
システムエンジニアリングで
SysML を使いこなす
第2章 実践編-電光掲示板を設計する(2)
※本稿は、技術評論社刊『組込みプレス Vol.18』に掲載された特集記事「特集2 システムエンジニアリングで SysML を使いこなす」の転載です。 技術評論社の了承を得て転載しています。 本稿については、一切の転載をお断りします。
ソリューション開発本部 組み込みソリューション部
2.3. 方式設計
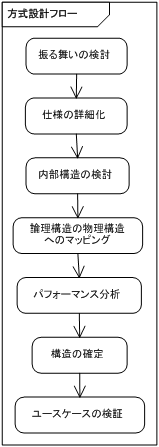
方式設計はシステムをコンポーネントの集合に分解し、コンポーネント間の結合やパフォーマンス確保のための方法などを確立し、仕様を設計可能なレベルに落とし込む工程です。 ここでは図 14 の流れに沿って検討を進めます。
2.3.1. 振る舞いの検討
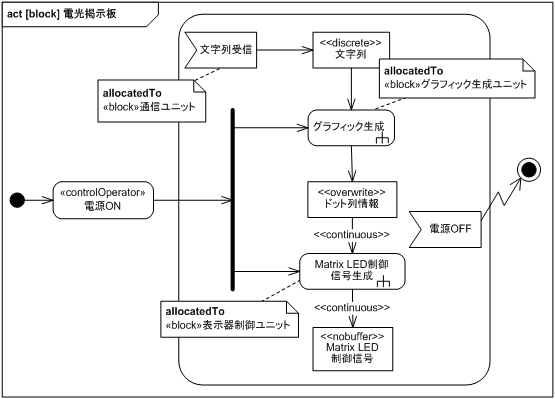
電光掲示板の全体的な動作を図 15 のアクティビティ図に示します。
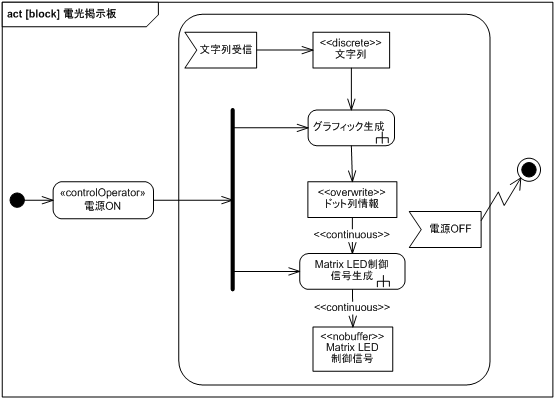
電源が ON されるとグラフィック生成と Matrix LED 制御信号生成が同時に動作可能になります。
グラフィック生成は <<discrete>> で離散的な文字列を入力としているので、文字列受信イベントが発生しないと動作しません。 Matrix LED 制御信号生成は <<continuous>> で連続的にドット列情報を受け取り Matrix LED 制御信号に変換して送り出しています。 電源 OFF になると全動作を終了します。
図でアクション右下の熊手型は callBehavior アクションと呼ばれ、詳細は他のアクションに記述されていることを示しています。 また、この図から今までの要求分析に電源 ON/OFF に関する記述が漏れていたことがわかります。
<<SysML>>
アクティビティ図はフローチャートに代わる図です。
黒丸は一連の処理 (アクティビティ) の開始、二重丸は終了を表します。 角丸四角形は個々の処理 (アクション) を表し、四角形の左側をへこました形はアクションの特殊な場合で受信イベントを表します。 アクションの特殊形は他にもシグナル送信/時間イベントがありますが、図中では用いていません。
アクション間を結んでいる矢印をコントロールフローと呼び、矢印の根元から先の順番で処理が実行されることを表します。 通常の四角形は処理の間で授受される情報や物などを表します。 図中の太線は、線の分かれた先が同時に処理されることを示します。 図中では使用されていませんが、フローチャートのように菱形で分岐を表現することもできます。
SysML でアクティビティ図に加わった変更の中で大きなものは、コントロールフローがアクションの開始だけでなく停止も表現できるようになったことと、連続的に情報や資源 (オブジェクトノード) が流れるアクティビティが表現できるようになったことです。
UML でのコントロールフローはアクションの開始を意味するだけでしたが、SysML ではコントロール値というデータを導入することによって開始だけでなく停止も表現できる (図 15 では停止は使用していませんが) ようになりました。 たとえばタイヤの摩擦係数が一定値以下の場合のみ ABS 制御を行うなど、これで連続的に投入されるオブジェクトノードに対して、アクションを行うのか行わないのかを規定する表現が可能となります。
また、<<controlOperator>> というステレオタイプが定義されており、コントロール値の制御だけを行うアクションであることを明確に示せるようになっています。
連続的なオブジェクトの流れを扱うために、<<rate>> というステレオタイプがデータフローに導入されています。
図中の <<discrete>> や <<continuous>> は <<rate>> の特殊タイプで、<<discrete>> は <<rate>> の時間間隔が 0 ではない、つまり離散的に投入されることを表しています。 <<continuous>> は <<rate>> の時間間隔が 0、つまり連続であることを表しています。 <<rate>> を指定する場合は時間間隔も指定します。
また、オブジェクトノードに対して <<overwrite>>、<<nobuffer>> というステレオタイプが用意されています。
