
本記事では、機械学習エンジニア向けにモデル開発プロセスに伴う複雑で面倒な部分を肩代わりする機械学習プラットフォームをご紹介します。前回の記事では、Amazon SageMakerについての概要と用意されたBuilt-inアルゴリズムを使ったチュートリアルについて解説しました。今回は、TensorFlowを利用してモデルを定義し、トレーニングする方法から、この学習済みモデルをホスティングする方法までをサンプルコードを使ってご紹介します。
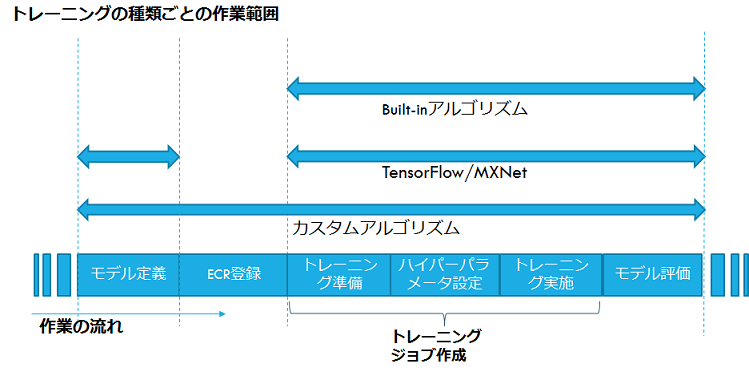
同梱されているサンプルノートブックの「tensorflow distributed MNIST」をベースに、TensorFlowを使ったトレーニングの一通りの利用手順を見ていきます。
参照先)notebooks/sample-notebooks/sagemaker-python-sdk/tensorflow_distributed_mnist
今回は、畳み込み層を使ったニューラルネットワークモデルを作成する方法に焦点を当てます。
1. SageMakerのセットアップ
「Built-inアルゴリズムを使った一連の流れ - 1.SageMakerのセットアップ」までは前回の記事を参照ください。
今回も事前にラベルが付けられたMNISTのデータセットを利用します。
2. オーサリング
学習データの用意
import utils
from tensorflow.contrib.learn.python.learn.datasets import mnist
import tensorflow as tf
data_sets = mnist.read_data_sets('data', dtype=tf.uint8, reshape=False, validation_size=5000)
utils.convert_to(data_sets.train, 'train', 'data')
utils.convert_to(data_sets.validation, 'validation', 'data')
utils.convert_to(data_sets.test, 'test', 'data')
mnistデータセットをワークディレクトリ'data'にダウンロードし、読み込んだデータセットオブジェクトをdata_setsにセットします。 utilsのconvert_toで、tfrecords形式に変換する処理を行います。第2引数はファイル名、第3引数はディレクトリで、'data/train.tfrecords'のようにファイルが出来上がります。
学習データのS3へのアップロード
inputs = sagemaker_session.upload_data(path='data', key_prefix='data/mnist')
S3の'data/mnist'キーに'data'ディレクトリからファイルをアップロードします。 sagemaker_session.upload_dataを使うことで手軽にS3へアップロードすることができます。 bucket引数を指定しない場合には、bucket名が自動的に決められます。引数を指定する場合には、そのbucketが使われます。
3. トレーニング・評価処理の定義
モデル定義
TensorFlowの具体的なモデルを定義する方法を見ていきます。 SageMakerでTensorFlowのモデルを自ら定義する場合には、Estimatorというトレーニングや評価、推論などで決まった処理を抽象化した標準的なインターフェースがあります。
Estimatorでは、model_fn関数でモデルや学習アルゴリズムを定義していきます。 他に次のような関数を定義する必要があります。 TensorFlowのプログラミングガイドEstimatorsが参考になります。
| 関数 | 内容 |
|---|---|
| model_fn | モデル・学習アルゴリズムの定義 |
| train_input_fn | 学習データの読み込み・前処理 |
| eval_input_fn | 評価データの読み込み・前処理 |
| serving_input_fn | 予測でモデルの入力データ型に変換する処理など定義 |
今回のサンプルプログラムでは、Estimatorを使います。他にKerasを利用する方法があります。Kerasのときは、keras_model_fn関数を定義します。
jupyter notebookとは別に用意されているmnist.pyでモデルが定義されています。以下がコードの内容です。
import os
import tensorflow as tf
from tensorflow.python.estimator.model_fn import ModeKeys as Modes
INPUT_TENSOR_NAME = 'inputs'
SIGNATURE_NAME = 'predictions'
LEARNING_RATE = 0.001
def model_fn(features, labels, mode, params):
# Input Layer
input_layer = tf.reshape(features[INPUT_TENSOR_NAME], [-1, 28, 28, 1])
# Convolutional Layer #1
conv1 = tf.layers.conv2d(
inputs=input_layer,
filters=32,
kernel_size=[5, 5],
padding='same',
activation=tf.nn.relu)
# Pooling Layer #1
pool1 = tf.layers.max_pooling2d(inputs=conv1, pool_size=[2, 2], strides=2)
# Convolutional Layer #2 and Pooling Layer #2
conv2 = tf.layers.conv2d(
