
前回の量子計算入門(理論編)では量子コンピュータの計算原理を学びました。今回はいよいよ本物の量子コンピュータを動かします。といっても、実際に量子コンピュータを使うにはまだ説明できてないことがたくさんあるので、それらをざっと説明してからになります。前回より長旅になりますが、どうぞ最後までお付き合いください。
目次
1. はじめに
前回記事ではゲート方式の量子コンピュータが行う計算についての基礎理論をまとめました。今回は本物の量子コンピュータを動かし、結果を評価するところまで丁寧に説明します。
量子コンピュータを動かすと言っても、量子性の確認や有名な量子アルゴリズムの実装については、量子コンピュータ提供ベンダーの公式ドキュメントや個人のブログ記事にまとめられていたり GitHub にコードが公開されていたりするので扱いません。
量子コンピュータを動かすためのソフトウェアが充実してきた代償として、量子コンピュータのハードウェアに依存したアナログな性質を意識しにくくなっていると感じています。少し前までは数量子ビットしか使えなかったので、それを大事に扱っていました。今では無料で 100 量子ビット以上使えてしまうので、ある意味雑に扱っているようにも感じます。
そこで、量子コンピュータがアナログな機械であることを念頭に、本記事では量子回路の最適な設計を目指して基礎的なことやソフトウェアを使う上での注意点をまとめていきます。本記事の内容を押さえておかないと量子コンピュータの性能をまったく発揮させることができず、量子コンピュータはまだまだ役に立たないという言説につながる可能性もあります。
著者の個人的な思いとしては、役に立つ云々よりも今の量子コンピュータの性能を正しく評価・理解できるようになることが重要と考えています。
ひとつ注意して頂きたいのは、今回は IBM の量子コンピュータを使うため本記事内で量子コンピュータと言えば超電導型の量子コンピュータを指すものとします。超電導型以外にもイオントラップ型や光量子型などありますが、それらについては言及しません。誤解を生む可能性があるため、本記事で説明するハードウェアに関する内容は超電導型にのみ当てはまるものとお考えください。
また、本記事は独立して読めるよう配慮していますが、前回記事を参照している箇所があります。もし説明が不十分で伝わらないことがあれば前回記事も合わせてお読みいただければ幸いです。
2. プログラミングの準備
量子コンピュータは(2024年3月現在)無料で利用可能な IBM のマシンを使います。ソースコードは Google Colaboratory 上で実行可能なものを載せています。一方で、それらの利用手続きについては記載しておりませんので、あらかじめ公式サイトを参考にアカウント開設していただければと思います。
2.1. 環境構築
今回は理論の説明を実際にプログラミングして確認しながら進めます。その準備として Google Colaboratory 上で環境構築しておきます1。
まずは Google Colaboratory をブラウザで開きます。
【ここをクリックすると新しいノートブックが別タブで開きます】
次に、今回使うライブラリをインストールします。
- qiskit:量子コンピューティングのためのオープンソースフレームワーク
!pip install qiskit[visualization]
量子コンピューティングのためのフレームワークは色々ありますが、IBM の研究開発部門である IBM Research が開発に携わっている qiskit を使います。ちょうどこの記事を書き始めたタイミングで安定版である 1.0.0 がリリースされました。この記事を書いた後でプログラムが動かなくなるような破壊的な変更は少ないと信じて進めていきます。
- qiskit-ibm-runtime: IBM の量子コンピューティングプラットフォームを使うためのライブラリ
!pip install qiskit-ibm-runtime
こちらのライブラリは qiskit のプラグイン的なもので、IBM Quantum Platform 上でのシミュレータ稼働や本物の量子コンピュータ(実機)を動かすために必要です。
ちなみに、今回の記事を執筆している時点で最新のライブラリバージョンは以下のようになっています。
import qiskit qiskit.version.get_version_info() # => 1.0.2
import qiskit_ibm_runtime qiskit_ibm_runtime.version.get_version_info() # => 0.22.0
qiskit_ibm_runtime の方はまだバージョン 1.0 が出ておらず、下位互換性のない変更がありうることに注意してください。もしバージョンが上がったことが原因で動かないプログラムがあれば、以下のようにバージョンを指定してインストールすることで解決するかもしれません。
!pip install qiskit-ibm-runtime==0.22.0
ただし、量子コンピュータの実機側の設定変更で動かないこともありうるので、どうしても動かないことがあれば公式ドキュメントを参考にしてください。
2.2. 量子コンピュータを使う準備
量子コンピュータを動かすためにはライブラリのインストールだけでなく、IBM Quantum Platform 上で発行される API トークンが必要です。API トークンを取得するためにはアカウント登録が必要ですので、実際に試される方はアカウント登録をしてください。
IBM Quantum Platform にサインインするとダッシュボードやアカウント設定のページで API トークンを確認できます。ダッシュボードの見た目は今後変わる可能性がありますが、現時点では右上に「API Token」と表示されています。
そこから API トークンをコピーしたら、次のコードを実行してみてください。
from qiskit_ibm_runtime import QiskitRuntimeService API_TOKEN = "【ここには自身の API トークンをコピペしてください】" service = QiskitRuntimeService(channel="ibm_quantum", token=API_TOKEN) service.backends()
正常に動作していれば以下のような結果が得られます(結果は実行のたびに順不同です)。
[<IBMBackend('simulator_stabilizer')>,
<IBMBackend('ibm_brisbane')>,
<IBMBackend('ibm_kyoto')>,
<IBMBackend('ibm_osaka')>,
<IBMBackend('ibmq_qasm_simulator')>,
<IBMBackend('simulator_extended_stabilizer')>,
<IBMBackend('simulator_mps')>,
<IBMBackend('simulator_statevector')>]
これは無償で利用可能なシミュレータと実機のリストです2。仕様変更により変わる部分なので、あくまで現時点(2024 年 4 月時点)でのものになります。実機は ibm_ から始まっているものです。上のリストのうち 'ibm_brisbane' と 'ibm_kyoto'、'ibm_osaka' が実機です。ブリスベン(オーストラリアの都市)と京都、大阪のように都市名が付いていますが、実際にそこに置いてあるわけではありません。日本には神奈川県川崎市に実機があることが知られています。ブラウザから IBM Quantum Platform にアクセスすると実機の状態を確認できるのですが、'ibm_kawasaki' というマシンがその日本にある実機だと思われます。
3. 量子回路の設計方法
前回記事で量子計算の基礎理論はおさえましたが、実機を使うにあたってハードウェアに依存した諸事情が多々あります。本章ではプログラミングしながらそのあたりを追っていきます。qiskit ライブラリの使い方入門にもなっているので、ご自身で色々試したい方はソースコードの中身も丁寧に見ていただければと思います。
3.1. 量子チップのアーキテクチャ構造
超電導型量子コンピュータの実体となる量子チップにはさまざまなアーキテクチャ構造があります。ここでいうアーキテクチャ構造というのは量子ビット同士の結合構造のことで、今回使う実機は下図のような構造になっています3。色の違いは量子ビットの性能を表していますが、ここでは気にする必要はありません。