<<overwrite>> はオブジェクトノードが持つバッファが一杯になったときに、新たなオブジェクトが投入されるとオブジェクトが上書きされることを表します。 上書きのされ方はオブジェクトノードのバッファ構造に依存していますが、規定では最後に参照されるオブジェクトノードが上書きされることになっています。 たとえば、FIFO では最初に入ったオブジェクトノードが最初に参照されるため、最後に入ったオブジェクトノードが上書きされます。 FILO の場合は逆に、最後に入ったオブジェクトノードが最初に参照されるので、最初に入ったオブジェクトノードが上書きされます。 通常のシリアル通信などではバッファが一杯になると、それ以上は電子の塵となって消えてしまうので <<overwrite>> ではありません。
<<nobuffer>> はアクションによってオブジェクトノードが処理されなかった場合、バッファされずに消えてしまうことを意味し、これにより電子回路の信号線が表現できます。 なお、<<continuous>> であるフローを流れるオブジェクトノードでは <<overwrite>> と <<nobuffer>> は同じ意味を持ちます。
出力されるオブジェクトノードに対して確率を設定できる規定も加えられました。 図では用いていませんが、たとえば 80% はキャッシュにヒットするからこっちのフロー、20% はキャッシュにないからこっちのフローといった処理が記述できます。 この他にも、オブジェクトノードのピン表記や事前条件/事後条件の記述など細かい追加がされていますが、詳細は割愛します。
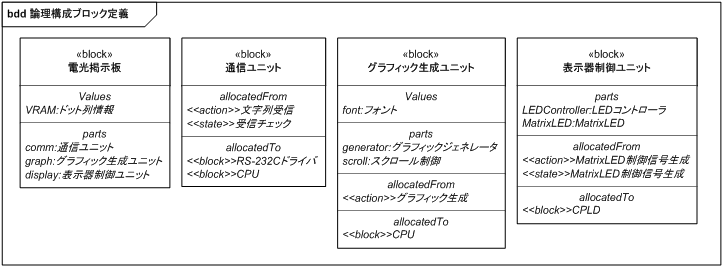
図 16 に、電光掲示板の振る舞い構造をブロック定義図にまとめます。
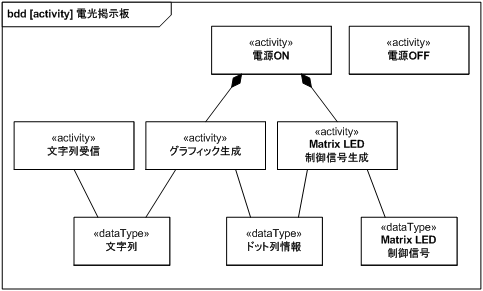
起点となるアクションは電源 ON、電源 OFF、文字列受信の 3 つがあり、電源 ON から直接駆動されるアクションはグラフィック生成と Matrix LED 制御信号生成の 2 種類であることを構造として示しています。
<<SysML>>
SysML のブロック定義図はさまざまな文脈で使われます。 システムのさまざまな側面に対し、構造を記述するのがブロック定義図、内容を記述するのが他の図という構図となっています。
たとえばシステムの接続関係を記述する場合、システムの階層構造はブロック定義図で、ブロックの接続関係は内部ブロックで記述します。 振る舞いに関しては呼び出し構造をブロック定義図で、動作をアクティビティ図で記述します。 このブロック定義図は構造化分析に使える図です。 制約に関しては制約の定義をブロック定義図で、制約関係をパラメトリック図で記述します。
ポートを流れるフローオブジェクトに関しても、定義はブロック定義図でインターフェースやフロー定義を行い、流れる場所は内部ブロック図やアクティビティ図で記述します。 このように、ブロック定義図は SysML において中核をなす図といえます。
次にシステムの状態遷移を検討します。 ステートマシン図は図 17 の通りです。 「停止中」に電源を ON すると「動作中」となり、この状態では表示 (動作中の上側) と通信 (動作中の下側) が並行して行われます。 表示に関しては常時 (do 表記) Matrix LED 制御信号生成を行うことが示されていて、アクティビティ図と一致しています。
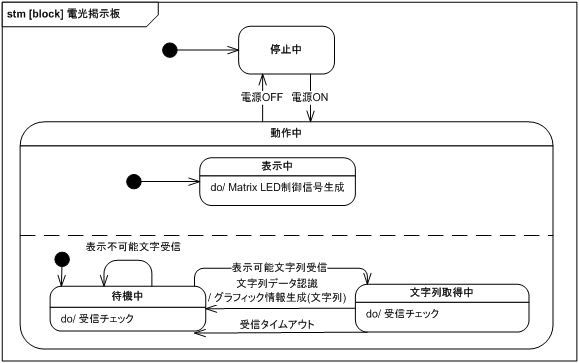
通信に関しては、「待機中」に表示可能文字列を取得すると「文字列取得中」状態に移行します。 「待機中」に表示不可能文字列を受信してもゴミとして捨てられ状態遷移は起こりません。 「文字列取得中」に文字列が表示すべき文字列データとして認識されると、グラフィック情報生成を呼び出し「待機中」に移行します。 また、一度「文字列取得中」状態に遷移したあと一定時間が経過すると、受信タイムアウトとして「待機中」に戻ります。 「動作中」に電源が OFF になると「停止中」状態となります。
この図から、仕様に受信タイムアウト時間が漏れていることがわかります。 また、文字列取得中に表示不可能文字を受信した場合の処理が未規定です。
このように、システムの振る舞いをさまざまな角度から検討すると、仕様の抜け漏れが発見されることが多いです。 むしろ、始めの仕様確定時から変更がある可能性が高いと考えたほうがよいでしょう。 SysML には振る舞いを表現する図が 4 種類用意されているので、システムの振る舞いをさまざまな角度から検討する助けとなります。
