WEBマガジン
「論文紹介 A Recurrent Latent Variable Model for Sequential Data」
2017.11.17 株式会社オージス総研 鵜野 和也
はじめに
時系列データに対する異常検知に対し再帰ニューラルネットワーク(RNN)をどう適用するかを考えていたところ、時系列データのモデリングに関する面白そうな論文を見つけたので、重要なキーワードの説明も加えつつ簡単に説明したいと思います。
紹介する論文は" A Recurrent Latent Variable Model for Sequential Data"[1]です。少し前の論文になりますが、2~3年前から出てきた VAE の考え方を RNN に適用した VRNN を提唱しています。通常のRNNに比べて入力データの再現度に向上が見られるとのことなので、正常データの教師なし学習を用いた異常検知に応用できるのではないかと考えています。
従来、時系列データのモデリングには、隠れマルコフモデルやカルマンフィルターのような動的ベイジアンネットワーク(DBN)が用いられてきましたが、近年の深層学習の急速な発展に伴いRNNを用いた手法が見直されてきました。DBNで状態遷移や内部状態が比較的単純な構造に限定されるのに比べ、RNNでは複雑な状態や非線形な遷移の表現が可能であることがその理由になります。
ただし、DBNとは異なりRNNは基本的に決定論的な構造をしています。ここにVAEの変動性を加えることで、音声のような高度に構造化された系列データのモデリング能力を向上させようというのが紹介する論文の主旨になります。
論文は数式が中心でVRNNの構造や動きがイメージしにくいと感じたので、今回は、この論文を読み解く為に必要なキーワードについて簡単に説明しつつVRNNの構造や動作のイメージをお伝えしていきます。
紹介する論文は" A Recurrent Latent Variable Model for Sequential Data"[1]です。少し前の論文になりますが、2~3年前から出てきた VAE の考え方を RNN に適用した VRNN を提唱しています。通常のRNNに比べて入力データの再現度に向上が見られるとのことなので、正常データの教師なし学習を用いた異常検知に応用できるのではないかと考えています。
従来、時系列データのモデリングには、隠れマルコフモデルやカルマンフィルターのような動的ベイジアンネットワーク(DBN)が用いられてきましたが、近年の深層学習の急速な発展に伴いRNNを用いた手法が見直されてきました。DBNで状態遷移や内部状態が比較的単純な構造に限定されるのに比べ、RNNでは複雑な状態や非線形な遷移の表現が可能であることがその理由になります。
ただし、DBNとは異なりRNNは基本的に決定論的な構造をしています。ここにVAEの変動性を加えることで、音声のような高度に構造化された系列データのモデリング能力を向上させようというのが紹介する論文の主旨になります。
論文は数式が中心でVRNNの構造や動きがイメージしにくいと感じたので、今回は、この論文を読み解く為に必要なキーワードについて簡単に説明しつつVRNNの構造や動作のイメージをお伝えしていきます。