この量子チップには全部で 127 量子ビットもあるのですが、隣り合う量子ビットの数はせいぜい 3 つです4。
しかし、2量子ビットゲートの入力となる量子ビットのペアは結合している必要があります。量子計算では2量子ビットゲートによるもつれ状態の生成が重要な役割を果たすので、結合したペアでないと2量子ビットゲートが使えないというのは大きな制約です。
3.2. スワップゲート
そこで登場するのがスワップゲートになります。
具体例として、量子ビット 0(q0)と量子ビット 1(q1)は結合しているが、q0 と量子ビット 2(q2)は結合していない状況を考えます。この状況で H0 をした後に CNOT0,1 と CNOT0,2 を操作します。
結合を無視してゲート操作をプログラムで書くと以下のようになります。
from qiskit.circuit import QuantumCircuit
qc = QuantumCircuit(3) # |0〉に初期化された量子ビット3つの量子回路
qc.h(0) # H ゲート
qc.cx(0, 1) # cx は CNOT ゲートのこと
qc.cx(0, 2)
qc.draw('mpl') # 量子回路を描画

q0 と q2 が直接結合してない状況ではこの量子回路は実行できません。簡単な解決策は CNOT0,2 を操作する直前に q1 と q2 を入れ替えてしまうことです。もしくは q0 と q1 の入れ替えです。この入れ替え操作を行うのがスワップゲートになります。
3.3. トランスパイル
スワップゲートは実機の結合構造に応じて量子回路に明示的にプログラムする必要はありません。実機利用前に必須のトランスパイルという処理が自動でスワップゲートを付加してくれます。トランスパイルという言葉はあるプログラミング言語を他のプログラム言語に変換する処理のことです。量子コンピュータにおけるトランスパイルは実機で利用できる形式に変換する処理を指します。
トランスパイルは以下のように実行できます5。
from qiskit.compiler import transpile
transpiled_qc = transpile(qc, coupling_map=[[0,1], [1,2]], optimization_level=0) # 最適化はしない
transpiled_qc.draw('mpl')
ここでは実機を指定せずに、coupling_map という引数で量子ビットの結合構造を指定しています。上で述べたように q0 と q1、q1 と q2 が結合している状況を設定しています。もうひとつの引数である optimization_level は後ほど説明します。
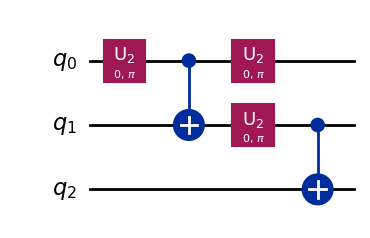
プログラムの実行結果はランダムに以下どちらかの量子回路になりました。
![]()
![]()
これらトランスパイルされた量子回路には想定通りスワップゲートが付加されています。CNOT0,2 の分解に着目すると、次の関係式が成り立っていることが分かります。

3.4. スワップゲートの行列表現
ここでスワップゲートの操作をもう少し具体的に説明します。
2量子ビット状態の一般形は

と書けます。この状態に対し、量子ビットを入れ替えた状態は以下のようになります。

この2つの量子状態の違いは |01〉と |10〉の係数が逆になっているだけです。スワップゲートにより |01〉と |10〉を入れ替えることができれば、2つの量子ビットを交換したことになります。
このスワップゲートを行列で書くと

です。この行列は上から |00〉、|01〉、|10〉、|11〉の状態に対する操作で、|00〉と |11〉はそのままにしつつ |01〉と |10〉を入れ替えます。
ところで、ユニバーサルゲートセットの中に2量子ビットゲートは CNOT ゲートだけでした。つまり、スワップゲートは CNOT ゲートに分解できます。結果を先に示すと、以下のように分解されます。

