
2016/10/15(土)に、主に自動運転車のセンシング技術に関するセミナーDenso A.I. Tech Seminar(株式会社デンソー主催)が開催されました。ディープラーニングによる画像認識、人間と自動運転車が混在する環境下での運転シーン理解の技術、ディープラーニングの演算を高速化・省メモリ化する技術など、自動運転車を実現する上で重要となる技術が紹介されました。本レポートでは、筆者が聴講した講演のうち、特に印象深かった講演を紹介します。
参加の動機
筆者は、普段、M2M/IoT分野向けのメッセージ配信基盤ソフトウェアの開発に従事しています。現在、同分野において、機器からのデータ収集とモニタリング、そして簡単な制御を伴うシステムの開発に取り組んでいる事例をよく目にします。今後、ネットワークに接続される機器が増大するにつれ、機器から生成される膨大なデータを機械学習などの手法で自動的に分析することで、人が介在せずにシステムの最適化を行う事例が増えていくと考えられます。その中の代表的な事例が、本セミナーのテーマになっている自動運転車です。筆者は、毎日のように自動運転車に関する情報をメディアで目にする機会がありますが、具体的にどのような技術開発が行われているかを把握する機会がありませんでした。今回は概要を把握する良い機会だと思い、セミナーに参加いたしました。
講演内容の紹介
ここでは、筆者が聴講した講演のうち、特に印象深かった講演を紹介します。
(招待講演)視覚の数理モデルを目指して - 構造つき予測とその先
講演者
講演内容
先日、ディープラーニングによって白黒写真に自動的に色付けを行う技術がメディア上で紹介されていたのをご存知でしょうか?本研究を行っているのが石川氏です。本講演では、自動色づけ技術で使われているディープラーニングおよび画像認識技術の概要と研究の背景が紹介されました。また、自動運転車の分野におけるディープラーニング適用の展望について紹介がありました。
石川氏が公開したディープラーニングによる白黒写真の自動色付けデモ
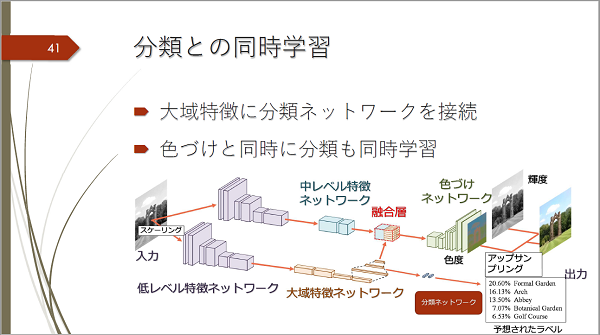
色付けネットワークモデル(石川氏の発表スライドより引用)
筆者は、石川氏の研究には以下のような特徴があると考えました。
- 入力画像の構造を維持したまま出力を行っている。
- 従来の分類アルゴリズムでは、最終的に入力画像の構造は失われ、単に画像に写っている内容の分類結果のみ出力していた。
- 近年、盛んに研究されている Semantic Segmentation、Depth Prediction という手法を活用することで、入力の構造を維持したまま出力まで行っている。石川氏の研究の例で言えば、画像に写っている人や自然風景を分類し、その形を残したまま分類結果に適した色をつけている。元の構造がないと色づけが難しい写真もあり、結果として分類・色づけの精度向上に寄与している。
- 石川氏はこのように構造を維持する問題分野を「構造つき予測問題」と呼んでいる。
- 役割の異なる複数のニューラルネットワーク(以降、ネットワークと略す)を部分的に組み合わせてディープラーニングを構成している。
- 局所的な特徴を捉えるネットワーク、大局的な特徴を捉えるネットワークを組み合わせることで、局所的な特徴だけでは判別しづらい画像の特徴を捉えて、画像の分類を行っている。
- 画像に写っている対象物のカテゴリを分類するネットワークと画像に色付けを行うネットワークを接続して色付けと分類を同時に学習し、色付け時には対象物の分類情報を活用することで高い精度を実現している。
石川氏によると、上記の特徴にある「構造を把握する」や「局所的な特徴と大局的な特徴の両方を見る」という方法は、元々は人間の認知の仕組みをヒントに実現された手法とのことでした。人類は、進化の過程で、生存を脅かす危機を効率的に察知するため、視覚から捉えた情報から効率的にその特徴を捉える能力を獲得してきたそうです。その能力獲得で重要なのが高次元の構造(繰り返しや階層構造など)に着目することだそうです。画像認識の場合、入力データの大半がノイズ(見つけたい対象ではないもの)であり、細部に着目すると、入力画像の部分と見つけたいパターンとの組み合わせ数が爆発してしまうため、この高次元に着目する点が効率的に分類を行う上で重要なのだそうです。
上記の研究の医療分野への応用もすでに試みられているそうです。例として、三次元のCT画像による動脈と静脈を自動判別する技術において、同技術を適用すると誤判定の割合が低下し、判定精度が向上する結果が得られたそうです。
今後の研究の展望としては、以下が紹介されました。
- 同研究ではディープラーニングによるネットワーク同士の結合は人手で行っている。ディープラーニングで重み付けが自動化されたのと同じように、ネットワークの構造自体もアルゴリズムによる学習によって自動作成できる可能性がある。
