
今回の記事では、COSMIC法の基本概念である利用者機能要件、機能プロセス、データグループ、注目オブジェクト、ピアシステムについて説明します。これらの基本概念を理解すれば、COSMIC法で機能規模をどのように測定するかがほぼ理解できるでしょう。
利用者機能要件
利用者機能要件 ( FUR: Functional User Requirement ) とは、利用者の視点でソフトウェアの機能のまとまりを捉えたものです。ソフトウェアの機能規模を測定する第 1 歩としては、まず「ソフトウェアを構成する機能を識別する」ことが必要になります。ソフトウェアを構成する機能が分かれば、機能毎の機能規模の測定を行い、それらの機能毎の規模の総和としてソフトウェアの機能規模を求めることができます。
利用者機能要件を識別する際に大事なことは、あくまでユーザの視点でソフトウェアの機能を捉えるということです。別の言葉でいえば、ユーザと「ソフトウェアに望むこと」を話し合うレベルの機能 - つまり「要件」もしくは「要求」- を捉えるということです。利用者機能要件としては、基本的には「機能要求」を考え、性能、可用性などの「非機能要求」は考えません。
オブジェクトの広場の読者のみなさんは UML のユースケースをよくご存じだと思いますが、ユースケースは利用者機能要件とみなすことができます。ただ、ワープロや表計算などユーザとの相互作用が複雑な汎用のソフトウェアでは、ユースケースという単位で機能を表現しづらいことがあります。そのような場合には、特定のメニュー、機能の種類などで類似した機能要求の集合を考えて、そのまとまりを単位に利用者機能要件を設定してもよいでしょう。要は、利用者機能要件は常にユースケースである必要はないということです。この点については、本連載の後の記事で説明する予定です。
利用者機能要件を理解するために、住所録ソフトウェアを例として考えてみましょう。住所録ソフトウェアは「住所を新規登録する」や「住所を削除する」などの機能(ユースケース)を提供します。これらの機能が利用者機能要件となります。
COSMIC 法では、測定対象のシステムの利用者(ユーザ)や、測定対象のシステムを利用する外部システムのことを「機能利用者」と呼びます。ユースケースとアクターの関係と同様に、利用者機能要件は特定の「機能利用者」が行いたいことを単位にして定義することが推奨されています。
では、利用者機能要件はどこから見つけたらよいでしょうか。まず、要件(要求)を説明する文書から見つけることができます。例えば、ユースケース定義書(記述)や画面定義書です。これらがあれば、利用者機能要件は非常に楽に抽出できます。それ以外に、実システムを調べたり、マニュアルを読んで利用者機能要件を識別することもできます。これは要求ドキュメントが残っていない既存システムの利用者機能要件を見つける際に使える方法です。
機能プロセスとデータ移動
機能プロセスとは、外界からの刺激に基づいて実行されるソフトウェアの機能です。機能プロセスは、利用者機能要件の一部であり、必ず「複数種類」のデータ移動が続けて実行されるものでなければなりません。ここで述べているデータ移動とは、前回の記事で言及したように COSMIC 法の測定対象となる以下の 4 種類のものです。
| データ移動の種類 | 説明 |
|---|---|
| エントリー ( Entry ) | システムの境界からユーザインタフェース ( UI ) や通信を通じて入力されることに対応するデータ移動 |
| エクジット ( eXit ) | UI や通信によりシステムの境界に出力されることに対応するデータ移動 |
| リード( Read ) | 永続ストレージから読みだされるデータ |
| ライト( Write ) | 永続ストレージに対して書き込まれるデータ |
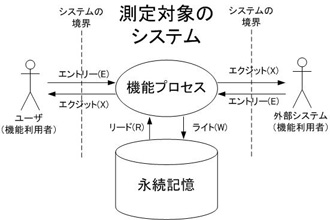
「COSMIC機能規模測定法 ver3.0 手法概要編」の図を引用
ここで続けて実行される複数種類の「データ移動」で機能規模を測るというのがミソです。上記の 4 種類のデータ移動の中で、機能プロセスにエントリーは 1 つ以上ある必要があります。それに加えて、残りの種類のデータ移動が実行されれば機能プロセスになります。
複数のデータ移動が続けて実行された場合、これらのデータ移動の間にはなんらかの「データ処理」が存在します。複数種類の「データ移動」を数えることは、実はデータ移動の間で実行される「データ処理」の複雑さを間接的に測っていることになるのです。