前回のおさらいですが、CNOT ゲートの行列表現は制御量子ビット qi と対象量子ビット qj に対して

でした。これは |10〉と |11〉の入れ替えになっています。
制御量子ビットと対象量子ビットが逆の場合は |01〉と |11〉の入れ替えになり、行列で書くと

です。
これらを元に計算すると、上で示したスワップゲートを CNOT ゲート3つで分解した等式が得られます。

このスワップゲートの分解はプログラムでは以下のように確かめられます。
decomposed_qc = transpiled_qc.decompose()
decomposed_qc.draw('mpl')
上記2通りの量子回路に対してそれぞれ以下のように分解されます。
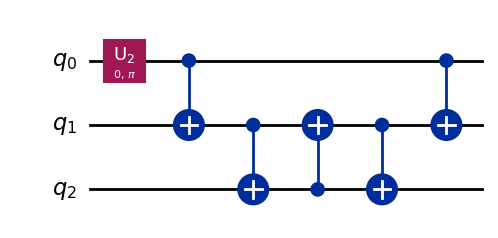
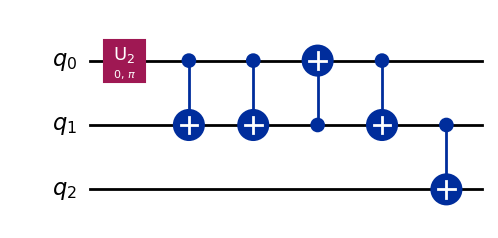
スワップゲートは真ん中3つの CNOT ゲートに分解されています。最初の U2 ゲートは H ゲートを一般化したもので、中身は変わっていません。
3.5. 量子回路の深さ
これまで見た例は3量子ビットしかない簡単な量子回路でしたが、大規模な量子回路だとスワップゲートだらけになることが予想されます。
そのスワップゲートの入れ方も3量子ビットの場合ですら2通りが可能でした。
ゲートを色々置き換えた結果、一連のゲート操作が何もしないことと同じだったり、より少ないゲート数で置き換えることができたりもします。
量子回路はある特定の量子状態を作ることが目的で、そのための操作手順は問いません。であれば、量子回路はなるべく少ないゲートで実現したいなとなります。
というのも、今の量子コンピュータはゲート操作のエラー率が高く、誤り訂正できるほどビット数も多くありません。原理的にはできる計算もゲート数が多過ぎるとエラーが重なりただのランダムノイズ(まったくのでたらめな結果)になってしまいます。
仮にゲート操作のエラーがなかったとしても効率良く計算させるためにはゲート操作は少ない方が良いです。
いずれにせよ量子回路は最適化してゲート数を減らすというのが非常に重要になります。より正確にはゲート数ではなく深さと呼ばれる単位が少ない方が良いとされます。量子回路の深さは図でいうと横幅に対応します。
上述の量子回路に対する深さは以下のようになっています。
print(qc.depth()) # => 3 print(transpiled_qc.depth()) # => 4 print(decomposed_qc.depth()) # => 6
3.6. 量子回路の最適化
ところで、先ほどトランスパイルをするときに optimization_level を 0 にしていました。これは量子回路を浅くする最適化はしないという指定です。optimization_level は 1, 2, 3 と上げていくと時間は掛かりますが、より最適解が出やすくなると期待されます。
実際に試してみると2種類の結果が得られました。
transpiled_qc2 = transpile(qc, coupling_map=[[0,1], [1,2]], optimization_level=3) # 最適化あり
transpiled_qc2.draw('mpl')
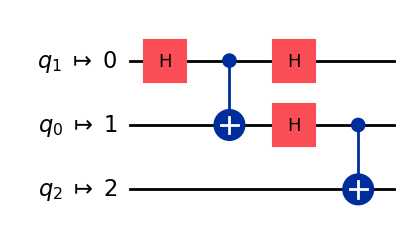
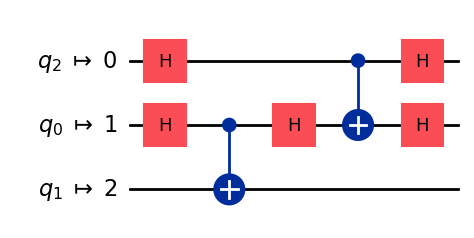
最適化なしだとスワップゲートが追加されましたが、最適化ありだとスワップゲートは使われませんでした。これらの量子回路は分解すると以下のようになります。
decomposed_qc2 = transpiled_qc2.decompose()
decomposed_qc2.draw('mpl')
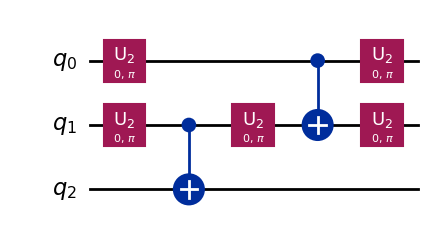
H ゲートが U2 ゲートで表現されただけで量子回路に変化はありません。量子回路の深さはそれぞれ 4 と 5 です。最適化なしでスワップゲートが追加された量子回路は分解後の深さが 6 だったので、最適化することで量子回路が浅くなったことが分かります。
しかし、これで最適化万歳\(^o^)/となるのは不適切です。
実は今回の量子回路だと、スワップゲートは不要で、最適化によるゲート追加も不要です。同じ量子状態を作る一番浅い回路は以下になります。
qc2 = QuantumCircuit(3)
qc2.h(0)
qc2.cx(0, 1)
qc2.cx(1, 2) # cx(0, 2) から変更
qc2.draw('mpl')

トランスパイルしても分解しても量子回路は変わらず、深さは 3 のままです。最適化した量子回路の深さが 4 と 5 だったので、こちらの量子回路の方が浅いです。
この量子回路が当初の量子回路と同じ量子状態を実現できるのか確認してみましょう。
まず、プログラムの最初に作った量子回路 qc で得られる状態を計算します。

CNOT0,2 が q0 が 1 の時に q2 を反転させる操作なので、最後の等式で |110〉が |111〉になっています。
ところが、|110〉を |111〉にするだけなら q1 も 1 なので CNOT1,2 でも問題ありません。というわけで