- 画像認識でよく使われるCNN(Convolutional Neural Network)は画像構造に密着した手法である。そのため、画像以外の何らかの構造を持つデータに対して、構造を意識したディープニューラルネットワークを構築するという考え方を適用するには、その対象物の構造を表現できるネットワーク構造と学習アルゴリズムを個別に検討する必要がある。
所感
本講演で紹介された以下は、初めて知った考え方だったため、ディープラーニングの分野の動向について把握できた点は良かったと思います。
- 入力の構造を残したまま学習を行う。
- それぞれ役割を持ったネットワーク同士を組み合わせた大きなネットワークを構成して学習を行う。
石川氏が指摘するように、ディープラーニングを適用する分野が拡大するにつれて、今後は自動運転車といったシステムが1つの大きなニューラルネットワークになっていき、そのネットワーク構造のアーキテクチャを設計する機会が増えるかもしれません。ただし、ネットワーク構造自体も学習対象になるとのことで、ネットワークを組むこと自体に人間が関与することは徐々に減っていくのかもしれません。創造性を生かして、こういう技術を使っていく場面を考えることがエンジニアの仕事になるのではないでしょうか?
参考
- 講演資料「視覚の数理モデルを目指して - 構造つき予測とその先」(PDF)
- Satoshi Iizuka, Edgar Simo-Serra, Hiroshi Ishikawa, “Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification”, SIGGRAPH 2016
機械学習による運転挙動解析とその応用
講演者
坂東 誉司氏(DENSO International America, Inc., Silicon Valley Innovation Center, Manager)
講演内容
本講演では、自動運転車と人間が運転する車が共存している環境において、周辺のドライバ(人間)の運転シーンがどのように遷移していくか予測し、適切な運転挙動について意志決定を行う方法について紹介がありました。
完全に自動運転車しかいない環境では、自動車およびその周辺にあるセンサから情報を得たり、車同士の通信で調整を行うことで衝突リスクを減らしたりすることが可能です。しかし、自動運転車と人間が運転する車が共存している場合、自動運転車の側が周囲の人間がどのように運転するか、一定程度の時間軸の範囲で予測する必要があります。例えるなら、機械に人間の空気を読む能力を求めるような状況が発生します。
一方、従来、ADAS(先進運転支援システム)において、衝突リスクをTTC(Time to collision; 衝突余裕時間)という物理モデルのみで定量化できる指標がよく使われてきました。TTCは、前方車両との車間距離を速度の差(相対速度)で割った数値です。TTCは短期的な予測では使えますが、周囲の状況の変化も含めて判断する必要がある長期的な予測には向いていない指標でした。
そこで、坂東氏が研究されている手法では、自動車に設置されているセンサから熟練ドライバの運転挙動のデータ(アクセスやブレーキの踏み込み具合など)を取り、隠れマルコフモデルという手法で離散状態に分割し、状態間の遷移を確率的に予測するという方法を取っています。例えば、車が走っているある状態を{a1,b1,c1,d1}という状態だと表現し(このa1やb1は自動車がセンサ群で取得できるデータに対応)、確率αで{a2,b2,c2,d2}に遷移するというように捉えます。
このような確率分布のある状態遷移モデルにおいて、自然言語処理の分野の技術(トピックモデルなど)を用いて、シーンの移り変わりを予測できるようになるそうです。ここで、現実的な時間の範囲でシーン遷移を予測するため、予測範囲を制限する手法がとられているそうです。例えば、周囲の車や歩行者は、起こりうる確率が高いであろう行動を継続するという想定で、確率が低いであろうシーンの予測は省略します。ただし、周囲のドライバが予想に反するような運転を取った場合、自動車運転がその振る舞いを予測できずに、衝突事故になる事例も報告されているそうです。
最後に、自動運転車のアルゴリズム開発の難しさおよび取り組む上でのヒントや、今後の展望などについて紹介がありました。
- 実機を使ってのアルゴリズムの検証が難しい。
- 検証したいシーンが現実的には再現しにくい場合、運転挙動データを再現し、シミュレーション環境で検証を行う。
- 一方で、UdacityというEラーニングのサービスが自動運転車の開発に関するコースを開講し、その一環で運転挙動データを公開し始めた。このようにデータを一般に公開し、コミュニティで共有する動きが加速すれば、各社の研究開発もやりやすくなるだろうとのこと。
- 自動車とクラウドのハイブリッドな情報処理の範囲が拡大する。
