
本連載は、機械学習を行うエンジニアまたは、これから始めようと考えているエンジニア向けにAmazonの機械学習プラットフォームのマネージドサービスAmazon SageMaker(以下、SageMaker)を紹介します。SageMakerを使うことで、機械学習における開発サイクルが効率化され、AIを活用したシステムの導入がこれまでより容易になることでしょう。第1回の本記事では、SageMakerの概要とチュートリアルをお届けします。
SageMakerの概要
SageMakerは昨年のre:invent 2017で発表されリリースされたばかりのフルマネージドなエンド・ツー・エンドの機械学習サービスです。機械学習のモデル開発プロセスを管理するためのサービスを提供します。モデル開発プロセスに伴う複雑で面倒な部分を肩代わりします。機械学習をこれから始めようと考えているエンジニアの敷居を下げるだけでなく、データサイエンティストやAIエンジニア、機械学習のエキスパートが素早くモデルを構築し、スケーラブルなトレーニングと素早いリリース(デプロイ)を可能にします。
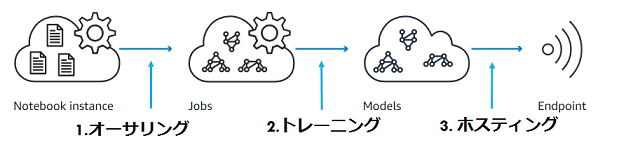 出典)Amazon SageMakerダッシュボードの概要に掲載されている図
出典)Amazon SageMakerダッシュボードの概要に掲載されている図
SageMakerは「オーサリング」「トレーニング」「ホスティング」の3つのモジュールで構成されています。すべての作業はJupyter Notebookで行うことができます。Jupyter Notebookを使うことで、データ整理からモデルのトレーニング・デプロイまでエンド・ツー・エンドの環境で作業のドキュメントを残すことができます。
1.オーサリング
モデルのベースとなるデータの概要を整理します。外れ値の除去などのクレンジングやモデルにロードするため前処理を行います。ノートブックインスタンスは、GPUインスタンスを使うこともできます。また、自由にpythonライブラリを追加して、データのオーサリングができます。
2.トレーニング
SageMakerが提供しているBuilt-inのアルゴリズムやDeep Learningフレームワーク、Dockerによる独自学習環境を使ってモデルをトレーニングすることができます。生成したモデルはS3に保存されます。このモデルはそのままSageMakerにホスティングすることできますし、AWS以外に持ち出してIoTデバイスなどにデプロイすることもできます。
3.ホスティング
SageMakerでトレーニングしたモデルやAWS以外から持ち込んだモデルを使って、リアルタイムに推論するHTTPSエンドポイントを作ることができます。エンドポイントはスケールすることができ、同時に複数モデルをデプロイするA/Bテスト、独自のアプリケーションを入れたカスタムなDockerイメージも利用できます。
ホスティングした推論をモニタリングし、新たに取得されたデータを使って更に精度を改善させていくことができます。
トレーニングの種類
モデルをトレーニングする方法は、以下の4種類があります。本記事の後半にあるSageMakerの利用手順では、トレーニング方法としてBuilt-inアルゴリズムを用いています。
Built-inアルゴリズムを使ったトレーニング
SageMakerが用意している既に出来上がっているアルゴリズムを使ってモデルをトレーニングします。
Deep Learningフレームワークを使ったトレーニング
Deep Learningフレームワークを利用することができます。SageMakerでは、TensorflowとMXNetをサポートしています。自らモデルを定義することができます。
カスタムアルゴリズムを使ったトレーニング
手組みのDockerイメージとモデルを使ってトレーニングします。Built-inアルゴリズムには、アルゴリズムごとにこのECRが用意されています。
Spark上でのトレーニング
Apache Spark MLlibのように、SageMakerを利用できます。
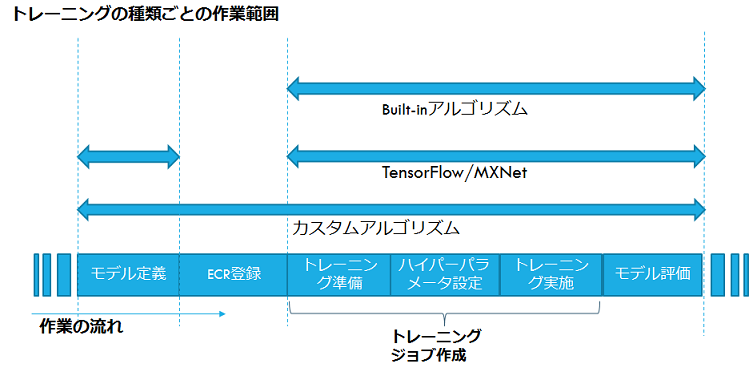
トレーニングの種類ごとの作業範囲
トレーニングの種類ごとの作業範囲を下図に示します。Built-inアルゴリズムは作業範囲が狭く簡略化されています。一方、カスタムアルゴリズムは広範囲であり手組みの余地が多くなります。
Built-inアルゴリズムの種類
SageMakerのBuilt-inアルゴリズムとして現在は次のものが用意されています。
| アルゴリズム名 | 教師 | 用途 |
|---|---|---|
| Linear Learner(線形回帰) | あり | 分類問題、回帰分析 |
| XGBoost(勾配ブースティング) | あり | 分類問題、回帰分析 |
| Factorization Machines | あり | レコメンデーション |
| K-Means(K近傍法) | なし | 分類問題 |
| PCA(主成分分析) | なし | 次元削減 |
| Image Classification(ResNet) | あり | 画像分類 |
| Sequence2Sequence | あり | 機械翻訳、自動要約、音声認識 |
| Latent Dirichlet Allocation(LDA) | なし | トピック分析 |