が示せます。これが先ほどのプログラムで定義した qc2 に対応します。
qc と qc2 が等価な量子回路なのか(同じ量子状態を作るのか)は以下のプログラムで確認できます。
from qiskit.quantum_info import Statevector sv = Statevector(qc) sv2 = Statevector(qc2) print(sv.equiv(sv2)) # => True
今回は最適な量子回路を手計算で求めることができたのですが、qiskit ライブラリの提供するトランスパイラでは求めることができませんでした。量子回路の最適化は NP 困難な問題で、それ自体がひとつの研究対象となるくらい難しい問題です。
そのため、トランスパイラに一任するだけでなく、プログラマ自身である程度ムダな計算をさせないよう量子回路を設計した方が賢明です。とはいえ、それは難しい問題なので今回のような基礎的なことは理解しつつ実装する姿勢が大事かと思います。具体的な手法は 5 章で丁寧に説明します。
3.7. 量子ビットの結合方向
ここまで見てきた具体例の状況をもう一度振り返ります。
具体例として、量子ビット 0(q0)と量子ビット 1(q1)は結合しているが、q0 と量子ビット 2(q2)は結合していない状況を考えます。この状況で H0 をした後に CNOT0,1 と CNOT0,2 を操作します。
プログラムでこの結合を表す際に coupling_map=[[0,1], [1,2]] とし、ペアで書いてある 0 と 1(q0 と q1)、1 と 2(q1 と q2)はあたかも等価な関係のように進めていました。
もし結合関係を等価とするなら、以下のように順番を逆にしたペアも書く必要があります。
transpiled_qc3 = transpile(qc, coupling_map=[[0,1], [1,2], [1,0], [2,1]], optimization_level=3) # 結合が両方向
transpiled_qc3.draw('mpl')
このプログラムで得られた量子回路は下図になります。

注意してほしいのは図の一番左の q1 ↦ 0 としている部分です。これまで暗黙裡に q0 は 0 番目の量子ビット、q1 は 1 番目の量子ビットのように考えていましたが6、実機を使う場合は量子回路に応じて最適な量子ビットを割り当てることがとても重要です。
今回の例だと、両方と結合を持つ 1 番目の量子回路を q0 としています。その結果、スワップゲートもなく、素直に CNOT0,1 と CNOT0,2 が実現できています。深さも 3 で最適な量子回路です。
「なんだ、結合構造の設定が間違っていただけで、トランスパイルで最適な量子回路が得られたじゃないか」と思うかもしれませんが、量子ビットの結合関係が等価という前提は正しくありません。
実機における量子ビットの結合関係は次のプログラムで確認できます。ここでは著者が大阪在住なので実機に'ibm_osaka'を指定します。
backend = service.get_backend('ibm_osaka') # 実機指定
backend.coupling_map.draw()

小さくて見づらいかもしれませんが、量子ビットをつなぐ線がすべて単方向の矢印になっています。この矢印の起点となっている量子ビットは制御量子ビットになることができ、矢印の先になっている量子ビットは対象量子ビットになることができます。両方向の矢印でないことに注意してください。
もし等価な結合関係であれば、以下のような図になります。
from qiskit.transpiler import CouplingMap ideal_coupling = CouplingMap([[0,1], [1,2], [1,0], [2,1]]) # 結合が両方向 ideal_coupling.draw()

でも、実際はこうです。
realistic_coupling = CouplingMap([[0,1], [1,2]]) # 結合が単方向 realistic_coupling.draw()

というわけで、実機を想定するなら前節までの単方向のみの coupling_map を指定する方が現実的です。
ただし、0 → 1 → 2 のように繋がっている必要はなく、0 ← 1 → 2 のように 1 を制御量子ビットとして 0 と 2 の両方を対象量子ビットとする結合は可能です。
transpiled_qc4 = transpile(qc, coupling_map=[[1,0], [1,2]], optimization_level=3) # 結合は単方向のみ
transpiled_qc4.draw('mpl')
この量子回路は transpiled_qc3 と同じですが、結合構造は単方向のみです。
3.8. ネイティブゲート
次は実機が扱えるゲートについてです。
原理的にはユニバーサルゲートセットである H ゲート、T ゲート、CNOT ゲートの3つがあれば良いのですが、実機のハードウェアに依存して使えるゲートが異なります。ハードウェア実装の容易さや演算の効率性などを考慮してゲートセットが選ばれていると思われます。それらのゲートは実機依存でネイティブゲートと呼ばれます。
今回使う IBM の実機のネイティブゲートは公式ドキュメントでも確認できますが、次のプログラムでゲート名を取得できます。
backend = service.get_backend('ibm_osaka') # 実機指定
basis_gates = [gate.name for gate in backend.configuration().gates]
for gate in basis_gates:
print(gate.name)
実行すると以下の文字列が出力されます。
id rz sx x ecr reset
この中で次の2つは特殊な操作です。
id:恒等ゲート(何もしない)reset:量子ビットを初期化する(量子状態を |0〉にする)
結局、ネイティブゲートは以下の4つになります。
rz:RZ ゲート(Z 軸周りの任意の角度回転)sx:SX ゲート(X 軸周りの π / 2 回転と位相を除いて等しい)x:X ゲート(X 軸周りの π 回転)ecr:ECR(Echoed Cross-Resonance ゲートと呼ばれる2量子ビットゲート)
RZ ゲートと X ゲートは前回記事で紹介したゲート操作です。最後の ECR ゲートは CNOT ゲートの代わりとなる2量子ビットゲートで、どのような操作になるかは SX ゲートと併せて次章で説明します。
3.9. ネイティブゲートにトランスパイル
前述のトランスパイルでは結合構造を指定しましたが、ネイティブゲートには分解していません。ネイティブゲートへの分解は実機を指定すれば自動で行ってくれます。
native_transpiled_qc = transpile(qc, backend=backend, optimization_level=3) # backend で実機を指定
native_transpiled_qc.draw('mpl', idle_wires=False) # 不使用の量子ビットは表示しない