inputs=pool1,
filters=64,
kernel_size=[5, 5],
padding='same',
activation=tf.nn.relu)
pool2 = tf.layers.max_pooling2d(inputs=conv2, pool_size=[2, 2], strides=2)
# Dense Layer
pool2_flat = tf.reshape(pool2, [-1, 7 * 7 * 64])
dense = tf.layers.dense(inputs=pool2_flat, units=1024, activation=tf.nn.relu)
dropout = tf.layers.dropout(
inputs=dense, rate=0.4, training=(mode == Modes.TRAIN))
# Logits Layer
logits = tf.layers.dense(inputs=dropout, units=10)
# Define operations
if mode in (Modes.PREDICT, Modes.EVAL):
predicted_indices = tf.argmax(input=logits, axis=1)
probabilities = tf.nn.softmax(logits, name='softmax_tensor')
if mode in (Modes.TRAIN, Modes.EVAL):
global_step = tf.train.get_or_create_global_step()
label_indices = tf.cast(labels, tf.int32)
loss = tf.losses.softmax_cross_entropy(
onehot_labels=tf.one_hot(label_indices, depth=10), logits=logits)
tf.summary.scalar('OptimizeLoss', loss)
if mode == Modes.PREDICT:
predictions = {
'classes': predicted_indices,
'probabilities': probabilities
}
export_outputs = {
SIGNATURE_NAME: tf.estimator.export.PredictOutput(predictions)
}
return tf.estimator.EstimatorSpec(
mode, predictions=predictions, export_outputs=export_outputs)
if mode == Modes.TRAIN:
optimizer = tf.train.AdamOptimizer(learning_rate=0.001)
train_op = optimizer.minimize(loss, global_step=global_step)
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)
if mode == Modes.EVAL:
eval_metric_ops = {
'accuracy': tf.metrics.accuracy(label_indices, predicted_indices)
}
return tf.estimator.EstimatorSpec(
mode, loss=loss, eval_metric_ops=eval_metric_ops)
def serving_input_fn(params):
inputs = {INPUT_TENSOR_NAME: tf.placeholder(tf.float32, [None, 784])}
return tf.estimator.export.ServingInputReceiver(inputs, inputs)
def read_and_decode(filename_queue):
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
features={
'image_raw': tf.FixedLenFeature([], tf.string),
'label': tf.FixedLenFeature([], tf.int64),
})
image = tf.decode_raw(features['image_raw'], tf.uint8)
image.set_shape([784])
image = tf.cast(image, tf.float32) * (1. / 255)
label = tf.cast(features['label'], tf.int32)
return image, label
def train_input_fn(training_dir, params):
return _input_fn(training_dir, 'train.tfrecords', batch_size=100)
def eval_input_fn(training_dir, params):
return _input_fn(training_dir, 'test.tfrecords', batch_size=100)
def _input_fn(training_dir, training_filename, batch_size=100):
test_file = os.path.join(training_dir, training_filename)
filename_queue = tf.train.string_input_producer([test_file])
image, label = read_and_decode(filename_queue)