<<SysML>>
ステートマシン図はシステムの状態変化を表現するための図で、UML からの変更点はありません。
状態は一過性の処理と異なり、システムがある一定期間変化しないことを表現します。 よく処理を状態としているステートマシン図を見かけますが、これは間違いです。 処理はアクティビティ図で記述します。
また、言語仕様上ステートマシン図でもアクティビティ図で使用可能な分岐表現 (菱形で表す) が可能です。 しかし、筆者はクライアントにステートマシン図で分岐表現を使わないように勧めています。 なぜなら、ステートマシン図では状態から別の状態への移行を表現すべきであり、分岐は状態変化ではないからです。 状態遷移の途中で分岐が発生するということは、状態遷移のトリガ条件が異なっているはずです。 分岐ではなく、別のトリガ条件で別の状態に遷移させるべきだと考えます。
状態は角丸四角形で表現し、状態から別の状態へ引かれた矢印が状態遷移を表します。 矢印には、「トリガ[ガード条件]/作用」の形式で遷移を記述します。
状態には、その状態になった時点 (entry)、その状態でいる間 (do)、別の状態に遷移する直前 (exit)の振る舞いを記述することができますが、図中では do のみ使用しています。
また、状態を複数の点線で区切られた区画に分割することができ、それぞれの区画は並行して成り立つ状態 (直交状態といいます) を示します。
2.3.2. 仕様の詳細化
システムの全体的な動作を把握したので、要求分析で未定だった項目の決定および仕様の実現方法の検討を進めます。
2.3.1 でユースケースに見落としがあることが判明したのでユースケース図を図 18 のように修正します。
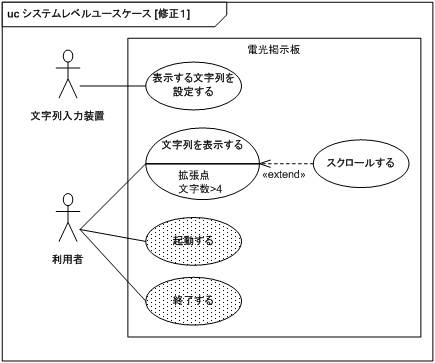
同時表示可能な文字数は 4 文字なので、拡張点でスクロールする条件を明記しました。 網掛け部分が追加したユースケースですが、この網掛けは SysML1.1 の規定ではありません。
次に表 5 を更新し、表 7 に示します。 未定であった項目にはひと通りの仕様を設定しました。 斜体太字になっている部分が今回変更した個所です。
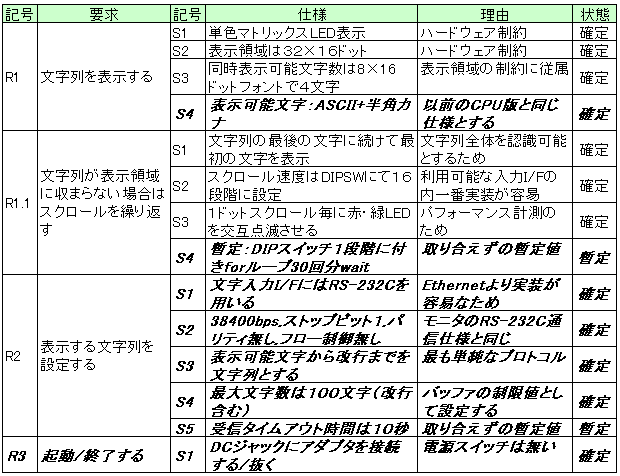
追加された要求「起動する」「終了する」に対する仕様では、頻繁に電源 ON/OFF を繰り返す使い方をすると接触不良になる懸念がありますが、この例題では良しとします。
仕様を更新したので、更新した仕様に対する考察を行います。 再び要求図を用いて検討した結果を図 19 に示します。
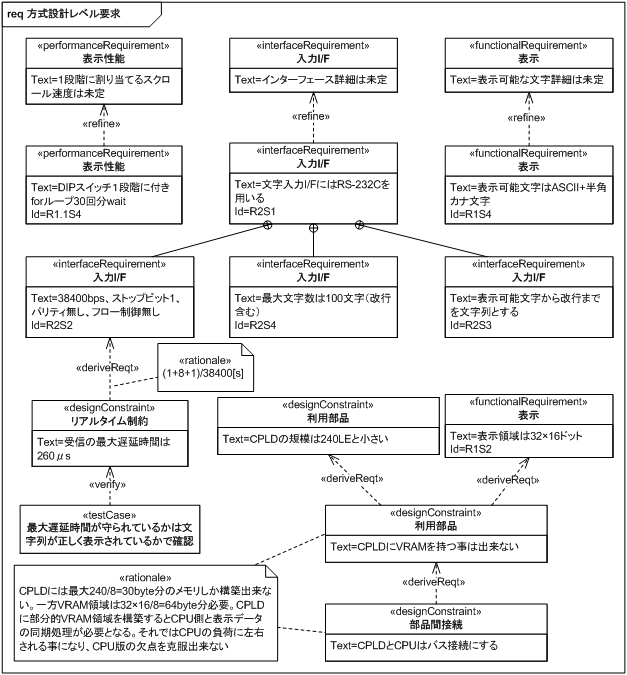
I/F 仕様を決定したので、そこからリアルタイム性に関する制約「受信の最大遅延時間は 260 μs」が導き出されています。 根拠として計算式が挙げられていますが、これはスタートビット+データ 8 ビット+ストップビットを 38400bps で行う場合の 1 文字受信にかかる時間です。 受信データの処理が行われないままこの時間が経過すると、次の文字が来てしまうのでオーバーランエラーとなります。 この確認は送信した文字が正しく表示されているかで行うこととしています。
また、CPLD の規模と表示領域の大きさから CPLD に VRAM を持つことができないと結論づけています。 本記事の CPLD を使った試みは、ソフトウェアで直接制御していた Matrix LED を CPLD から行うためのものです。 しかし、CPU と同期を取りながらでないと Matrix LED を制御できないのであれば、結局制御は CPU 負荷に依存したままとなり、CPLD 化のメリットが生かせなくなります。 よって、32×16 画素分すべてを VRAM として、ドット列データの書き込み側と読み出し側が任意の画素に対して独立アクセス可能とする必要があるのです。 それ故、全画素分の VRAM 容量を確保できない CPLD に VRAM を持つことができないのです。
VRAM を CPU 側に持つと、CPLD 側から CPU 側のメモリ領域に自由にアクセスできる必要が出てくるので、接続はバス接続を選択することになります。 制約事項が追加されたので一覧を更新します (表 8)。 斜体太字の部分が追加された項目です。

次に制約からくるハードウェアに対する仕様を検討します (図 20)。 電源は 5.0V と 3.3V を別々に用意するのではなく、5.0V から 3.3V にレギュレータで変換することにしています。