量子回路で使う量子ビットは前節で示した実機の結合構造を見ると 25 ← 24 → 34 となっていて、最適化により自動で適切な量子ビットが割り当てられています。
もし割り当てられた量子ビットが最適でなければ、以下のように手動で割り当てることもできます。この方法は重要なので、あとで実際に実機を使う際にも使います。
initial_layout = [24, 34, 25] # 0 番目の量子ビットから順に割り当てる量子ビットの番号を指定 native_transpiled_qc = transpile(qc, backend=backend, initial_layout=initial_layout, optimization_level=3) # initial_layout で量子ビットの割り当てを指定
また、上の量子回路図中の √X は SX ゲートのことで、すべてネイティブゲートで表されていることが分かります。実機を使う場合はこのように量子回路をネイティブゲートにトランスパイルしておく必要があります。トランスパイルしていないとエラーで実行失敗になるので注意してください。
3.10. NISQ 時代の量子計算
オリジナルの量子回路でネイティブゲートでないものは、単一のゲートとして記述していてもトランスパイルすると複数のネイティブゲートの組み合わせになりました。これは前回記事でのユニバーサルゲートによる分解と同様です。
上述の例ではオリジナルだと深さは 3 ですが、ネイティブゲートにトランスパイルすると深さは 8 になっています。元が複雑な量子回路だとトランスパイル後により深くなりやすいです。
先ほど量子回路の深さを説明した際に
今の量子コンピュータはゲート操作のエラー率が高く、誤り訂正できるほどビット数も多くありません。原理的にはできる計算もゲート数が多過ぎるとエラーが重なりただのランダムノイズ(まったくのでたらめな結果)になってしまいます。
と述べたように、ネイティブゲートで表される量子回路は深くなり過ぎないように気を付けなければいけません。
この状況を指して、今の量子コンピュータは Noisy Intermediate-Scale Quantum Computer (NISQ) と呼ばれています。それに対して、誤り耐性のある量子コンピュータは Fault Tolerant Quantum Computer (FTQC) と呼ばれます。
この両者のギャップは大きいので78、FTQC に至る前でも実用的な計算ができないかさまざまな研究がされています。たとえば、古典コンピュータが苦手だが量子コンピュータが得意な計算だけ量子コンピュータに任せるという量子古典ハイブリッド計算があります。
量子古典ハイブリッド計算では量子計算と古典計算が柔軟かつ素早く切り替えられる必要があります。以前は、量子計算はベンダーが提供するクラウド上で、古典計算はユーザ側でと分断されており、その間の通信時間や実行待ちなどオーバヘッドが大きく実用的でないというのが一般的でした。
ありがたいことに、現在の IBM Quantum Platform では量子計算と古典計算の両方がクラウド上で実行できるようになっています。量子古典ハイブリッド計算は機会があれば挑戦して本連載でも紹介できればと考えています。
4. 続・演算の理論
前回記事で基本的な演算の理論はまとめましたが、本章では今回使う IBM の量子コンピュータに焦点をあてた話をします。
4.1. SX ゲート
まずネイティブゲートの SX ゲートを説明します。これは X 軸周りの π / 2 回転

と位相を除いて等しい操作で、以下のように表されます。

SX ゲートが X 軸周りの π / 2 回転と等価であることから明らかなように、ブロッホ球で Z 軸上の状態である |0〉と |1〉は SX ゲートを操作すると Y 軸上の状態に移ります。
具体的には

となります。それぞれ最後の等式に現れる重ね合わせ状態には

という略記が使われることが多く、これを見たらブロッホ球の Y 軸上の状態だと感じ取れると良いです。
SX ゲートの操作を整理すると

になります。係数の位相因子はもつれ状態を作る時に無視できないので、この段階で消さないように注意してください。
この状態にさらに SX ゲートを操作すると、計算は省きますが

が示せます。その結果 SX ゲートを2回続けて操作すると |0〉は |1〉に、|1〉は |0〉になります。これは X ゲートの操作に等しく、SX ゲートが √X(Square-root X)ゲートと呼ばれる理由になっています。
4.2. SX ゲート操作をブロッホ球で確認
数式だけだとイメージがわかないので、ブロッホ球で描画しながら SX ゲートの操作を確認してみます。
まず量子ビットを2つ用意し、それぞれ |0〉と |1〉にします。
from qiskit.visualization import plot_bloch_multivector qc = QuantumCircuit(2) # q0: |0〉 qc.x(1) # q1: |0〉を |1〉に変換 plot_bloch_multivector(Statevector(qc))

次にこれらの状態に SX ゲートを操作します。
qc.sx(0) # q0: |0〉に SX ゲート qc.sx(1) # q1: |1〉に SX ゲート plot_bloch_multivector(Statevector(qc))

左が y = -1 なので |-i〉、右が y = +1 なので |+i〉を表しています。
続けて SX ゲートを操作すると
qc.sx(0) # q0: |-i〉に SX ゲート qc.sx(1) # q1: |+i〉に SX ゲート plot_bloch_multivector(Statevector(qc))