| Neural Topic Model(NTM) | なし | トピック分析 |
| DeepAR Forecasting | あり | 再帰型ニューラルネットワーク (RNN) によるより正確な時系列予測 |
料金
SageMakerで利用できるオンデマンドMLインスタンスは標準のオンデマンド料金よりも割高になっています。また、スポットインスタンスを選ぶことはできません。
次の表は2018.1.11時点のバージニア北部の料金です。
オンデマンドMLインスタンス料金
| Module | ML type | 時間あたりの料金 |
|---|---|---|
| オーサリング | ml.t2.medium | $0.0464 |
| ml.m4.xlarge | $0.28 | |
| ml.p2.xlarge | $1.26 | |
| トレーニング | ml.m4.xlarge | $0.28 |
| ml.c4.xlarge | $0.279 | |
| ml.p2.xlarge | $1.26 | |
| ホスティング | ml.t2.medium | $0.065 |
| ml.m4.xlarge | $0.28 | |
| ml.p2.xlarge | $1.26 |
参考) https://aws.amazon.com/jp/sagemaker/pricing/
標準のオンデマンド料金
| type | 時間あたりの料金 |
|---|---|
| t2.medium | $0.0464 |
| m4.xlarge | $0.2 |
| c4.xlarge | $0.199 |
| p2.xlarge | $0.90 |
参考) https://aws.amazon.com/jp/ec2/pricing/on-demand/ MLタイプに対応したもののみ記載
前準備:Jupyter Notebookの起動
AWSの準備
AWSの基本的な準備の詳細は省略します。
- AWSアカウント作成
- ユーザー作成 … IAM管理者のユーザー作成およびサインイン
- リージョン選択 … 2018.1.11時点で、利用できるリージョンは米国東部(バージニア北部)、米国東部(オハイオ)、米国西部(オレゴン)、EU(アイルランド)のみです。
- S3バケット作成 … 学習データやモデルを保存するS3バケットの作成
- SageMakerサービスへ移動
ノートブックインスタンスの設定
まず、ノートブックインスタンスの設定をします。必須の設定項目は「ノートブックインスタンス名」、「ノートブックインスタンスのタイプ」、「IAMロール」です。
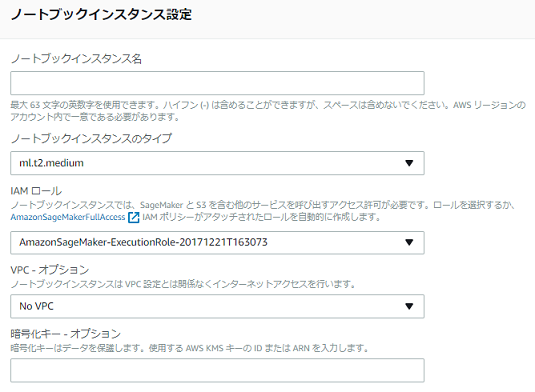
ノートブックインスタンスタイプ
ノートで利用できるインスタンスタイプは、ml.t2.medium, ml.m4.xlarge, ml.p2.xlargeが選べます。AnacondaとDeep Learningで利用される共通ライブラリ、5GBのストレージボリューム、そして、様々なアルゴリズムをデモするためのサンプルのノートブックが入った機械学習計算用のインスタンスが起動します。上の図ではml.t2.mediumを選択しています。
IAMロール
S3, ECRなどのアクセス権限を付加します。
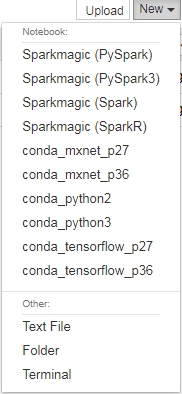
Jupyter Notebookの起動
「オープン」を押すと、jupyter notebookが立ち上がり利用できるようになります。(下図)

「sample-notebooks」には、サンプルのノートブック一式が同封されています。(下図にsample-notebooksフォルダが確認できます)

新規にノートブックを作る場合(上図の右上の「New」ボタン)にAnaconda, Tensorflow, MXNetなどがpython2または3系で利用できます。
Built-inアルゴリズムを使った一連の流れ
ここから起動したjupyter notebookで作業を行います。
同梱されているサンプルノートブックの「K-Means MNIST high-level」で、Built-inアルゴリズムを使ったトレーニングの一通りの利用手順を見ていきます。
参照先)notebooks/sample-notebooks/sagemaker-python-sdk/1Pkmeanshighlevel/kmeans_mnist.ipynb
今回は、データセットにラベルを付ける必要なく分類を行うことができる、教師なし学習のアルゴリズムK-Meansを使ったモデルのトレーニングを行います。
0.SageMakerのセットアップ
ノートブックインスタンスを作成したときのIAMロールを取得し、トレーニングやホスティングでデータにアクセスする際に利用します。
from sagemaker import get_execution_role role = get_execution_role() bucket='sagemaker-test-aic'
1.オーサリング
データの取得
0から9までの手書き文字のMNISTデータセットで分類問題を行っていきます。 MNISTデータセットには、28 x 28ピクセルの7万件の実データと同数のラベルデータが含まれています。 データセットの詳細な説明は、https://yann.lecun.com/exdb/mnist/ にあります。