利用者機能要件として住所録ソフトウェアの「住所を新規登録する」ユースケースを考えてみましょう。このユースケースの記述が「ユーザが住所を画面から入力し、その住所をデータベースに保存する」だとします。すると、「住所を画面から入力し」の部分でエントリーが発生し、「その住所をデータベースに保存する」という部分でライトが発生します。 1 つのエントリーに加えて、ライト 1 つが続けて発生するのでこれは機能プロセスの条件を満たします。つまり、「住所を新規登録する」は「利用者機能要件である」とともに、「機能プロセス」でもあるのです。また、「住所を新規登録する」機能プロセスの機能規模はエントリー 1 、ライト 1 で合計 2 CFP になります。
この例では、利用者機能要件と機能プロセスを区別する意味がないように感じるかもしれません。しかし、一般的には「利用者機能要件」は複数の「機能プロセス」から構成されます。「住所を新規登録する」という利用者機能要件については、「郵便番号を選択する」などの機能が含まれる可能性がありますが、それらの機能は「住所を新規登録する」とは別の機能プロセスになります。
バッチ処理の場合は、バッチ処理を起動するトリガーをエントリーとして数え、 1 つのバッチ処理が 1 つの機能プロセスになります。
データグループと注目オブジェクト
前節では 4 種類のデータ移動があることを説明しましたが、移動するデータの粒度(大きさ)については説明しませんでした。COSMIC 法では、複数のデータのまとまりを単位にデータ移動をカウントします。そのような複数のデータのまとまりを「データグループ」と呼びます。また、永続ストレージに格納される正規化されたデータを「注目オブジェクト」と呼びます。「データグループ」は、「注目オブジェクト」の一部であることが多いとされています。
再び住所録ソフトウェアの例で考えてみましょう。住所録ソフトウェアでは、以下のような住所データを画面から入力するとします。この画面を「住所入力」画面と呼びます。
- 氏名(漢字)
- 氏名(ふりがな)
- 郵便番号
- 都道府県名
- 市区町村名
- 番地
- 電話番号
- 電子メールアドレス
これらのデータは 1 つのデータグループとなります。このデータグループを仮に「住所データ」と呼ぶとしましょう。このデータグループは、永続ストレージ(データベース)には「住所」という注目オブジェクトとして保存されることになります。この例では「住所データ」と「住所」を構成するデータは同じになりますが、これはやや特殊なケースになります。
「データグループ」によっては、永続ストレージ上に「注目オブジェクト」として存在しない場合もあります。例えば、複数のデータグループの値の合計など演算結果として得られるデータです。
住所録ソフトウェアの例で考えてみましょう。住所録ソフトウェアに「住所の一覧と住所の合計数を表示する」という利用者機能要件があったとしましょう。この利用者機能要件には、この機能を開始するきっかけを与えるエントリーが 1 つ、「住所」に対するリードが 1 つ、「住所データ」を表示するためのエクジットが 1 つというデータ移動があることが分かります。さらに、「住所の合計数」は複数の住所を数えて得られるデータグループなので、「住所の合計数」を表示するためのエクジットが 1 つ存在することになります。
前の例で、住所データが一覧表示されるのに「エクジットが 1 つ」とカウントしたり、住所に対する「リードが 1 つ」という点に気付きましたでしょうか?これは、COSMIC 法でのデータ移動は「インスタンス」の数ではなく、「データの種類」を数えるからです。この点は、非常に大事なので覚えておきましょう。
データモデルを考える際に「マスターデータ」と「トランザクションデータ」を区別することがよくあります。しかし、COSMIC 法では「マスターデータ」と「トランザクションデータ」を区別せず、両方とも「注目オブジェクト」として取り扱います。
例えば、住所録ソフトウェアに「都道府県と市区町村を選択し、郵便番号を選択する」という利用者機能要件があったとします。この利用者機能要件を「郵便番号選択」画面と呼びます。この機能に対する要求が以下のようなものだったとします。
- システムは画面上で「都道府県名」の一覧を表示する
- ユーザが「都道府県」を選択する
- システムは、選択された都道府県に存在する「市区町村名」の一覧を表示する
- ユーザが「市区町村」を選択する
- システムは、「郵便番号」を「町や番地名」とともに一覧表示する