Z 軸上の状態に戻って、元の |0〉と |1〉の状態が反転したことが分かります。
これは非常に簡単な例ですが、プログラム上は色々なゲートが用意されているので、それらがどんな操作か確かめるのにブロッホ球を描画すると直感的に理解できると思います。
4.3. 複数量子ビット状態を表す記法
次に IBM の実機で使える2量子ビットゲートの説明をします。
ただ、その前に注意したいのが複数量子ビットの状態を表す記法が2種類あることです。これまで一貫して Big-Endian と呼ばれる記法を使っていました。Endian というのはビット値の並べ方のことです。
Big-Endian では N 量子ビットの状態を 0 番目から N - 1 番目の量子ビット状態を左から順に並べます。

もうひとつの記法である Little-Endian では右から順に並べます。

量子コンピュータの理論では Big-Endian で書かれていることが多いので、本連載でもそれに倣っています。一方で、qiskit ライブラリは Little-Endian を標準としています。
簡単な例で違いを見てみましょう。すべての量子ビットが |0〉に初期化されている状態から X0 ゲートを操作します。結果は Endian ごとに以下の表記になります。

qiskit のデフォルトでは後者の Little-Endian ですが、本連載では Big-Endian を使うので注意してください。Endian の違いを認識していないと期待された結果にならないと誤解することになるので要注意です。
4.4. ECR(Echoed Cross-Resonance) ゲート
それでは IBM の実機で使える2量子ビットゲートである ECR ゲートについてです。
ECR ゲートは行列で書くと次のような操作です。

これは Big-Endian での表記です。公式ドキュメントの API reference に書かれているのは Little-Endian の表記で、Note としてメモ的に記載されている方が Big-Endian の表記です。
行列で見ただけだと分かりにくいので、どういう量子状態を作るのかプログラムで確かめてみます。
def make_ecr_circuit(xs=[]):
qc = QuantumCircuit(2)
for x in xs:
qc.x(x) # |0〉を |1〉に反転
qc.ecr(0,1)
return qc
qc_00 = make_ecr_circuit() # |00〉に ECR ゲート
qc_01 = make_ecr_circuit(xs=[1]) # |01〉に ECR ゲート
qc_10 = make_ecr_circuit(xs=[0]) # |10〉に ECR ゲート
qc_11 = make_ecr_circuit(xs=[0,1]) # |11〉に ECR ゲート
次にこれらの量子回路で得られる2量子ビット状態を表示します。もつれた量子状態を表す可視化関数もありますが、今回は数式で表示します。
ノートブックの同じセルで実行すると最後の実行結果しか表示されないので、下記 show_statevector() 関数はそれぞれ別のセルで実行してください。
def show_statevector(qc):
sv = Statevector(qc).reverse_qargs() # Big endianで表示
return sv.draw('latex')
show_statevector(qc_00)
show_statevector(qc_01)
show_statevector(qc_10)
show_statevector(qc_11)
出力は以下の等式における最初の右辺です。そこから先の式変形は分かりやすく整理したものです。

これらの状態は最右辺が1項だけで書けていることから、もつれ状態ではありません。もつれ状態を作る方法については次章で説明します。
また、ECR ゲートを2回続けて操作すると元の量子状態に戻ります。これは ECR ゲートの行列を2乗すると恒等ゲートになることから確認できます。
この性質から上の4つの等式に再度 ECR ゲートを操作すると以下の等式が得られます。

これらの等式を覚える必要はありませんが、一覧にまとめておくと量子回路を設計するときに役に立つと思います。本章で求めた等式のいくつかは次章の説明で参照します。
5. 量子回路作成の実践
本章では量子計算で重要なもつれ状態を作る方法を説明します。単に作るだけであれば重ね合わせ状態を作ってから CNOT ゲートや ECR ゲートを操作すれば良いのですが、効率良く作る(少ないゲート数で作る)方法を模索します。
5.1. ベル状態生成
前回記事ではもつれ状態の代表例としてベル状態を紹介しました。そこではベル状態をユニバーサルゲートを用いて以下のような量子回路で生成しました。
qc_bell_univ = QuantumCircuit(2)
qc_bell_univ.h(0)
qc_bell_univ.cx(0, 1)
qc_bell_univ.draw('mpl')

トランスパイルすると
transpiled_qc_bell_univ = transpile(qc_bell_univ, backend=backend, optimization_level=3) # 最適化あり
transpiled_qc_bell_univ.draw('mpl', idle_wires=False)
![]()
となります。しかし、深さが 5 のこの量子回路は少しムダがあります。
ネイティブゲートでベル状態を作るなら以下の量子回路が深さ 2 で最小です。
qc_bell_native = QuantumCircuit(2)
qc_bell_native.sx(0)
qc_bell_native.sx(1)
qc_bell_native.ecr(0, 1)
qc_bell_native.draw('mpl')

ネイティブゲートで構成しているので、トランスパイルしてもゲートは変わりません。
transpiled_qc_bell_native = transpile(qc_bell_native, backend=backend, optimization_level=3) # 最適化あり
transpiled_qc_bell_native.draw('mpl', idle_wires=False)
![]()
生成される量子状態は 4.4 節で定義した関数を使って確かめられます。
# 最後の実行結果のみ表示されるので下記2つの関数は別々のセルで実行する show_statevector(qc_bell_univ) show_statevector(qc_bell_native)
出力はどちらも同じです(左辺がオリジナルの出力)。

ネイティブゲートで構成した量子回路の状態変化を手計算でも確認してみます。式変形の各所で前章で求めた等式を使います。
まず 2 量子ビットの初期状態に SX ゲート