%%time
import pickle, gzip, numpy, urllib.request, json
# Load the dataset
urllib.request.urlretrieve("https://deeplearning.net/data/mnist/mnist.pkl.gz", "mnist.pkl.gz")
with gzip.open('mnist.pkl.gz', 'rb') as f:
train_set, valid_set, test_set = pickle.load(f, encoding='latin1')
pickle形式で保存されたデータを読み込むと、3つのtrain, validation, testデータセットが5:1:1の割合で分割され、実データとラベルデータのtuple型で格納されています。 それぞれのデータの形状を示します。
# 実データの形状 train_set[0].shape, valid_set[0].shape, test_set[0].shape ((50000, 784), (10000, 784), (10000, 784))
# ラベルデータの形状 train_set[1].shape, valid_set[1].shape, test_set[1].shape ((50000,), (10000,), (10000,))
実データは、28 x 28のピクセルがフラットに格納されています。画像表示する際にはreshapeが必要になります。 ラベルデータは、0から9までの数字で格納されています。実データと突き合わせる際にはそのまま利用できます。
今回はデータセットが小さいため、メモリ上に読み込み、学習・評価・テストデータとしてそのまま利用します。通常、大きなデータセットの場合にはS3へアップロードします。
データの検査
学習前のプロセスとしてデータを事前に検査し、必要な前処理を行う判断としてデータの概観を理解していきます。ここでは、インポートした文字データセットの中から1つを取り出し表示してみます。
%matplotlib inline
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (2,10)
def show_digit(img, caption='', subplot=None):
if subplot==None:
_,(subplot)=plt.subplots(1,1)
imgr=img.reshape((28,28))
subplot.axis('off')
subplot.imshow(imgr, cmap='gray')
plt.title(caption)
show_digit(train_set[0][30], 'This is a {}'.format(train_set[1][30]))

2.トレーニング
次はトレーニングジョブを作る場合の例です。K-Meansアルゴリズムのモデルをトレーニングするパラメータを設定します。パラメータには、ロール、インスタンス数、インスタンスタイプ、モデルの出力ロケーション、分類するクラスタ数、トレーニングデータのロケーションを指定します。この他にハイパーパラメータを変える場合には、引数またはメソッドでセットすることができます。SageMakerのWebコンソールでも同様の作業も行うことができます。
今回、大量データセットに対応したミニバッチ・サイズ分のデータごとに更新するミニバッチ K-Meansを使っています。インスタンスをスケールアウトして更新することができ、トレーニングデータを分割して格納するロケーションを指定しています。
アルゴリズムの参照先: Web-scale k-means Clustering
from sagemaker import KMeans
data_location = 's3://{}/kmeans_highlevel_example/data'.format(bucket)
output_location = 's3://{}/kmeans_example/output'.format(bucket)
print('training data will be uploaded to: {}'.format(data_location))
print('training artifacts will be uploaded to: {}'.format(output_location))
kmeans = KMeans(role=role,
train_instance_count=2,
train_instance_type='ml.c4.8xlarge',
output_path=output_location,
k=10,
data_location=data_location)
実行結果はこちら。
training data will be uploaded to: s3://sagemaker-test-aic/kmeans_highlevel_example/data training artifacts will be uploaded to: s3://sagemaker-test-aic/kmeans_example/output INFO:sagemaker:Created S3 bucket: sagemaker-us-east-1-104803501938