キーワード
VRNNの紹介に際して重要となるキーワードについて簡単に説明しておきます。
再帰ニューラルネットワーク
順序性のある系列データを処理する為に考案されたニューラルネットワークです。ネットワーク構造上、時刻 t-1 から時刻 t への再帰的な接続をもたせ、時刻間でネットワークのパラメータを共有することで、異なる長さの系列データへの対応が可能になっています。
現時点のデータと過去の経緯を合わせて入力とすることで、系列データに含まれるパターンを学習します。
再帰構造により RNN は自身が見てきた過去の経緯を認識できるようになるのですが、参照するべき過去と現在の距離が離れると、うまく経緯を認識できないという課題があります。どんどん新しい情報を入力することで過去の記憶が薄れていくイメージです。
現時点のデータと過去の経緯を合わせて入力とすることで、系列データに含まれるパターンを学習します。
再帰構造により RNN は自身が見てきた過去の経緯を認識できるようになるのですが、参照するべき過去と現在の距離が離れると、うまく経緯を認識できないという課題があります。どんどん新しい情報を入力することで過去の記憶が薄れていくイメージです。
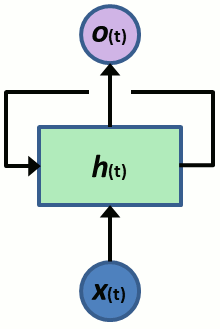
図 1 再帰ニューラルネットワーク
LSTM
前述の課題に対応する為、 LSTM と呼ばれるネットワークが考案されました。
LSTM ではセルと呼ばれる構造の中に状態を保持しており、この状態は時刻 t-1 から時刻 t へと伝播していきます。セル内にはゲートと呼ばれる構造があり、状態が伝播してく過程で、状態のどこをどの程度、忘れるべきか(forget gate)/新しい情報で更新するべきか(input gate)/出力するべきか(output gate)を掛け合わせつつ状態を更新していきます。
覚える、忘れる、思い出すという動作をとおして通常の RNN では対応できない長期の依存性を学習します。紹介する VRNN でも LSTM が採用されています。
LSTM ではセルと呼ばれる構造の中に状態を保持しており、この状態は時刻 t-1 から時刻 t へと伝播していきます。セル内にはゲートと呼ばれる構造があり、状態が伝播してく過程で、状態のどこをどの程度、忘れるべきか(forget gate)/新しい情報で更新するべきか(input gate)/出力するべきか(output gate)を掛け合わせつつ状態を更新していきます。
覚える、忘れる、思い出すという動作をとおして通常の RNN では対応できない長期の依存性を学習します。紹介する VRNN でも LSTM が採用されています。
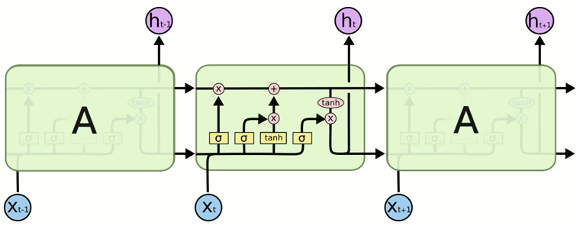
図 2 LSTM の構造
http://colah.github.io/posts/2015-08-Understanding-LSTMs/img/LSTM3-chain.png より引用
生成モデル