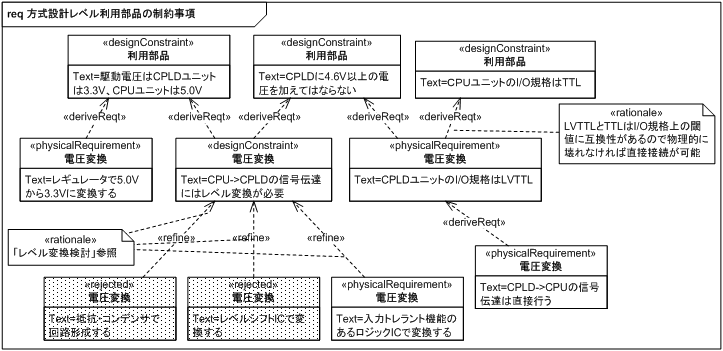
また、CPLD の I/O 規格は LVTTL とし、その根拠として TTL との互換性を挙げています。 LVTTL と TTL は閾値に互換性があり、ともに 0.8V 以下が 0、2.0V 以上が 1 として認識されるので、LVTTL 側に 5.0V をかけても壊れないのであれば変換なしに接続することができます。
使用する CPLD に掛けられる最大電圧は 4.6V のため、CPU→CPLD の方向に流れる信号はレベル変換が必要です。 しかし CPLD 側が LVTTL であれば、CPLD→CPU の方向に流れる信号はレベル変換の必要がないことになります。
最後にレベル変換の方法ですが、表 9 のように検討しました。

レベル変換の方法はおもに上記 3 種類ですが、抵抗/コンデンサで回路形成するのは基板に多くの面積を必要とし、また信号線の数が増えると実装に手間がかかるので却下しました。
専用のレベルシフト IC を使う方法もありますが、双方向変換の必要がないので、より安価で実現できる入力トレラント機能を持ったロジック IC で代用する方法を選択することにしました。
入力トレラント機能とは、IC が駆動電圧 (3.3V) より高い電圧 (5.0V) を入力端に掛けられても動作を保障する機能のことです。 同じロジック IC ならこの機能がないほうが安い傾向にありますが、レベルシフト専用の IC よりは安価です。
ロジックには AND や OR などさまざまな種類がありますが、論理演算を必要としていないので単なるバッファ (入力がそのまま出力になる) IC を用います。
なお、図中のステレオタイプ <<rejected>> は SysML の定義にはなく本記事の独自拡張で、複数の実現方法から却下された選択肢であることを表しています。 実現方法の検討バリエーションを資料として残しておきたかったので、このようなステレオタイプを導入しました。
実現方法にいくつかのバリエーションがある場合、ある方法が取られた理由をあとになってから参照したいことはよくあることなので、こういった拡張が有効であると思われます。
2.3.3. 内部構造の検討
これまではシステムの機能面と物理面において、全体的な仕様を見てきました。 これからはシステム構造の分割を、機能面と物理面に分けて検討していくこととします。
(1) 論理構成の検討
図 21、図 22 に電光掲示板の論理構成に関するブロック定義図と内部ブロック図を示します。
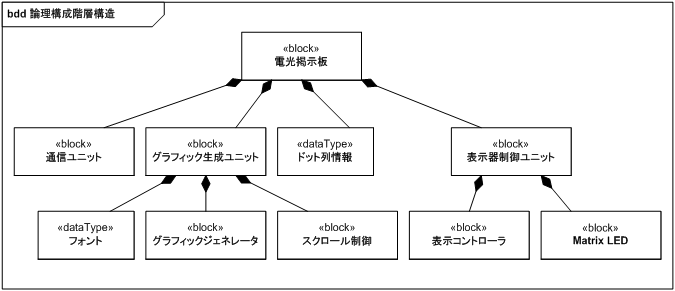

電光掲示板は大きく分けて通信ユニット/グラフィック生成ユニット/表示器制御ユニットの 3 ユニットから構成され、グラフィック生成ユニットと表示器制御ユニットの間には、ドット列情報を保持するためのメモリ (VRAM) が存在します。
基本構造は図 15 を踏襲した結果となっていて、責務分担は情報の変換単位となっています。 グラフィック生成ユニットはグラフィックジェネレータ/スクロール制御の 2 ユニットから構成され、フォントのインスタンスを保持するメモリを所有します。 表示器制御ユニットは表示コントローラ、Matrix LED の 2 ユニットから構成され、表示部分を担当します。 なお、Matrix LED は物理構成の Matrix LED と等価です。
電光掲示板の外部から入力された RS-232C 信号は com ポートから通信ユニットの com ポートに伝達されます。 通信ユニットで文字列に変換された信号は、標準ポートを介してグラフィック生成ユニットに伝達されます。 グラフィック生成ユニットは文字列をドット列情報に変換し、VRAM を介して表示器制御ユニットに伝達します。
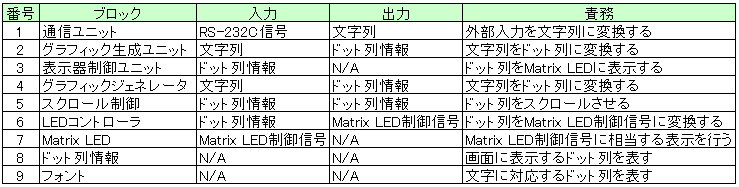
表 10 に各ブロックの責務一覧を示します。
(2) 物理構成の検討
図 23 に電光掲示板の物理構成に関するブロック定義図を示します。
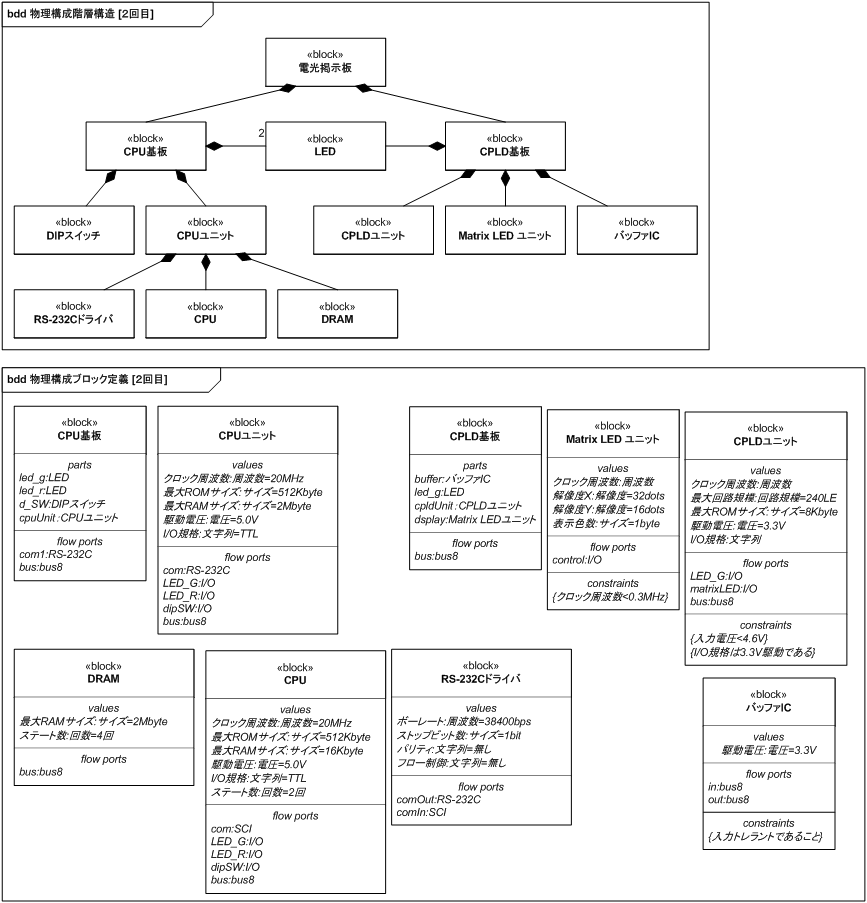
要求分析に用いた図 10 から加えた大きな変更は、CPLD 基板を作成してその中に CPLD ユニットおよび Matrix LED を配置したことです。 電圧レベルシフト用の IC および動作確認用の LED も CPLD 基板に配置しています。