トレーニングの実行開始はsklearn likeなfitメソッドで行います。トレーニングには少々時間がかかります。
%%time kmeans.fit(kmeans.record_set(train_set[0]))
実行結果はこちら。
INFO:sagemaker:Creating training-job with name: kmeans-2018-01-16-08-29-21-910 ....................................................................... (省略) ===== Job Complete ===== CPU times: user 7.81 s, sys: 416 ms, total: 8.23 s Wall time: 6min 49s
3.ホスティング
トレーニングしたモデルをエンドポイントにデプロイします。
%%time
kmeans_predictor = kmeans.deploy(initial_instance_count=1,
instance_type='ml.m4.xlarge')
実行結果はこちら。
INFO:sagemaker:Creating model with name: kmeans-2018-01-16-08-36-40-776 INFO:sagemaker:Creating endpoint with name kmeans-2018-01-16-08-29-21-910
次にpythonコードから予測を実行する場合の例を示します。
評価データから100件取り出して、トレーニングしたモデルから0-9までのクラスタに分類された予測結果を見てみます。
%%time
result = kmeans_predictor.predict(valid_set[0][0:100])
clusters = [r.label['closest_cluster'].float32_tensor.values[0] for r in result]
for cluster in range(10):
print('\n\n\nCluster {}:'.format(int(cluster)))
digits = [ img for l, img in zip(clusters, valid_set[0]) if int(l) == cluster ]
height=((len(digits)-1)//5)+1
width=5
plt.rcParams["figure.figsize"] = (width,height)
_, subplots = plt.subplots(height, width)
subplots=numpy.ndarray.flatten(subplots)
for subplot, image in zip(subplots, digits):
show_digit(image, subplot=subplot)
for subplot in subplots[len(digits):]:
subplot.axis('off')
plt.show()
実行結果はこちら。

0から9までのクラスタが実際には出力されますが、最初の2件のみ表示しています。
結果を見るとざっくりと分類はできています。K-Meansクラスタリングは、画像分類の問題にとって最適なアルゴリズムではありませんが、かなり合理的なクラスタが形成されていることが分かります。
推論する環境が不要になった場合、エンドポイントを削除します。
import sagemaker sagemaker.Session().delete_endpoint(kmeans_predictor.endpoint)
実行結果はこちら。
INFO:sagemaker:Deleting endpoint with name: kmeans-2018-01-16-08-29-21-910
さいごに
今回は、SageMakerの概要とその上での機械学習のワークフロー、Built-inアルゴリズムでモデルをトレーニングする場合の利用手順を見ていきました。Built-inアルゴリズムを使う場合にはモデル定義や学習環境を整備せずに、APIを呼び出すことで手軽にトレーニングが行え、モデルをアプリケーションに組み込みデプロイし、推論が簡単にできることが分かりました。
起動したまま放置しておくと課金されてしまうため、不要になったendpoint、notebook instanceの停止を忘れずにしましょう。
次回は、TensorFlowで自らニューラルネットワークのモデルを設計する方法や自らDockerイメージを持ち込んでトレーニングする方法について見ていきます。
(以下、2018年4月追記)
本文中のソースコードは、以下に公開されている “amazon-sagemaker-examples"より引用しています。
https://github.com/awslabs/amazon-sagemaker-examples
また、"amazon-sagemaker-examples” は Apache License 2.0 が適用されています(2018年3月現在)。
Apache License 2.0 の内容は以下を参照ください。
https://www.apache.org/licenses/LICENSE-2.0