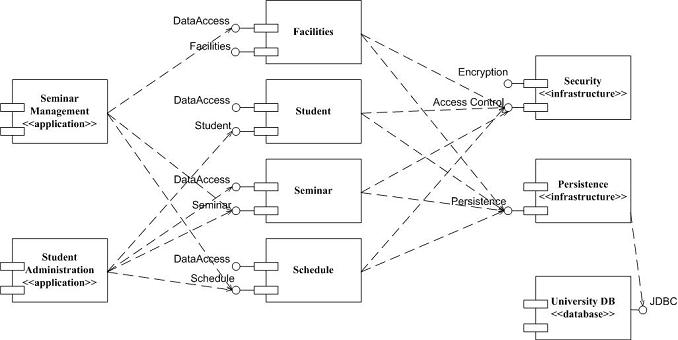
図1は大学システムのコンポーネントモデルの例です。UML2の表記法で書かれています。図2は同じ図をUML 1.xの表記法で書いたものです。この図を見ると分かるように、表記法がいくつか異なっています。UML2のコンポーネントは単純な長方形でモデリングされていますが、UML1.xのコンポーネントの長方形からは2つの小さな長方形が左側に突き出しています。UML1.xのこのシンボルは、UML2ではステレオタイプのアイコンとして長方形の中に置かれ、その長方形がコンポーネントであることを示します。アイコンではなく<<component>>というテキストでステレオタイプを表すこともできます(Scheduleコンポーネントを参照)。どちらの図でもコンポーネント間やコンポーネントとインターフェースとの間の依存関係がモデリングされています。また、どちらの図でもロリポップ(棒付きキャンディー)のシンボルで実装済みのインターフェースを表しますが、UML2では必須インターフェースを表すためにソケットのシンボルが導入されています。私は、このソケットのシンボルは事実上依存関係に付けるステレオタイプのアイコンだと考えています。これに対応するテキストのステレオタイプは、PersistenceコンポーネントとJDBCインターフェースとの間の依存関係に付けられている<<requires>>です。
図1. UML2.xのコンポーネント図
★==
Seminar Management:ゼミ管理
Studet Administration:学生管理
DataAccess:データアクセス
Facilities:施設
Student:学生
Seminar:ゼミ
Schedule:スケジュール
Encryption:暗号化
Access Control:アクセス制御
Security:セキュリティ
Persistence:永続性
University DB:大学DB
==★
図2. UML1.xのコンポーネント図
★==
訳語は、図1と同じ
==★
図1のような図は配線図(wiring diagrams)と呼ばれることもあります。さまざまなソフトウェアコンポーネントがどう配線で結ばれ、アプリケーション全体を構成しているかを示すからです。コンポーネント間を結ぶ線はコネクタとも呼ばれます。これには、コネクタ間で何らかのメッセージ処理が発生するという意味合いが含まれます。
私は通常、ホワイトボードにコンポーネント図を書きます。この2つの例で描画ツールを使ったのは、表記法を正確に示すためです。コンポーネント図は論理モデリングにも物理モデリングにも使うことができますが、私はたいていシステムのソフトウェアアーキテクチャの物理モデリングに使います。図1は大学システムのドメインコンポーネントを大雑把に表したもので、ユーザインターフェースコンポーネントが2つ含まれています。これらは全体的なシステムの一部として構築している2つの異なるアプリケーションに対応します。この図にはアーキテクチャのビジネス面と技術面が両方含まれています。<<infrastructure>>および<<database>>のステレオタイプが付いたコンポーネントは明らかに技術的な性質を持っていますが、それはまったく問題がありません。重要なのは、ここでアーキテクチャのビジネス面と技術面の両方を考慮していることであり、理由はともかく両方のビューを含む図を1つ作成することを選択したという点です。
コンポーネントはインターフェースを提供し、かつ利用します。インターフェースとは、1以上のメソッド、0以上の属性を集めて定義したもので、凝集性の高い一連の振る舞いを定義していれば申し分ありません。コンポーネントが提供するインターフェースはロリポップを使って、コンポーネントが必要とするインターフェースはソケットを使って表します。ポートとは分類子の機能で、分類子と環境との間のはっきりとした相互作用点 (interaction point)を仕様化するものです。ポートは分類子の側面に付けた小さな正方形として表記します。
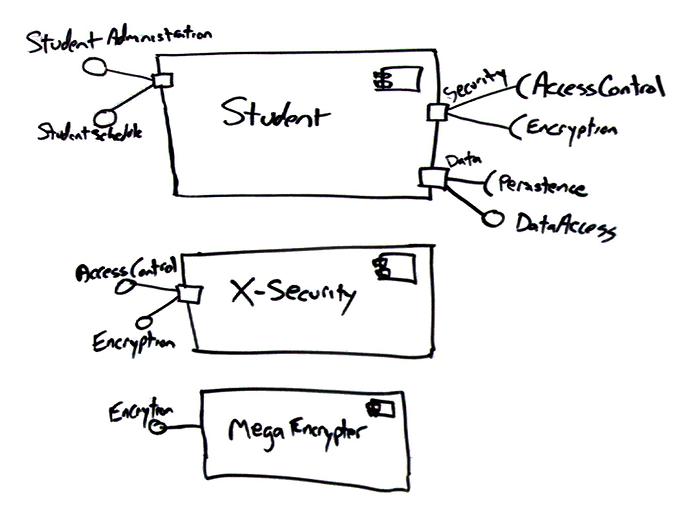