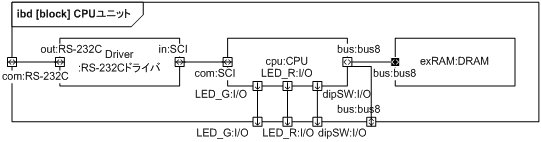
論理構成を物理構成へマッピングするため、CPU ユニットの内部を細分化し、RS-232C ドライバ/DRAM/CPU をブロックとして抽出しています。 また、調査の結果 CPLD には 8K バイト分の ROM 領域が存在することがわかったのでプロパティを加えました。 Ethernet は使用しないこととなったので構成から外しました。
2.3.4. 論理構成の物理構成へのマッピング
2.3.3 で電光掲示板の論理構成および物理構成を検討したので、ここでは論理構成のどの部分を物理構成のどの部分に割り当てるか検討します。
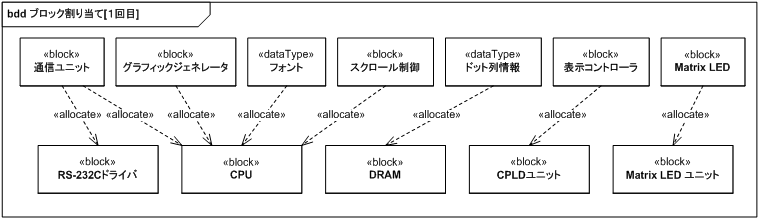
割り当てが必要になるのは、他ブロックを集約していない最下層のブロックです。 図 24 で上が論理構成、下が物理構成となります。
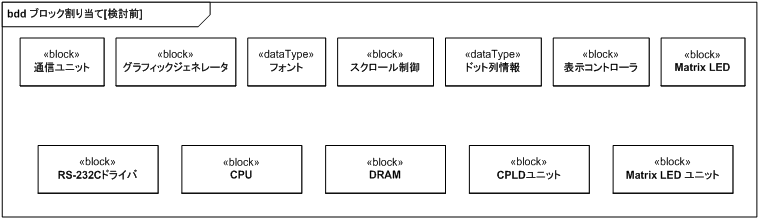
論理構成の Matrix LED は、責務上物理構成の Matrix LED ユニットと 1:1 対応しているのでそのまま割り当てます。 論理構成の通信ユニットは、CPU ユニットに付属の RS-232C 回線を利用するので、必然的に物理構成の RS-232C ドライバと CPU に割り当てます。 論理構成の表示コントローラは、本記事のプロジェクトの趣旨がソフトウェアで制御していたものをハードウェアに置き換えることなので、必然的に物理構成の CPLD ユニットに割り当てます。
CPLD には 32×16 ドットの情報を格納できる容量を持った VRAM 領域を確保することはできないので、論理構成のドット列情報は必然的に DRAM に割り当てます。
ここで問題となるのが DRAM へのアクセスです。 DRAM は CPU の 8 ビットバスに接続されていますが、CPLD からドット列情報を読み出すため、同じバスにアクセスしなくてはならなくなります。
バスアクセスの優先権を CPU が持ってしまうと、これまで目標としてきた「CPU の負荷に依存しない Matrix LED 制御」ができなくなってしまうので、優先権は CPLD 側が持たなくてはなりません。 したがって CPLD がバスにアクセスしている間 CPU はバスにアクセスできなくなり、CPU 側のパフォーマンス低下が懸念されます。
ここまでは選択の余地なく割り当てを決定可能ですが、残りのグラフィックジェネレータ、フォント、スクロール制御は選択の余地が残されています。
論理構成のフォントはドット列情報と異なり書き換える必要がないデータなので、ROM に配置することが可能ですし、RAM にダウンロードする選択肢も取れます。 表示可能文字列は ASCII 文字と半角カナでの 221 文字で、フォントに必要な領域は 221×16=3536 バイトとなります。 この大きさなら CPLD の ROM に収めることも可能です。 しかしフォントはグラフィックジェネレータに利用されるため、グラフィックジェネレータとバスを介さずにアクセス可能なほうが望ましくなります。
また、スクロール処理はグラフィックジェネレータの後処理となるため、フォントを CPLD 側に持つということはグラフィックジェネレータを CPLD 側に割り当てることとなり、さらにはスクロール処理も CPLD 側に割り当てることとなります。 CPLD の 240LE でどこまでの回路構成が可能なのか全体が見えてこないので、まずはグラフィックジェネレータ、スクロール制御ともに CPU 側に割り当て、余裕がありそうだったらスクロール制御を CPLD に移し、さらにいけそうだったらグラフィックジェネレータも移すことにします。
以上から、第一段階のマッピングは図 25 のようになります。
2.3.5. パフォーマンス分析
2.3.4 で CPU パフォーマンス低下が懸念されたので、描画性能と CPU 負荷に関するパフォーマンスを分析することにします。
図 26 に RAM アクセスと描画性能に関する制約ブロックを示します。
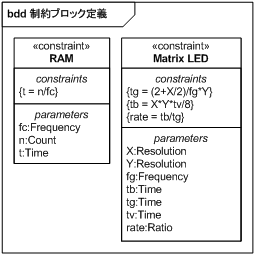