観測データが得られる確率分布を想定し、観測されたデータから想定した確率分布のパラメータを推定するモデルです。噛み砕いて表現すると「学習データと同じような新たなデータを生成するモデル」になります。
潜在変数
モデルに内在する直接観測できない変数です。例えば、顔写真であれば表情や向き、手書き文字であれば筆跡などの抽象度の高い概念をとらえたものだと考えてください。
Variational Auto Encoder
生成モデルの一種であり、バックプロパゲーション手法での最適化が可能な有効モデルです。観測可能な変数 x に対し、その特性を表現する潜在変数 z を導入します。q(z|x)、p(z)、p(x|z) はそれぞれがニューラルネットです。
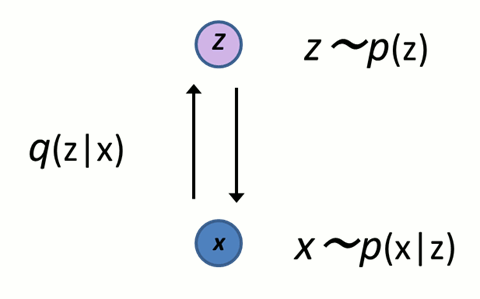
図 3 VAEの構造
データ生成時は、z の分布 p(z) から z をサンプリングし、分布 p(x|z)から x をサンプリングしてデータを生成します。
「で、そのp(z) はどうやって求めるのか?」という話ですが、直接 p(z) を得ることが難しいので、q(z|x) を導入し、p(z) の推定を q(z|x) と p(z) を近づける最適化の問題に置きかえて対応します。
学習時は学習データ x と q(z|x) から z を得て、p(x|z) から x を復元。この復元誤差を小さくしつつ、q(z|x) と p(z) を近づけるように動作させます。
VAE の詳しい解説はいろいろと公開されているので、参考のリンク[4]を参照して下さい。
「で、そのp(z) はどうやって求めるのか?」という話ですが、直接 p(z) を得ることが難しいので、q(z|x) を導入し、p(z) の推定を q(z|x) と p(z) を近づける最適化の問題に置きかえて対応します。
学習時は学習データ x と q(z|x) から z を得て、p(x|z) から x を復元。この復元誤差を小さくしつつ、q(z|x) と p(z) を近づけるように動作させます。
VAE の詳しい解説はいろいろと公開されているので、参考のリンク[4]を参照して下さい。
VRNN
ようやく本題のVRNNの話になりますが、RNN と VAE が押さえられていれば、どう組み合わせているかという話ですので、さほど難しくはありません。
系列データの生成モデルとしても、内部状態や状態遷移の表現力に勝る、誤差逆伝播法で訓練できるといった理由でRNN が利用されるようになってきました。
通常、RNNは決定論的な構造ですが、VAEの潜在変数の考え方を導入することで、音声のような高度に構造化されたデータへの対応性の向上が図られています。
また類似の手法としては STORN があるのですが、異なる時点の潜在変数の間(ztと zt-1)に依存性があることが相違点となっています。
系列データの生成モデルとしても、内部状態や状態遷移の表現力に勝る、誤差逆伝播法で訓練できるといった理由でRNN が利用されるようになってきました。
通常、RNNは決定論的な構造ですが、VAEの潜在変数の考え方を導入することで、音声のような高度に構造化されたデータへの対応性の向上が図られています。