たとえば、図3に示すのは、3つのコンポーネントを含んだ詳細なコンポーネント図です。この図には興味深い特性がいくつか含まれています。
-
ポートには名前を付けることができます。StudentコンポーネントのSecurityやDataというポートがその例です。
-
ポートは単方向または双方向のコミュニケーションをサポートすることができます。Studentコンポーネントは3つのポートを実装していますが、2つは単方向であり、1つは双方向です。左側のポートは入力ポート、Securityポートは出力ポート、Dataポートは双方向のポートです。
-
StudentAdministrationおよびStudentScheduleのインターフェースは、アプリケーション固有のものであり、メソッドシグニチャが重複して含まれている可能性があります。この方法を取ると、各アプリケーションチームごとに不必要な邪魔なメソッドを含まないチーム独自のインターフェースを持つことができるため、クライアントがコンポーネントを理解しやすくなるようです。
-
この図はまだ「配線」されていません。Studentコンポーネントは2つのセキュリティコンポーネントにまだ結び付けられていません。
-
コンポーネントが提供するインターフェースをすべて使う必要はありません。私のチームでは、アクセス制御にX-Securityコンポーネントを、暗号化にMegaEncrypterコンポーネントを使うことにしました。このコンポーネントはどちらも、空想上の市販パッケージ(COTS)を購入したものです。X-SecurityはStudentに必要な両方のセキュリティインターフェースを実装していますが、MegaEncrypterの方がEncryptionインターフェースをずっと効率よく実装しているため、両方のセキュリティコンポーネントを使うことにしたわけです。
図3. インターフェースおよびポートのモデリング
★==
Studet Administration:学生管理
Student Schedule:学生スケジュール
Student:学生
Security:セキュリティ
Access Control:アクセス制御
Encryption:暗号化
Data:データ
Persistence:永続性
DataAccess:データアクセス
X-Security:X-セキュリティ
Mega Encrypter: メガ暗号化
==★
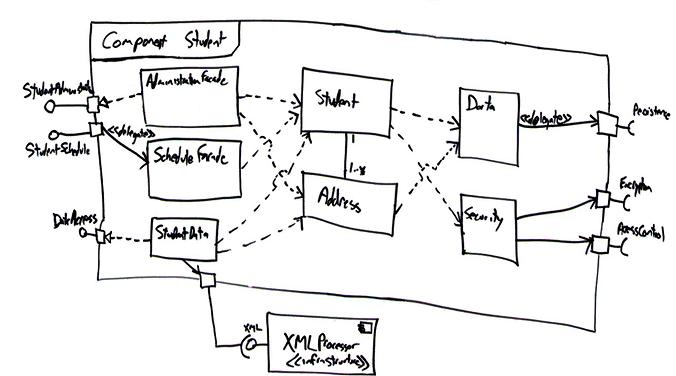
それでは、実際にコンポーネントを構築するにはどうすればよいでしょうか。その戦略にはさまざまなものがありますが、いくつか基本的な原則が存在します。図4はStudentコンポーネントの設計をUMLのフレームを使って表したものです(フレームではなくコンポーネントの表記を使う方法も一般的です。たとえば右上の角にコンポーネントのステレオタイプを付けた長方形で表すなどです)。この図で興味深いのは次の点です。
-
ポートが1つのインターフェースを提供あるいは要求するように単純化しました。こうすることで、コンポーネントのポートと内部との関係を簡単かつ明示的にモデリングすることができます。
-
ポートと内部クラスとの関係は3種類の関係でモデリングしました。ステレオタイプの付いた委譲関係、委譲関係、実現関係です。委譲関係は開いた矢じりの矢印で、実現関係は閉じた矢じりの破線の矢印で表します。委譲関係の表記法は、単方向の関連で使われている表記法とまったく同じなので、混乱が生じるかもしれません。そのため、関係にステレオタイプを付けて意味を明確に示すことを推奨します。私がこれまで実現関係(たとえばStudentAdministrationインターフェースを持つポートをAdministrationFacadeが実現するという関係)を好んで使っていたのは、ポートとは論理モデリングの構成要素であり、クラスなどの物理構成要素によって実現されるものだと考えていたからです。しかし、委譲関係には、コミュニケーションのフローを示すことができ、結果として理解しやすくなるという利点があります。
-
図4では、DataクラスおよびSecurityクラスは、それぞれ対応するポートと同じ名前になっています。
-