RAM へのアクセス時間 (t) は、アクセスに必要なクロック数 (n) に 1 クロックにかかる時間 (1/fc) を掛けた値となります。 描画に必要な時間は、画素 X (X) の半分に 2 を足した値に 1 クロックにかかる時間 (1/fg) を掛けた値に、画素 Y (Y) を掛けた値となります。 画素 X を半分にするのは、本記事の Matrix LED は X 方向に 16×16 ドットの Matrix LED を 2 個並べた構成となっており、同時に左右 2 個のドットを指定するので、X 方向の描画にかかるクロックは半分ですむためです。 また、2 を足しているのはラッチ出力の ON/OFF がドットの描画とは別に必要なためです。
描画時にバスを占有する時間 (tb) は、1 画面の総画素数 (X*Y) をバイト数に変換して RAM へのアクセス時間 (tv) を掛けた値となります。 描画中にバスアクセスする割合 (rate) は、描画時にバスを占有する時間 (tb) を描画に必要な時間 (tg) で割った値となります。
次に、描画性能を分析するためのパラメトリック図を図 27 に示します。
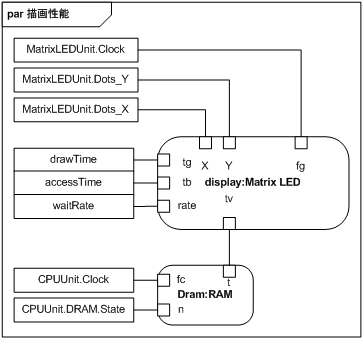
CPUUnit の Clock (20MHz) を fc に、CPUUnit の DRAM の State (4clock) を n に、MatrixLEDUnit の Dots_X (32dots) を X に、MatrixLEDUnit の Dots_Y (16dots) を Y に、MatrixLEDUnit の Clock (未決定) を fg に割り当てています。
tg に割り当てた drawTime、tb に割り当てた accessTime、rate に割り当てた waitRate は観測したい値です。
<<SysML>>
パラメトリック図は SysML で新たに導入された図で、内部ブロック図の特殊バージョンです。 基本構造は内部ブロック図と同じですが、使える要素を制約プロパティとそのパラメータに限定しています。
内部ブロック図のプロパティは四角形で表されますが、パラメトリック図中の制約プロパティは角丸四角形となっていて、ひと目見て内部ブロック図と異なることがわかるようになっています。
パラメータは小さい四角形で表し、一辺を制約プロパティの辺にくっつけるように書きます。 パラメータ同士は線で表されるバインディングコネクタを用いて接続する他、他ブロックのプロパティを割り当てることもできます。
他ブロックプロパティの指定は、図中の CPUUnit.DRAM.State のように "." で区切ってブロック構造のネストを辿ることができます。
パラメータ間の接続には方向の概念がないのでコネクタに矢印は現れません。 接続されたパラメータは「=」であると解釈されます。
ブロック線図のイメージだとデータが移動する方向に矢印が付くので、矢印がないと違和感を覚えます。 しかし、ブロック線図でも概念的に接続されている線の両端は「=」なので、ブロック線図的な使い方もできると思われます。 SysML の文法にこだわらないのであれば、矢印をつけるのもありだと思います。
パラメトリック図は制約ブロックで定義された制約間の関係を記述するのに用いるので、基本的にブロック定義図とペアで使われます。
制約ブロックの記述は、システム工学の知識より物理学や化学など制約を記述するドメインに関する高度な知識を必要とします。 また、逆にドメインに普遍な法則レベルで制約を記述することにより、同じ法則が適用できるさまざまなシステムに応用が可能な独立パッケージとすることができます。
SysML では標準的な分析用制約パッケージが用意されていないので、利用者が 1 から制約ブロックを記述していかなくてはなりません。 しかし、今後分析パッケージが標準化され、専門知識がない人でも手軽に検証が行えるようになることを期待したいところです。
当然企業ノウハウとすべき制約ブロックも多数生まれてくると思いますが、これによりシステム設計の大きな効率化が図られることになると思います。
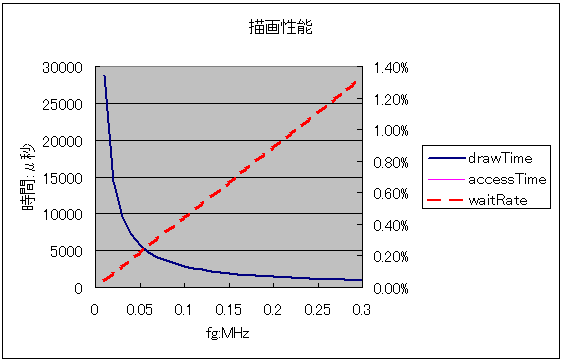
図 28 に fg を 0.01MHz から 0.3MHz (制限値の上限) まで振ったシミュレーションの結果を示します。 実際の DRAM にはバーストモードというモードがあり高速アクセスが可能ですが、シミュレーションではノーマルモードの 4 ステートアクセスとしています。
なお、SysML では制約の記述言語を指定していませんので、シミュレーション機能の有無およびシミュレーション機能を利用するための制約記述方法は、モデリングツールに依存することになります。