- 自動運転車の制御においては、衝突回避に必要な判断は自動車内で判断する必要がある。一方、判断する内容によっては、ある程度のレイテンシが許されるようなもの、必ずしも自動車内で完結する必要がないものもあり、クラウドに情報を送り、クラウド側で処理する事も行われる。
- 今後も、自動車とクラウドが分担して情報処理する範囲が増えていき、役割分担やその実現の仕組みを考える機会が増えていく。
所感
自動運転車における運転シーンの予測は、状況がどんどん流れていく中でシーンを予測するため、静的な状況で画像の分類を行うのと比較すると、非常に難しい問題に取り組んでいることが良く分かりました。また、運転シーンの予測において、車の運転とは一見関係なさそうな分野である自然言語処理で確立された手法が応用されているという点も驚きました。一見無関係な問題であっても抽象化すれば同じ構造の問題になるという例だと思いますが、研究者の発想の柔軟さや着眼点のよさに驚かされます。
後半で紹介された自動車とクラウドのハイブリッドな情報処理は、世間的にはエッジ(あるいはフォグ)コンピューティングと呼ばれている分野です。今後、レイテンシなどの問題により、機器側で機械学習モデルを使った推定などの処理を行う機会は増えていくであろうと感じました。
参考
物体認識の高速化・省メモリ化のための整数基底分解法~線型モデルから深層学習まで~
講演者
安倍 満氏(株式会社デンソー アイティーラボラトリ 研究開発グループ リサーチャ)
講演内容
安倍氏の講演は、ディープニューラルネットワークによる画像認識で多用される行列の内積演算に対して整数基底分解法と呼ばれる手法を適用し、メモリ圧縮率と計算速度が大幅に改善したというものです。
従来、車載カメラにおける画像認識(歩行者や対向車の検出など)は、輝度勾配ヒストグラム(HOG)と線形サポート・ベクター・マシン(SVM)という手法を組み合わせて行っていたようですが、この手法は認識対象や認識精度に限界があったそうです。そこで認識精度改善のため、ディープニューラルネットワークによる画像認識を取り入れたそうです。しかし、ディープニューラルネットワークは畳み込み層の演算処理(特に内積演算)に膨大な時間がかかる制約があったそうです。
これまでは、認識精度を犠牲にして高速化したり、ハードウェアやアルゴリズムを改善したりするなど、実装レベルで様々な工夫をこらしてきたそうです。しかし、実装レベルでの改善は限界があると気づき、問題を根本的に見直して解決しようとしたことが表題にある「整数基底分解法」につながったそうです。
この整数基底分解法とは、ディープニューラルネットワークの重みにあたる大きな実数ベクトルを、小さな実数ベクトルと大きな2値または3値の整数行列に近似し、処理しやすい論理演算に変換するというものです。(補足:これは行列の固有値ベクトルを求めるのと非常に似ているとのこと) この手法を画像認識のテストで良く使われているImageNetのテストデータに適用したところ、エラー率増加は1.43%にとどまり、メモリ圧縮率が1/20、計算速度が15倍に改善したとのことでした。
所感
ディープラーニングというと、AlphaGoのようにクラウド環境でGPUクラスタを組んで、膨大な計算を行う事例を耳にします。しかし、一方、自動車は省リソースな組み込み環境であり、車載カメラによる物体認識では非常にリアルタイム性の高い処理を行う必要があります。
今後、IoTの分野で機械学習が適用されていくと、学習モデルを作る開発環境と、学習モデルを使って推定を行うプロダクション環境が全く違うということは往々にしてあり、その差をうめる設計を組み込みソフトウェアのエンジニアが考える機会が増えると感じました。
参考
- 日経コンピュータ, “デンソー、ディープニューラルネットワーク処理を15倍高速化”
- 黒川 貴都、山内 悠祠、安倍 満、山下 隆義、藤吉 弘垣、"行列分解と早期棄却による他クラス物体検出の高速化"、Vol.2015-CVIM-195 No.2(PDF)
全体を通しての所感
自動運転車およびその周辺領域で研究開発を行っている第一人者が発表されており、今、リアルタイムでどのような研究がなされているのか把握する上で貴重なイベントとなりました。本イベントを開催・運営してくださった株式会社デンソーの皆様には深く感謝を申し上げます。
本イベントで講演を聴講する中で、自分が自動運転車においてどの領域に貢献できるかを考えていました。坂東氏の講演の中で、自動車とクラウドで役割分担を行いながら、ハイブリッドな情報処理を行う分野が拡大するという話は、私が自分のチームで開発を行っているメッセージ配信基盤ソフトウェアが応用できそうな領域であり、その点が発見できたことはよかったと思います。自動車とクラウドでどのように役割分担が行われるのか、今後も技術動向をウォッチし、普段の技術開発にも生かして行きたいと思います。