- ユーザが「郵便番号」を選択する
- システムは、選択された「都道府県」、「市区町村」、「郵便番号」、「町や番地名」を「住所入力」画面に追加する
このような場合には、まずエントリーを起点とした 4 つの機能プロセスに分解します。
- 「都道府県名」の一覧を表示する
- 選択された「都道府県」に存在する「市区町村名」の一覧を表示する
- 選択された「市区町村名」に関連する郵便番号、町や番地名を一覧表示する
- 選択された「郵便番号」、「町や番地名」を「住所入力」画面に追加する
この機能プロセスに登場する注目オブジェクトのモデルとしては、図 2 に示すようなものが考えられます。
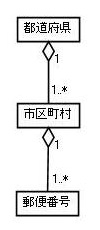
Aの機能プロセスの機能規模は、きっかけとなるエントリーが 1 つ、「都道府県」に対するリードが 1 つ、「都道府県データ」を画面に一覧表示するエクジットが 1 つの合計 3 CFPになります。なお、B, Cの機能プロセスは、前に実行された機能プロセスでの選択結果がエントリーとなり、各々「市町村」と「郵便番号」に対するリードとライトが 1 つずつ発生するので各々 3 CFPの機能規模になります。また、Dの機能プロセスでは、ユーザが選択した「郵便番号データ」をエントリーとし、それを「住所入力」画面にエクジットするので、合計 2 CFPの機能規模になります。
ここで「きっかけとなるエントリー」で移動するデータグループは何だろうと疑問を持たれた方もいらっしゃると思います。エントリーについては、機能プロセスを起動させるだけで実際に移動するデータグループがないものも許されています。筆者は、このようなエントリーを「トリガーだけのエントリー」と呼んでいます。データグループについてはまだいくつか注意すべき点があるのですが、それらについては次回の記事で説明したいと思います。
ピアシステム
ピアシステム ( Peer System ) とは、機能規模測定対象のソフトウェアが通信で連携するシステムのことです。COSMIC 法のドキュメントではピアコンポーネントという用語も使われていますが、これは通信を介して連携する分散コンポーネントのことを意味していると思います。
COSMIC 法では、ピアシステムやピアコンポーネントと測定対象のソフトウェアとの間でやり取りされる通信データもデータ移動としてカウントします。その際に、測定対象のソフトウェアからピアシステムやピアコンポーネントに送信するデータをエクジットとし、測定対象のソフトウェアがピアシステムやピアコンポーネントから受信するデータをエントリーとします。
終わりに
今回の記事で、COSMIC 法の基本概念は概ね説明しました。COSMIC 法は比較的単純な機能規模測定手法だという点を納得していただけたでしょうか?他の手法を知らないと、比較的単純であるかどうかはあまり実感できないかもしれませんが、…。
次回は、COSMIC 法で機能プロセスとデータグループに関する注意点、ビジネスアプリケーションを測定する際の一般的な注意点、機能規模の集計方法、ソフトウェアの変更規模の測定方法について説明します。次回の記事で、COSMIC 法での機能規模測定の基本が理解できると思います。
参考文献
- [1] COSMIC 法の公式サイト, https://cosmic-sizing.org/, (参照 2016-02-29)
- [2] JFPUG の COSMIC 法のページ, https://www.jfpug.gr.jp/cosmic/top.htm, (参照 2010-07-08)
- [3] COSMIC-FFP による業務アプリケーションソフトウェア規模測定の指針, https://www.jfpug.gr.jp/cosmic/BAGv1_0j.pdf, (参照 2010-07-08)
- [4] COSMIC 機能規模測定 3.0 版 応用編, [2]のサイトで提供されているCOSMIC法ver3.0のマニュアルに含まれている
参考文献[2][3][4]について:
本記事を掲載した時には日本語訳のドキュメントがリンク先で公開されていましたが、2016年2月現在はリンク先に存在しないようです。日本語訳としては、代わりにJIS規格「JISX0143 ソフトウェア-COSMIC機能規模測定手法」をご覧ください。JIS規格は、日本工業標準調査会JISCの公式サイトhttps://www.jisc.go.jp/のJIS検索ページにてJIS番号「X0143」で検索すると閲覧できます。(2016年2月追記)