images, labels = tf.train.batch(
[image, label], batch_size=batch_size,
capacity=1000 + 3 * batch_size)
return {INPUT_TENSOR_NAME: images}, labels
model_fnでは、入力層、Convolution-ReLU-max poolingの組み合わせを2層、全結合層、出力層のシーケンシャルなニューラルネットワークを定義しています。
コスト関数(loss)では、以下の箇所でsoftmax_cross_entropyが使われていることが分かります。ラベルデータは、cross_entropyの計算を簡単にするためにone_hotベクトルに変換して渡します。
loss = tf.losses.softmax_cross_entropy(
onehot_labels=tf.one_hot(label_indices, depth=10), logits=logits)
トレーニングのオプティマイザ(最適化アルゴリズム)はAdamを使っています。
optimizer = tf.train.AdamOptimizer(learning_rate=0.001)
例ではmodel_fnでモデル定義・データセット読み込みを行っていますが、再利用性を高める目的でモデル定義・データセット読み込みなどの処理はファイルを分割することが AWS クラウドサービス活用資料集 SageMakerで推奨されています。
分散トレーニングⅠ
分散トレーニングが行われると、複数のトレーニングジョブのインスタンスに同じモデルが転送されます。各インスタンスは、データセットをバッチ毎にロス値を計算し、ロス値をオプティマイザで最小化します。このプロセスのループ全体をトレーニングステップと呼びます。
model_fnの中のtrain_opを定義する行に注目するポイントがあります。
train_op = optimizer.minimize(loss, global_step=tf.train.get_or_create_global_step())
global_stepは、インスタンス間で共有されるグローバル変数です。分散トレーニングには必要です。オプティマイザでは各インスタンスで実行中のトレーニングステップ数をトレースして、重複なくステップ数の割り振りを行います。
Pre-made Estimator
Estimatorには、次のような抽象化された高レベル Pre-made Estimatorがあります。
| 関数 | 内容 |
|---|---|
| tf.estimator.LinearClassifier | 線形分類モデル |
| tf.estimator.LinearRegressor | 線形回帰モデル |
| tf.estimator.DNNClassifier | ニューラルネットワークの分類モデル |
| tf.estimator.DNNRegressor | ニューラルネットワークの回帰モデル |
| tf.estimator.DNNLinearCombinedClassifier | ニューラルネットワークと線形関数を組み合わせた分類モデル |
| tf.estimator.DNNLinearCombinedRegressor | ニューラルネットワークと線形関数を組み合わせた回帰モデル |
抽象化されたPre-made Esitimatorを使う場合には、model_fnの変わりにestimator_fnを定義します。 Pre-made Estimatorはニューラルネットワークのレイヤやユニットを細かく定義することなく簡単に決まったモデルを作ることができます。
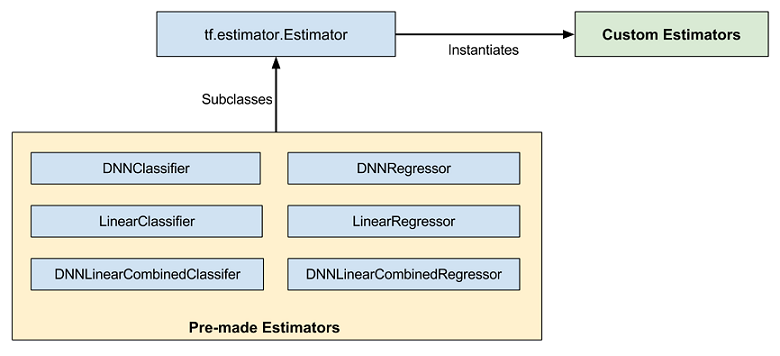
引用元 Creating Custom Estimators in TensorFlow
4. トレーニング開始
次に定義したモデルをトレーニングするには、SageMakerで用意しているTensorFlowクラスでトレーニングジョブを定義します。
from sagemaker.tensorflow import TensorFlow
mnist_estimator = TensorFlow(entry_point='mnist.py',
role=role,
training_steps=1000,
evaluation_steps=100,
train_instance_count=1,
train_instance_type='ml.p2.xlarge')
引数entry_pointに先ほどの必須の関数を定義したファイル名を設定します。 entry_pointで指定したファイルの場所は、source_dir引数で変更が可能です。必須の関数以外を再利用性の目的で分割している場合、source_dirに配置させることができます。
分散トレーニングⅡ
インスタンス数(train_instance_count)を2以上に設定すると分散トレーニングが行えます。インスタンスの数だけトレーニング処理が分散され、トレーニング時間を短縮できます。1台で処理する時間を単純に台数で割った時間よりもネットワーク負荷などのノードで協調する時間などオーバーヘッドで若干長くかかることがあります。
今回のサンプルでは、p2.xlargeで1と設定しています。1としている理由はアカウントのリソースに制限があるためです。(下記の リソースの制限 を参照)
fitを呼び出すことで、インスタンスにジョブが作成され、トレーニングが始まります。
mnist_estimator.fit(inputs)
このインスタンスはS3バケットにcheckpointを書き込みます。このcheckpointはトレーニングジョブの復元を行い、トレーニングを再開することが可能になります。
ジョブが完了すると、notebookのログに評価結果のロス値や精度、モデルがS3へ保存されたことが確認できます。