次に ECR0,1 ゲート

このように手計算できれば、トランスパイルに頼らずとも最初からネイティブゲートで設計できます。
しかし、量子ビット数が増えると手計算するのも限界があるので、少ない量子ビット数で試してパターンを見出すのが良いかと思います。実際にどのようにやるのかは以下で説明します。
5.2. GHZ 状態生成
3 章で扱っていた 3 量子ビット状態は GHZ 状態(Greenberger-Horne-Zeilinger 状態)と呼ばれます。量子回路は以下でした(3.6 節の qc2 と同じ。変数名だけ変更)。
qc_ghz_univ = QuantumCircuit(3)
qc_ghz_univ.h(0)
qc_ghz_univ.cx(0, 1)
qc_ghz_univ.cx(1, 2)
qc_ghz_univ.draw('mpl')
量子状態も確認しておきます。
show_statevector(qc_ghz_univ)

この GHZ 状態を作る量子回路もネイティブゲートで構築してみます。前節の回路を単純に拡張すると
n_qubits = 3
qc_ghz_native = QuantumCircuit(n_qubits)
for i in range(n_qubits):
qc_ghz_native.sx(i)
for i in range(n_qubits - 1):
qc_ghz_native.ecr(i, i + 1)
qc_ghz_native.draw('mpl')

ですが、この量子状態は
show_statevector(qc_ghz_native)

となり、GHZ 状態になっていません。
しかし、よく見ると違いは2点だけです。
- 0 番目の量子ビットの状態が逆
- 位相がずれている(係数が違う)
前者は 0 番目の量子ビットに X ゲートを操作することで解決できます。
qc_ghz_native.x(0) show_statevector(qc_ghz_native)

式変形した右辺を見ると、位相が - i だけずれていることが分かります。このずれは RZ ゲートで調整できます9。
import numpy as np qc_ghz_native.rz(np.pi, 0) show_statevector(qc_ghz_native)
最終的な量子回路は以下のようになっています。
qc_ghz_native.draw('mpl')

5.3. 一般化した GHZ 状態生成
さらに量子ビット数を増やして一般化してみます。つまり、全量子ビットが |0〉か |1〉の重ね合わせ状態を作る量子回路を考えます。
ユニバーサルゲートの場合は単純に一般化できて以下の関数で作れます。
def make_circuit_by_universal_gates(n_qubits):
qc = QuantumCircuit(n_qubits)
if n_qubits < 2:
return qc
qc.h(0)
for i in range(n_qubits - 1):
qc.cx(i, i + 1)
return qc
結果だけですが、ネイティブゲートの場合は以下の関数になります。
def make_circuit_by_native_gates(n_qubits):
qc = QuantumCircuit(n_qubits)
if n_qubits < 2:
return qc
for i in range(n_qubits):
qc.sx(i)
for i in range(n_qubits - 1):
qc.ecr(i, i + 1)
for i in range((n_qubits - 1) // 2):
qc.x(n_qubits - 3 - 2 * i)
if n_qubits % 2 == 1:
qc.rz(np.pi / 2, 0)
return qc
X ゲートと RZ ゲートを加えるタイミングが複雑になっていますが、量子ビット数を1つずつ増やしていけばパターンが見えるので、上のようなプログラムで一般化できることが分かります。
5.4. 量子回路の深さ比較
では、前節で作った関数を使ってできる量子回路をトランスパイルした時の深さを確認してみます。
ここでは理想的な状況としてスワップゲートが不要な結合構造を仮定します。それは、たとえば以下のような coupling_map で実現できます。
max_n_qubits = 10 coupling_map = [[i, i + 1] for i in range(max_n_qubits)] CouplingMap(coupling_map).draw()

量子ビットを 10 まで増やしながらトランスパイル後の深さを求めます。このとき使用する量子ビットも initial_layout で指定します。
# basis_gates = [gate.name for gate in backend.configuration().gates] # 3.8 節で定義したもの
def ideal_transpile(qc, initial_layout, coupling_map=coupling_map, basis_gates=basis_gates):
return transpile(
qc,
coupling_map=coupling_map,
basis_gates=basis_gates,
initial_layout=initial_layout,
optimization_level=3,
)
depths_univ = []
depths_native = []
n_range = range(2, max_n_qubits + 1)
for n_qubits in n_range:
qc_univ = make_circuit_by_universal_gates(n_qubits)
qc_native = make_circuit_by_native_gates(n_qubits)
initial_layout = list(range(n_qubits)) # 使用する量子ビット
transpiled_qc_univ = ideal_transpile(qc_univ, initial_layout=initial_layout)
transpiled_qc_native = ideal_transpile(qc_native, initial_layout=initial_layout)
depths_univ.append(transpiled_qc_univ.depth())
depths_native.append(transpiled_qc_native.depth())
これを可視化すると以下のようになります。
import matplotlib.pyplot as plt
plt.plot(n_range, depths_univ, marker='o', label='Universal gates')
plt.plot(n_range, depths_native, marker='o', label='Native gates')
plt.xlabel('n_qubits', fontsize=14)
plt.ylabel('Depth', fontsize=14)
plt.title('Universal gates vs Native gates')
plt.legend(fontsize=12)
plt.show()

最初からネイティブゲートで構築した場合、3 量子ビットの GHZ 状態の時だけ深さが 4 になりますが、それ以外は量子ビット数と深さが一致します。それに比べてユニバーサルゲートで構築した場合の深さは量子ビット数の2倍+1になります。最初からネイティブゲートで構築することで深さはおよそ半分になっています10。
将来的にトランスパイルする際の最適化手法が改善されれば、今回のように手動でより浅い回路を考えることなく自動で変換されることが期待されます。とはいえ、いまのところ自動最適化は不十分なので、こういった地道な回路設計にも意味があると考えています。
6. 量子コンピュータを動かす
ここでようやく本物の量子コンピュータを動かすところまで来ました。
前回記事で述べたように量子コンピュータの計算といえば期待値計算を指すことが多いですが、今回はよりシンプルに Z 測定をたくさん繰り返してその頻度を求める「サンプリング」を行います11。
6.1. 実機指定の注意点
現在使える実機はすべて 127 量子ビットで3種類あります。基本的には一番空いている実機を使うことが推奨されており、そのための関数もあります。
backend = service.least_busy(operational=True, simulator=False)
しかし、以下の関数で実機の結合構造を見比べてみると3つとも違うことが分かります。ここではこのあと使う 'ibm_brisbane' の結合構造のみ載せます。
from qiskit.visualization import plot_gate_map
backend = service.get_backend('ibm_brisbane')
plot_gate_map(backend, plot_directed=True, font_size=14)