また類似の手法としては STORN があるのですが、異なる時点の潜在変数の間(ztと zt-1)に依存性があることが相違点となっています。
基本構造
論文は数式だけで構造をイメージしにくいので、ソースコード[5]から構造図を書き起こしてみました。赤い部分がLSTMセルで緑の部分は通常の全結合層です。
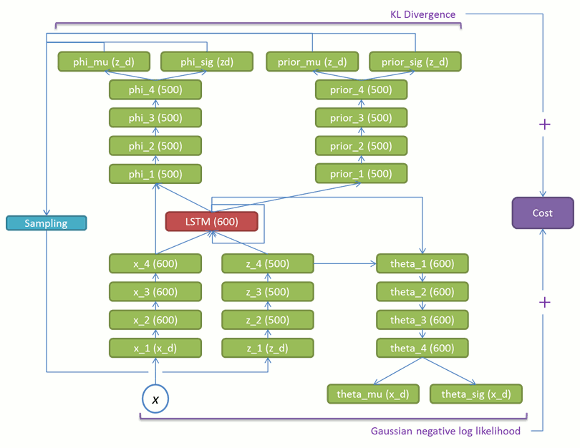
図 4 VRNNの構造図
赤いLSTMを中心に見ていくと分りやすいかと思います。基本的な構成要素は以下の通りになります。
(1) 入力 x と LSTM の内部状態から phi_mu/sig , prior_mu_sigを導出する部分(図5)。
(2) 潜在変数 z とLSTMの内部状態からtheta_mu/sig を導出する部分(学習時:図6、生成時:図9)。
(3) 入力 x、潜在変数 z とLSTMの前状態からLSTMの内部状態を更新する部分(学習時:図7、生成時:図10)。
(1) 入力 x と LSTM の内部状態から phi_mu/sig , prior_mu_sigを導出する部分(図5)。
(2) 潜在変数 z とLSTMの内部状態からtheta_mu/sig を導出する部分(学習時:図6、生成時:図9)。
(3) 入力 x、潜在変数 z とLSTMの前状態からLSTMの内部状態を更新する部分(学習時:図7、生成時:図10)。
コスト関数
コスト関数は以下のとおりです。見た目は少し複雑ですが、Σの中に着目して意味を考えてみましょう。
Σ内の左項はKLダイバージェンスと呼ばれるもので二つの分布の差異を図る尺度であり、右項は復元誤差になります。phi_mu/sigに相当するq(z|x) がx の潜在的な特徴を表現するようにしつつ(復元誤差の最小化)、prior_mu/sigに相当するp(z) が q(z|x) に近づいていくことで(KLダイバージェンスの最小化)、p(z) のサンプルから学習データの特徴を捉えたデータ生成ができるようになる訳です。
Σ内の左項はKLダイバージェンスと呼ばれるもので二つの分布の差異を図る尺度であり、右項は復元誤差になります。phi_mu/sigに相当するq(z|x) がx の潜在的な特徴を表現するようにしつつ(復元誤差の最小化)、prior_mu/sigに相当するp(z) が q(z|x) に近づいていくことで(KLダイバージェンスの最小化)、p(z) のサンプルから学習データの特徴を捉えたデータ生成ができるようになる訳です。
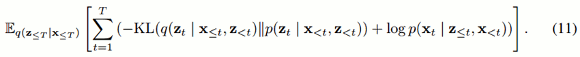
数式はhttps://arxiv.org/pdf/1506.02216.pdf から引用
図上ではphi_mu/sigからサンプリングする箇所で伝播が途切れますが、"Reparameterization trick"というテクニックで回避しています。検索すると出てくるので興味のある方は調べてみてください。
動作イメージ
学習時/生成時には以下のような流れで動作することになります。
学習時
(1) xt と ht-1 から φt、priort を出力。 φtと priort の KLダイバージェンスを導出します。