ログはCloudWatchでも確認することができます。
トレーニング結果のログ
executing startup script (first run)
2018-03-01 12:01:55,813 INFO - root - running container entrypoint
2018-03-01 12:01:55,814 INFO - root - starting train task
2018-03-01 12:01:58,394 INFO - botocore.vendored.requests.packages.urllib3.connectionpool - Starting new HTTP connection (1): 169.254.170.2
2018-03-01 12:01:59,411 INFO - botocore.vendored.requests.packages.urllib3.connectionpool - Starting new HTTPS connection (1): s3.amazonaws.com
2018-03-01 12:01:59,687 INFO - botocore.vendored.requests.packages.urllib3.connectionpool - Starting new HTTPS connection (1): s3.amazonaws.com
INFO:tensorflow:----------------------TF_CONFIG--------------------------
INFO:tensorflow:{"environment": "cloud", "cluster": {"master": ["algo-1:2222"]}, "task": {"index": 0, "type": "master"}}
INFO:tensorflow:---------------------------------------------------------
INFO:tensorflow:going to training
2018-03-01 12:01:59,784 INFO - root - creating RunConfig:
2018-03-01 12:01:59,784 INFO - root - {'save_checkpoints_secs': 300}
2018-03-01 12:01:59,784 INFO - root - invoking estimator_fn
以下省略
評価結果のログ
... INFO:tensorflow:Evaluation [97/100] INFO:tensorflow:Evaluation [98/100] INFO:tensorflow:Evaluation [99/100] INFO:tensorflow:Evaluation [100/100] INFO:tensorflow:Finished evaluation at 2018-03-02-05:55:04 INFO:tensorflow:Saving dict for global step 1000: accuracy = 0.9872, global_step = 1000, loss = 0.038714964 以下省略
精度(accuracy)が0.9872、lossが0.0387であることが分かります。
TensorBoard
トレーニング結果を確認するには、notebookのログやCloudWatchを見ることの他にTensorBoardを利用できます。 fitの引数にrun_tensorboard_locally=Trueを付けて実行します。このオプションにより、checkpointにジョブのメトリクス分析で使用する出力を書き出すことができます。
mnist_estimator.fit(inputs, run_tensorboard_locally=True)
https://notebook-instance.aws/proxy/6006/ でTensorBoardにアクセスできるようになります。
notebookが実行されているマシンでTensorBoardを実行します。ジョブによって新しいcheckpointがS3バケットに作成されるたびに、TensorBoardが指定している一時ディレクトリにcheckpointがダウンロードされます。
リソースの制限
MLタイプのp2.xlargeインスタンスは同時に稼動できる数がデフォルトで1台に制限されています。 必要であれば、制限の引き上げをAWSにリクエストすることができます。
| リソース | デフォルトの制限 |
|---|---|
| ml.m4.xlarge | 20 |
| ml.c4.xlarge | 20 |
| ml.p2.xlarge | 1 |
この表はデフォルトの制限の一部分になります。全容はAmazon SageMaker の制限を参照ください。
並列ジョブ実行
並列にジョブの作成・実行する際にはjupyter notebookの外で行う必要があり、別のnotebook、SageMakerのWebコンソール、またはCreateJobのAPIで呼び出すことになります。
例えば、AWS LambdaとAWS StepFunctionsを利用して、ジョブの作成とトレーニングなどの処理をLambdaで、その後のDeployを別のLambdaで行い、StepFunctionsでこれらのLambdaを逐次実行することができます。また、この一連のLambdaを複数同時並行に実行させることもできます。
5. ホスティング
endpointにデプロイ
独自のアプリケーションが入ったDockerイメージをカスタマイズして、これまでトレーニングしたモデルを使ったリアルタイム推論の環境を構築できます。 その上で、アプリのA/Bテストなどを行えます。 Dockerイメージを指定せずに、APIのエンドポイントをホスティングすることもできます。