MatrixLED のクロック周波数を上限の 0.3MHz まで上げると 960 μs で 1 画面分の描画が完了し、バスの占有率は 1.33% です。
パソコンのディスプレイなどで使われる 60fps の描画性能では 1 画面辺り 16.67ms の時間となります。 しかし、クロック周波数を 0.02MHz まで下げても描画時間は 14.4ms と余裕があり、そのときのバス占有率は約 0.1% です。 描画用のクロックは 0.02MHz で十分であり、CPLD がバスを占有する割合も本記事の電光掲示板としてはまったく問題ない数値といえます。
しかし、この例題は電光掲示板ですが今後このシステムをさまざまな検証に使用することを考えると、CPLD のバスアクセスで CPU が待たされることには不安が残ります。
そこで、VGA フルカラーの描画ではどうなるかシミュレーションしてみました (図 29)。
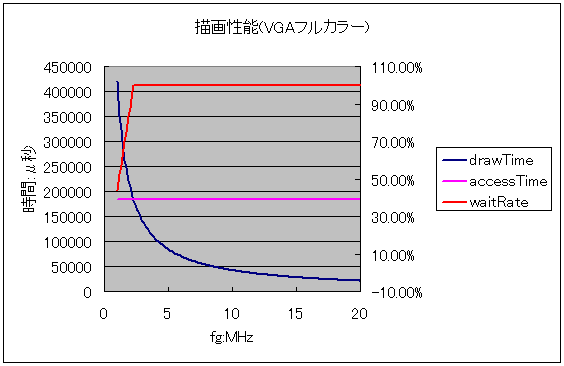
基本的に描画時間よりバスアクセス時間のほうが長い、つまり CPU は動作しないという結果となりました。 このレベルになると遅い DRAM を使ったグラフィック描画は不可能ということになります。
それでは敷居を下げて FA 用ハンディターミナルなどに使われる表示器の 320×240 の 256 色表示ではどうなるでしょうか?(図 30)
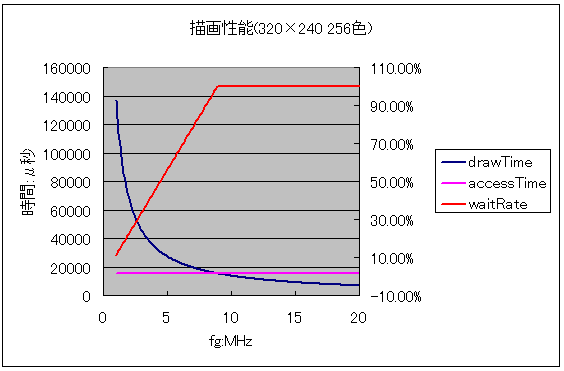
辛うじて 60fps で回りますが、この場合の accessTime と drawTime はほとんど重なっているので、CPU はほぼ動作しないこととなります。
電光掲示板としては問題ないのですが、電光掲示板を作ることは目的ではないので、将来的にこのハード構成でさまざまな検証を行うことを考えると、CPLD がバスを占有する方式はなんとか解消したいところです。
2.3.6. 構造の確定
(1) 物理構成の変更
パフォーマンス分析の結果、本記事の電光掲示板としては問題ないですが、将来このシステムを用いて表示領域や色数の多い表示器を構成するには、DRAM のバスアクセスに問題があることがわかりました。
通常、表示用の VRAM は表示デバイス側から頻繁にアクセスされるため、CPU のローカルバスとは独立したバスからアクセスできるようにすることが多いです。 デュアルポート RAM やマルチポート RAM と呼ばれる RAM がこの機能に用いられ、CPU 側と表示デバイス側で別のポートから共有データへアクセスします。
近年では FPGA (規模の大きい CPLD) が安価になり、64 バイト程の小規模なメモリであれば FPGA 内に構築してしまうのが一般的です。 そうでなければ、グラフィックボードに載っているような高性能の VRAM を用いる例が多く、小規模のデュアルポート RAM (しかも手差しで半田づけができる DIP 形式となると) は入手が著しく困難になります。
本記事のシステムを作成するに当たって、将来性を考えてデュアルポート RAM が入手できたら使用したいと考えました (図 32)。 また、システムエンジニアリングの例題としても、CPU と CPLD の切り分け以外の物理デバイス選択が加わったほうが良いでしょう。
探した結果 2K バイトのデュアルポート SRAM が入手できたので、これを用いた構成に物理構成を変更することにします。
図 31、32 に最終版の物理構成を示します。
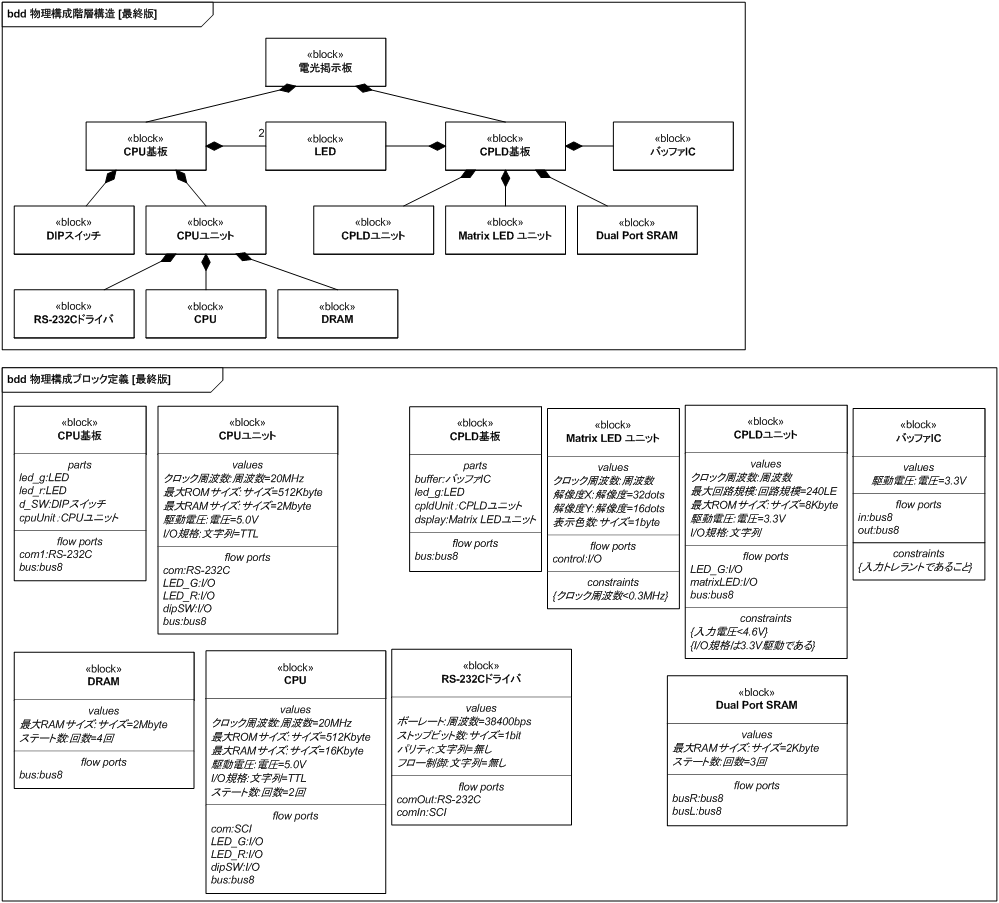
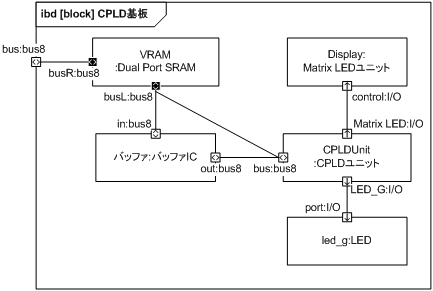
デュアルポート RAM (VRAM) の R 側を CPU 基板と接続するための外部端子に、L 側を CPLD ユニットに接続します。 ただし CPLD への入力となる信号はバッファを通して 5.0V を 3.3V に変換します。
図 33 では、Ethernet 関係および未使用ポートは使用しないので図から外しました。
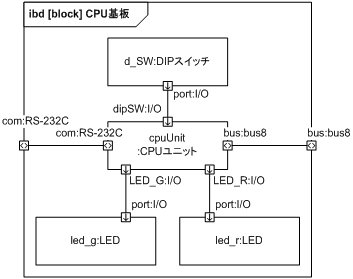
CPU から外部 RAM (DRAM) へは 8 ビットバスを通して、RS-232C ドライバへは CPU のシリアルコミュニケーションインターフェース (SCI) を通して接続されています。
<<SysML>>