AdministrationFacade、ScheduleFacade、StudentData、Data、Securityといったクラスは、Façadeデザインパターン(Gamma et. al. 1995)を実装しています。基本的に、これらのクラスはインターフェースが要求するpublicの操作を実現したものであり、その操作は通常、メッセージを適切なクラスに委譲するだけです。AdministrationFacade、ScheduleFacade、StudentDataの3つのクラスは全体として、Studentコンポーネントのpublicのインターフェースを実装しています。StudentData、Data、Securityは、外部コンポーネントへのアクセスをラッピングし、内部クラスと他の物理コンポーネントとが直接に結び付かないようにするためのものです。
-
データ指向のメッセージからオブジェクト指向のメッセージへ、あるいはその逆に、入出力の相互作用を変換するつもりでいてください。たとえば、入ってくるメッセージはWebサービスとして実装されていて、パラメータとしてXMLを取り、結果としてXMLを返すものかもしれません。それに対して、コンポーネントの内部オブジェクトには、オブジェクトまたはデータをパラメータに取り、値を返すようなメッセージを送る必要があります。これはつまり、データとオブジェクトとを相互にマーシャリングする必要があるということです。ここではAdapterデザインパターン(Gamma et al., 1995)が使えるかもしれません。
-
publicインターフェースを実装するには、StudentComponentというFaçadeクラスを1つ実装するという方法もあります。このクラスは要求されているpublicのインターフェースを実装し、適切に委譲を行います。
-
StudentDataクラスの設計中に、既存のXMLProcessorコンポーネントを利用する必要があることが分かりました。そのためこのコンポーネントに対する接続を追加しました。
図4. コンポーネントの設計
★==
Component Student: 学生コンポーネント
Studet Administration:学生管理
Student Schedule:学生スケジュール
DataAccess:データアクセス
Administration Facade:管理ファサード
Student Facade:学生ファサード
Student Data:学生データ
Student:学生
Address:住所
Data:データ
Security:セキュリティ
Persistence:永続性
Encryption:暗号化
Access Control:アクセス制御
XML Processor: XMLプロセッサ
==★
図3によって、コンポーネントの構築にコストがかかることが明らかになります。図3に示すようにStudentコンポーネントを作成してもあまり意味はありません。2つのドメインクラスをサポートするために新しいクラスが5つも追加されていて、明らかに作り込みすぎです。このアプローチは、ドメインクラスが20ある場合には道理にかなっていますし、50もあるのなら非常に有効でしょう。クラスを5つ追加することでシステム内の結合度が低下し、同時に大規模で再利用可能なドメインコンポーネントを実装できるからです。重要なのは、余分にかかるコストを利点が上回る場合にのみ、コンポーネントベースのアプローチを採用するべきだということです。
コンポーネントモデルを作成するには基本的に2つの方法があります。トップダウンとボトムアップです。自分で選ぶことができるなら、私はトップダウンのアプローチを使います。ソフトウェアの全体像をプロジェクトの初期に明らかにするにはこのアプローチが適しているのがその理由ですが、これはチームが複数のサブチームから構成される場合には特に重要です。同じビジョンに向かって進むことができるからです。残念なことに、トップダウンのアプローチを取ると、アーキテクチャの過剰な作成が促進される傾向があり、結果としてシステムを必要以上に作りこみすぎることになります。たとえば、図1ではSecurityおよびPersistenceというコンポーネントが必要だとされていますが、それほど複雑なものはまるで必要ないかもしれません。利害関係者が実際に必要としているビジネス機能の実装をないがしろにして、この2つのコンポーネントの構築に注力するのは、大きな間違いです。