モデルをエンドポイントにデプロイします。
mnist_predictor = mnist_estimator.deploy(initial_instance_count=1,
instance_type='ml.m4.xlarge')
deployの引数で、リクエスト・レスポンスのフォーマットを変えるときはserializer, deserializerで変更ができます。TensorFlowでは、Protocol Buffersフォーマットが使われています。他にJSON、CSVが選べます。
実行結果はこちら
INFO:sagemaker:Creating model with name: sagemaker-tensorflow-py2-gpu-2018-03-02-04-45-08-792 INFO:sagemaker:Creating endpoint with name sagemaker-tensorflow-py2-gpu-2018-03-02-04-45-08-792
次にpythonコードから予測を実行する場合の例になります。 テストデータから10件取り出して、1件づつ予測結果を取り出してラベルと一緒に表示します。
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
for i in range(10):
data = mnist.test.images[i].tolist()
tensor_proto = tf.make_tensor_proto(values=np.asarray(data), shape=[1, len(data)], dtype=tf.float32)
predict_response = mnist_predictor.predict(tensor_proto)
print("========================================")
label = np.argmax(mnist.test.labels[i])
print("label is {}".format(label))
prediction = predict_response['outputs']['classes']['int64Val'][0]
print("prediction is {}".format(prediction))
mnistデータセットを読み込み、実データとラベルのnumpyの配列形のデータに変換します。 次にTensorProto(TensorのProtocol Buffers表現)に変換し、 デプロイして出来たエンドポイントに、テストデータを引数として予測を実行します。
次の行で、mnist.pyのpredictorオブジェクトのpredictを実行しています。
predict_response = mnist_predictor.predict(tensor_proto)
予測結果はこちら
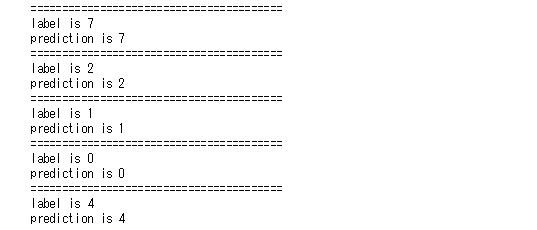
ラベルに対する予測が出力されています。同じ値ですべて的中していることが分かります。
TensorProtoに変換する処理などの予測時に前処理をモデル側に作ることもできます。
| 関数 | 内容 |
|---|---|
| input_fn | 入力データに対する前処理 |
| output_fn | 予測結果の出力に対する前処理 |
推論する環境が不要になった場合、エンドポイントを削除します。
sagemaker.Session().delete_endpoint(mnist_predictor.endpoint)
さいごに
今回はTensorFlowを使ったモデルを定義するところから、トレーニングし、エンドポイントにデプロイし予測結果を確認するところまで見てきました。
SageMakerを使うことで、TensorFlowで作ったモデルを分散トレーニングさせることや、ハイパーパラメータを変えてモデルを並列にトレーニングさせることが手軽にできることがわかったかと思います。
価格について
オンデマンド価格より高価なMLタイプのインスタンスを使うことになり、機械学習環境を整備することと割り増し料金はトレードオフの関係になります。
特にBuilt-inアルゴリズムを使う場合にはモデル定義や学習環境も作らずに手軽にトレーニングが行え、すぐにアプリケーションに組み込むことができます。十分にコストに見合う価値があると感じました。TensorFlowの場合には分散トレーニングが容易にできることが魅力的で使う価値は十分あると思います。
今回紹介出来なかったカスタムアルゴリズムの場合には、Dockerイメージから手組みする手間は容易ではなく、コストに見合う利用価値があるかは厳しいと感じています。
今後
AI自身がデータの特性に合わせてモデルを定義しパラメータをチューニングするAutoMLサービスをGoogleが去年発表しています。 先月からAWSでも、自動的にハイパーパラメータを探索するHyper-Parameter Optimizer(HPO)がSageMakerのAlpha版機能として一部のユーザに試行されはじめています。 近々、この便利な機能が一般公開されるはずです。
機械学習の技術向上に伴うマネージドサービスやフレームワークの機能拡張が著しく、今後も目が離せません。
本文中のソースコードは、以下に公開されている “amazon-sagemaker-examples"より引用しています。
https://github.com/awslabs/amazon-sagemaker-examples
また、"amazon-sagemaker-examples” は Apache License 2.0 が適用されています(2018年3月現在)。
Apache License 2.0 の内容は以下を参照ください。
https://www.apache.org/licenses/LICENSE-2.0