(2) φからサンプリングした zt と ht-1 から θt を出力。θt と xt の Gaussian negative log-likelihood を復元誤差とします。
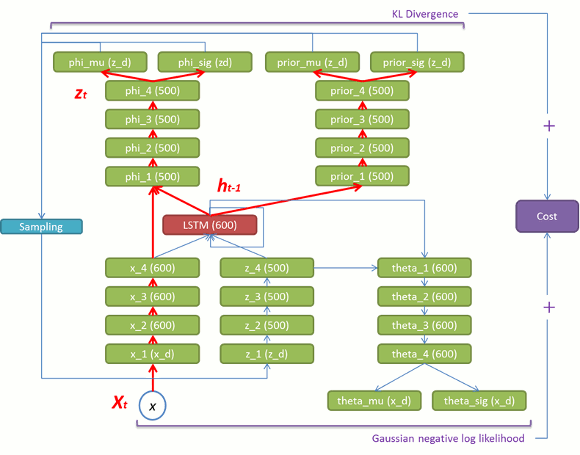
図 5
(2) φからサンプリングした zt と ht-1 から θt を出力。θt と xt の Gaussian negative log-likelihood を復元誤差とします。
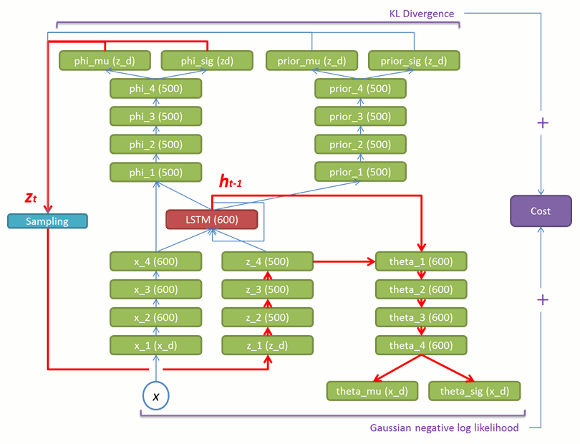
図 6
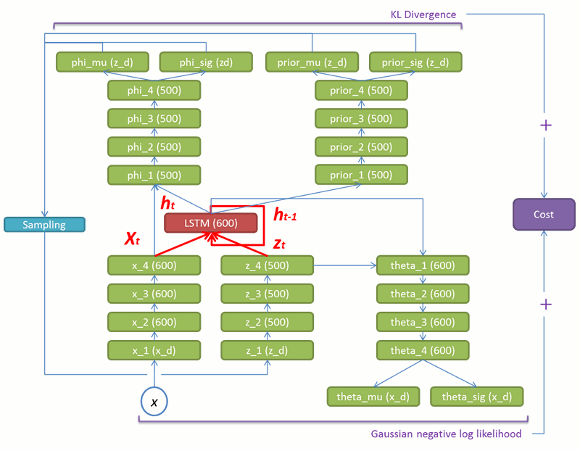
図 7
生成時
(1) ht-1 から priort を出力します。
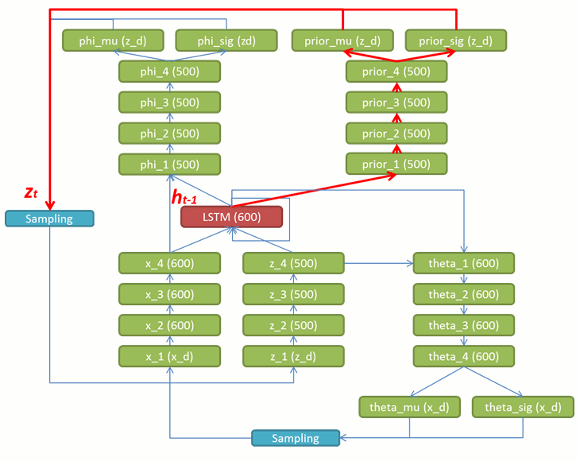
図 8
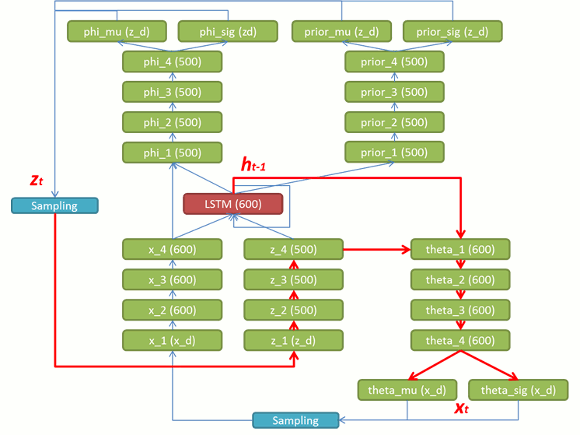
図 9
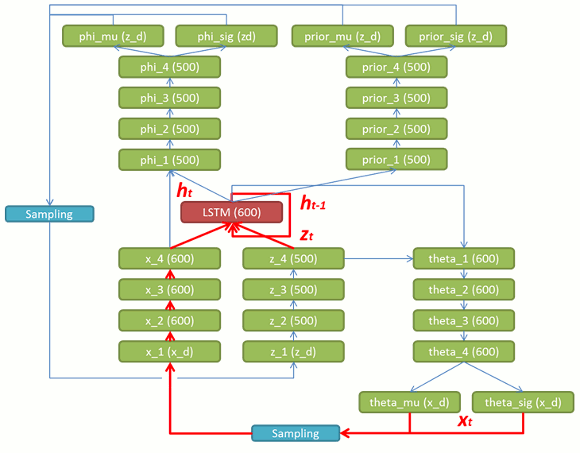
図 10
結果
最後にVRNNで生成した手書き文字のイメージを引用しておきます。潜在変数をもたない通常の RNN(右から二番目) に比べ、VRNN(右端)の出力は最初から最後まで筆跡の雰囲気がより安定していることが見て取れます

図 11 手書き文字生成の例
https://arxiv.org/pdf/1506.02216.pdfから引用
おわりに
という訳で簡単ではありますが、VRNN の紹介をさせてもらいました。Tensorflow で実装[6]した人もいるようなので、興味のある方は動かしてみてはいかがでしょう?
参考
| 1. | A Recurrent Latent Variable Model for Sequential Data https://arxiv.org/pdf/1506.02216.pdf |
| 2. | Understanding LSTM Network http://colah.github.io/posts/2015-08-Understanding-LSTMs |
| 3. | Deep Learning http://www.deeplearningbook.org/contents/generative_models.html |
| 4. | 猫でも分かるVariational AutoEncoder https://www.slideshare.net/ssusere55c63/variational-autoencoder-64515581 |
| 5. | nips2015_vrnn https://github.com/jych/nips2015_vrnn |
| 6. | tensorflow-vrnn https://github.com/phreeza/tensorflow-vrnn |
*本Webマガジンの内容は執筆者個人の見解に基づいており、株式会社オージス総研およびさくら情報システム株式会社、株式会社宇部情報システムのいずれの見解を示すものでもありません。
『WEBマガジン』に関しては下記よりお気軽にお問い合わせください。