コンポーネントモデルを作成するもう1つの方法はボトムアップです。私がこの方法を使うのは、すでに開発されたクラス群がすでに存在し、設計をコンポーネント化することにした場合です。コンポーネント化を行うのは、たいてい、既存アプリケーションから再利用可能な機能を救出したり、サブチーム間に分散しやすいようアプリケーションを分割したりするためです。既存のオブジェクト設計をコンポーネント化するには、私はたいてい以下のステップを反復的に行います。
-
コンポーネントの凝集性を保つ 1つのコンポーネントでは、1つの関連する機能群を実装するべきです。1つのユーザアプリケーションのユーザインターフェースロジック、大規模なドメインの概念を構成するビジネスクラス群、共通インフラの概念を表現する技術クラス群などが考えられます。
-
ユーザインターフェースクラスをアプリケーションコンポーネントに割り当てる ユーザインターフェースクラスには、画面やページやレポートを実装するクラスや、どの画面/ページを表示するべきかを判断するといった「接着ロジック(glue logic)」を実装するクラスがあります。これらのクラスは、<<application>>というステレオタイプの付いたコンポーネント内に置きます。Javaの場合、この種のクラスには、Java Server Pages(JSP)や、サーブレットの他、Swingなどのユーザインターフェースクラスライブラリによって実装した画面クラスなどが含まれます。
-
技術クラスをインフラコンポーネントに割り当てる セキュリティ、永続性、ミドルウェアといったシステムレベルのサービスを実装する技術クラスは、<<infrastructure>>というステレオタイプの付いたコンポーネントに割り当てます。
-
クラスの契約 (class contracts) を定義する クラスの契約とは、他のオブジェクトから送られたメッセージに直接応答するメソッドのことです。たとえば、Seminarクラスの契約にはおそらく、enrollStudent()やdropStudent()といった操作が含まれます。コンポーネントを識別するという目的に関しては、クラスの契約ではない操作をすべて無視することができます。異なるコンポーネント間に分散したオブジェクト間のコミュニケーションに関係しないためです。
-
クラス階層を同じコンポーネントに割り当てる 私の経験では、九分九厘、階層中のすべてのクラスを同じコンポーネントに割り当てれば間違いありません。これは継承階層の場合でもコンポジション階層の場合でも同じです。
-
ドメインコンポーネントを識別する ドメインコンポーネントとは、互いに協力し、凝集性の高い取り決めをサポートするクラス群のことです。基本的に、クラスや他のドメインコンポーネントは、ドメインコンポーネントにメッセージを送って、情報を要求したり、アクションを実行するよう依頼したりすることができます。外から見るとドメインコンポーネントは単純で、実際に他の種類のオブジェクトと変わらないように見えます。しかし、たいてい内部的には、いくつものクラスの振る舞いがカプセル化されて非常に複雑なものになっています。ドメインコンポーネントの主な目的は、設計をいくつかのコンポーネントに整理することによって、コンポーネント間を流れる情報の量を減らすことです。メッセージの形態であれ、メッセージに対する結果として返されるオブジェクトであれ、コンポーネント間で情報がやりとりされれば、ネットワークにトラフィックが発生する可能性が生じます(コンポーネントが異なるノードに配置されている場合)。アプリケーションの応答時間を短縮するにはネットワークのトラフィックを最低限に抑えなければならないため、コンポーネント間ではなくコンポーネント内でほとんどの情報が流れるよう、ドメインコンポーネントを設計する必要があります。
-
ビジネスクラスの「コラボレーションタイプ」を識別する ビジネスクラスがどのドメインコンポーネントに属するかを判断するには、そのクラスが参加するコラボレーションを分析して分散タイプを判断する必要があります。サーバクラスはメッセージを受け取りますが、送ることはありません。クライアントクラスはメッセージを送りますが、受け取ることはありません。クライアント/サーバクラスはメッセージの送信と受信の両方を行います。各クラスの分散タイプを明らかにしたら、その後ドメインコンポーネントの識別に取り掛かることができます。