図 35 の RAM に繋がっているフローポートは色が反転していて黒字に白抜きの矢印となっています。 これはフローポートの conjugated 属性が true になっていることを表していて、入力と出力が規定と反転していることを示しています。 CPU や CPLD からの出力は RAM 視点では入力になるのでこのような表記となります。
次に物理構成で使われているポートの定義を図 34 に示します。
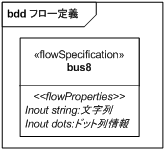
8 ビットバスは文字列データとドット列情報を扱うポートであることを示します。
<<SysML>>
すでにブロック定義図で説明したように、複数のオブジェクトが流れる可能性のあるフローポートの仕様は Flow Specification で規定します。 流れるオブジェクトの種類が 1 つのポートはアトミックポートと呼ばれ、オブジェクトを表すブロックや値型のインスタンスです。
(2) 割り当ての変更
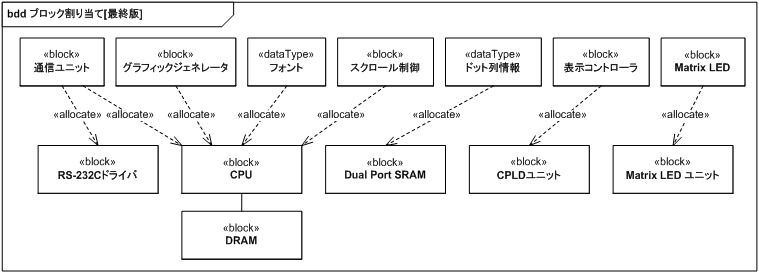
VRAM をデュアルポート SRAM に割り当てるように変更した割り当ては図 36 になります。
(3) 振る舞いの論理構成へのマッピング
物理構成/論理構成が固まったので、振る舞いを論理構成にマッピングします。 もともと振る舞いを基に論理構成を構築しているのでマッピングは単純です。
図 37 に更新したブロック定義図を示します。
また、基本アクティビティ図にも割り当てを加えました (図 38)。
割り当ての指定は、モデル間の追跡可能性を確保するうえで有効な手段と考えます。 モデリングツールに割り当て関係を調査する機能があれば、積極的に活用し抜け漏れがないことをチェックすべきです。
2.3.7. ユースケースの検証
構造が確定したので、論理構成に割り当てた振る舞いでユースケースが実現可能かを、シーケンス図を用いて検証します。 図 39、図 40 にユースケースに対するシーケンス図を示します。
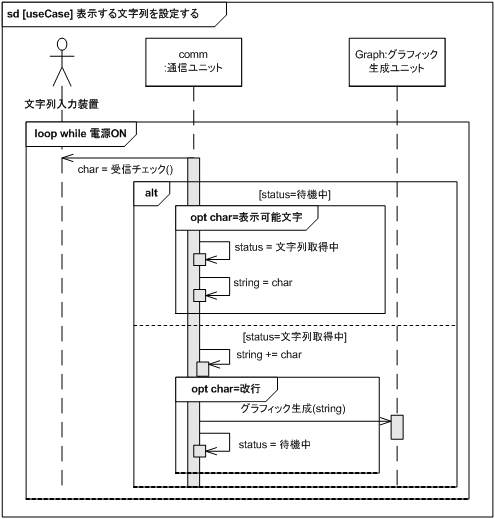
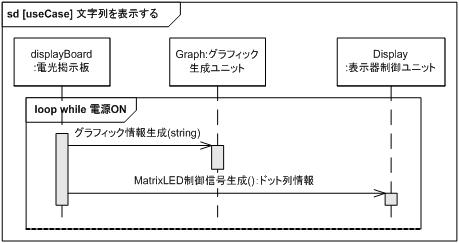
表示する文字列を設定するシーケンス図のほうは主状態図をそのまま反映していますが、文字列を表示するシーケンス図はスクロール処理をするためにグラフィック生成を呼び出す処理が追加されています。
<<SysML>>
シーケンス図はパーツ間のやり取りを時系列に記述するために利用し、UML からの変更点はありません。 縦が時間軸で、上から下に時間が経過します。 左右に出ている矢印がパーツ間のやり取りを示します。 一番上の四角がパーツで、図のようにシステム外のアクターが含まれることもあります。
パーツから縦に伸びている点線をライフラインと呼び、太くなっている部分が実際にパーツが動作している時間 (活性区間) を表します。 四角形で囲まれた枠の部分を複合フラグメントと呼び、繰り返しを意味する loop、排他的選択を意味する alt、特定の場合のみ実行される opt など、さまざまなシーケンス制御を記述できます。
シーケンス図は一連の動作が繋がっていることが原則です。 たまに矢印を辿って繋がらないシーケンス図を見ることがありますが、それは間違いです。 上から矢印を辿ると一連の動作終了まで行き着くよう心がけてください。
システム最上位レベル状態遷移図の「表示中」にグラフィック情報生成アクションが抜けていたので追加します (図 41)。
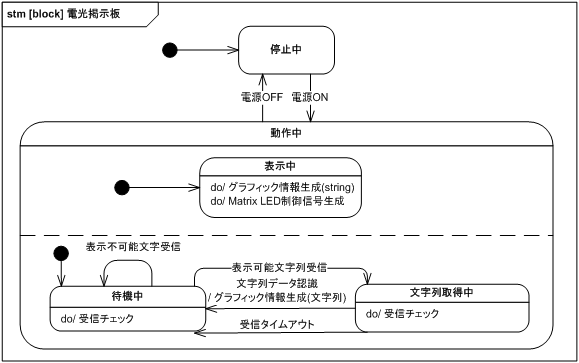
「表示」と「通信」は並行して存在するので、「表示」の do と「通信」の文字列データ認識で共通のグラフィック情報生成アクションは設計時に競合しないように注意が必要となります。
2.4. まとめ
以上で SysML を活用したシステムエンジニアリングの説明を終わります。 SysML 活用のイメージはつかめたでしょうか。 何かひとつでも使用してみたいダイアグラムがあったなら、そこから実践していけば良いと思います。 実践しているうちに 9 つのダイアグラムを使いこなせるようになるでしょう。
システムエンジニアリングプロセスがなく、開発現場が混沌としているのであれば、SysML の習得は後回しにしても、まずは何らかのシステムエンジニアリングプロセスを実践してみることをお勧めします。 違う分野の人とのコラボレーションにより視覚化されたシステムは、混沌としていた開発現場に光を当てることでしょう。
本記事が皆様の業務の一助となれば幸いです。