-
サーバクラスはサーバクラス用コンポーネントに含める 純粋なサーバクラスはドメインコンポーネントに属し、たいていは独自のドメインコンポーネントを構成します。というのも、これらのクラスはアプリケーション内のメッセージフローの「最終地点」だからです。
-
クライアントが1つだけならコンポーネントをマージする 1つのドメインコンポーネントに対してのみサーバの役割を果たしているドメインコンポーネントがあれば、その2つのコンポーネントを1つにまとめることができます。
-
純粋なクライアントクラスはドメインコンポーネントに属さない クライアントクラスはドメインコンポーネントに含めません。クライアントクラスはメッセージを生成するだけで受け取ることはありませんが、ドメインコンポーネントの目的はメッセージに応答することだからです。そのため、ドメインコンポーネントが提供する機能にクライアントクラスが寄与することはありません。おそらくクライアントクラスはアプリケーションコンポーネントに含めることになるでしょう。
-
結合度の高いクラスは同じコンポーネントに含める 2つのクラスが頻繁にコラボレーションを行っているなら、その2つのクラスを同じドメインコンポーネントに含めて、クラス間のネットワークトラフィックを減らすべきです。その相互作用に大きなオブジェクトが伴なっているなら特にそうです(パラメータとして渡す場合も返り値として受け取る場合も)。2つのクラスを同じドメインコンポーネントに含めることで、クラス間に発生するネットワークのトラフィックを減らすことができます。結合度の高いクラスは同じところに置くことが基本です。
-
コンポーネント間のメッセージフローのサイズを最小限にする クライアント/サーバクラスはドメインコンポーネントに含めますが、どのドメインコンポーネントに含めるかについては選ぶ余地があるかもしれません。その場合には、クラスを出たり入ったりする情報フローなどの問題について考える必要があります。コンポーネント内のコミュニケーションはたいてい、メモリ内のオブジェクト間で送られる単純なメッセージですが、コンポーネント間のコミュニケーションでは、メッセージやパラメータをデータに変換してから転送し、さらにもとのメッセージに戻すという、負荷の高いマーシャリング作業が必要になる可能性があります。
-
コンポーネント間の契約を定義する コンポーネントはそれぞれクライアントに対してサービスを提供します。そのサービスそれぞれがコンポーネントの契約です。
表1は、Agile Software Development(Martin, Newkirk, Koss 2003)で紹介されている、パッケージやコンポーネントの品質を高めるための設計原則をまとめたものです。これを取り上げたのは、コンポーネントモデリングを行う際に非常に役に立つと思うからです。
表1. コンポーネントの設計原則
|
原則 |
概要 |
|
依存を循環させない (Acyclic Dependencies) |
コンポーネント間の依存関係を循環させてはならない。たとえば、A→B→C→Aという依存は循環するため、認めてはならない。 |
|
共通性で閉じていること (Common Closure) |
同じコンポーネント内のクラスは同種の変更に対して全体として閉じていなければならい。ある変更がコンポーネント内の1つのクラスに影響したとしても、その変更がコンポーネント外のクラスに影響を及ぼしてはならない。言い換えると、複数のコンポーネントにまたがる変更が必要にならないよう、コンポーネント内の凝集性を高めておく必要がある。 |
|
一緒に再利用されること (Common reuse) |
コンポーネント内のクラスはまとめて再利用する。コンポーネント内の1つのクラスを再利用する場合には、すべてを再利用する。これも凝集性に関する原則である。 |
|
依存の逆転 (Dependency Inversion) |
抽象概念は詳細事項に依存してはならないが、詳細事項は抽象概念に依存するべきである。 |
|
開いているが、閉じられてもいる (Open-Closed) |
ソフトウェア要素は拡張に対して開いているが、変更には閉じられていなければならない。 |
|
リリースと再利用は同じ単位 (Release-Reuse Equivalency) |
再利用とリリースは同じ単位で行う。言い換えると、リリースしたソフトウェア要素の一部だけを再利用するべきではない。 |
|
安定した抽象化 (Stable Abstractions) |
コンポーネントは抽象的であり、かつ安定していなければならない。コンポーネントは、安定した状態のまま拡張できるよう、十分に抽象的でなければならない。 |
|
安定した依存関係 (Stable Dependencies) |
より安定したものに対して依存する。たとえば、コンポーネントAがコンポーネントBに依存する場合、AよりもBの方が安定しているべきである(変更の可能性が低いなど)。 |
アジャイルであり続けるには
私がコンポーネントモデルを使ってもっとも素晴らしい成功を収めたのは、あるチームと一緒に図1のような図を書いたときです。もちろん、その図はずっと大きなもので、20以上のコンポーネントを含み、ホワイトボードに書かれていました。このホワイトボードは、誰もが見えるようにチームの作業場所に置かれていました。私たちはこの図をプロジェクトの初期に作成し、プロジェクトを通して必要に応じて更新しました。ホワイトボード上に残しておいたのは、これが構築するソフトウェアのアーキテクチャを大雑把に表したものになっており、作業を進める上で随時使うことができたためでした。さらに重要だったのは、これによってシステム全体の設計に関する興味深い会話が行われたことです。
アジャイルを促進するコンポーネントにはいくつかの利点があります。まず、コンポーネントが再利用可能な部品となるため、それを組み合わせてソフトウェアを構築することができ、開発の生産性を高めることができます。さらに、コンポーネントによってテストの生産性が向上します。コンポーネントを要素として扱い、単体テストや統合テストをブラックボックス化できるためです。テストについて詳しくは、Full Lifecycle Object-Oriented Testing (FLOOT)に書かれています。
注: この成果物の説明は『The Object Primer 3rd Edition: Agile Modeling Driven Development with UML 2』より抜粋しました。本ではより詳しく説明しています。
-
UML Component Diagramming Guidelines
アジャイルモデリング(AM)について詳しく知るにはこの本をお薦めします。 
Ronin
International, Inc. continues to help numerous
organizations to learn about and hopefully adopt agile
techniques and philosophies. We offer both
consulting and
training offerings. In addition we
host several sites - Agile
Modeling, Agile
Database Techniques, UML
Modeling Style Guidelines, Enterprise
Unified Process (EUP) - that you may find of value. You
might find several of my books to be of interest,
including
The Object Primer, Agile
Modeling, The
Elements of UML Style, and Agile
Database Techniques. For more information please
contact Michael Vizdos at 866-AT-RONIN (U.S. number) or via e-mail (michael.vizdos@ronin-intl.com).
visits since June 8, 2004.
|