結合構造が異なるとトランスパイルした時の量子回路も変わるので要注意です。結合構造を意識して量子回路を設計した場合は、上記のように実機を名前で指定することを忘れないでください。
6.2. 実験用の量子回路作成
上の結合構造をじっと眺めて一番長く一方向に繋がっている量子ビットを探してみます。間違えていなければ以下の番号の量子ビット群が最長で 13 個です。今回はそれらの量子ビットを使います。
layout = [101, 100, 99, 98, 91, 79, 80, 81, 82, 83, 92, 102, 103] max_n_qubits = len(layout) print(max_n_qubits) # => 13
量子回路は前章で定義した関数で作成します。
def make_circuits(make_state, max_n_qubits=max_n_qubits, layout=None, optimization_level=3):
qcs = []
for n_qubits in range(2, max_n_qubits + 1):
qc = make_state(n_qubits)
qc.measure_all() # Z 測定する(サンプリングに必須!)
if layout is not None:
initial_layout = layout[:n_qubits] # 使用する量子ビット
transpiled_qc = transpile(qc, backend=backend, initial_layout=initial_layout, optimization_level=optimization_level)
qcs.append(transpiled_qc)
else:
transpiled_qc = transpile(qc, backend=backend, optimization_level=optimization_level)
qcs.append(transpiled_qc)
return qcs
ここで忘れがちなのですが、サンプリングする場合は量子回路に測定することを明示する必要があります。上記の qc.measure_all() がトランスパイルの前に入っていることに注意してください。
さらに、比較として使用する量子ビットの指定有無と最適化レベルを変えても実行したいので、以下の関数で量子回路を作ります。
def make_circuits_list(make_circuit, layout=layout):
qcs_list = []
for i in range(4):
if i == 0:
# 使用する量子ビットを指定する
qcs = make_circuits(make_circuit, layout=layout)
else:
# トランスパイルの最適化レベルを変える(使用する量子ビットは指定しない)
qcs = make_circuits(make_circuit, optimization_level=i)
qcs_list.append(qcs)
return qcs_list
universal_qcs_list = make_circuits_list(make_circuit_by_universal_gates)
native_qcs_list = make_circuits_list(make_circuit_by_native_gates)
6.3. 作成した量子回路の確認
実験前にこれらの量子回路の深さを確認しておきます。
x = range(2, max_n_qubits + 1)
for i, qcs in enumerate(universal_qcs_list):
depths = [qc.depth() for qc in qcs]
if i == 0:
plt.plot(x, depths, marker='o', label='Universal: with Layout')
else:
plt.plot(x, depths, marker='.', label=f'Universal: optimization_level={i}')
for i, qcs in enumerate(native_qcs_list):
depths = [qc.depth() for qc in qcs]
if i == 0:
plt.plot(x, depths, marker='x', label='Native: with Layout')
else:
# plt.plot(x, depths, marker='+', label=f'Native: optimization_level={i}')
pass # 使用する量子ビットの指定なしだとユニバーサルゲートの場合と大差ないので省略
plt.xlabel('n_qubits', fontsize=14)
plt.ylabel('Depth', fontsize=14)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0, fontsize=12)
plt.show()

今回は使用する量子ビットを念頭に設計したため、量子ビットを指定した場合(Universal: with Layout と Native: with Layout)の方が想定通り浅くなっています。さらに前章で見たようにユニバーサルゲートで構築した場合よりネイティブゲートで構築した方が浅いです。
ここで意外なことに optimization_level は高いほど量子回路が浅くなるわけではありませんでした。optimization_level が 1, 2 の深さは同程度ですが、3 になると 1, 2 の場合より最大で 1.6 倍以上深くなっています。
それを理解するのにトランスパイルにおける最適化の観点を紹介します。たとえば以下の太字で書いた観点があります。
- 使用する量子ビット
- スワップゲートを最小化する:今回はスワップゲートが不要な量子回路です。
- より性能の良い量子ビットを使う:実機の量子ビットはものによって性能の良し悪しがあるのでそれをどの程度考慮するかです。
- 使用するゲート
- エラー率の高い2量子ビットゲートを減らす:今回は使用する量子ビットの数が同じなら、どの量子回路も2量子ビットゲートの数は同じです。
使用する量子ビットについては量子回路を設計する段階でベストなものを決め打ちしていたのですが、最適化により自動でその量子ビットを割り当てられたのは 4 量子ビットの optimization_level が 2, 3 の場合だけでした。この事実からわかるように、最適化アルゴリズムはまだまだ未発達で改善の余地があります。
とくに、量子ビット間の結合が単方向であることは考慮していないと思われます。公式ドキュメントの Layout stage で参照している論文には
Since the difficulty from the asymmetric connection is overcome by technology advance, we will focus on the latest symmetric coupling model and only consider inserting SWAPs for mapping change.
との記述があり、これに従うなら結合が双方向であることを前提としています。
しかし、実際には結合が単方向なので2量子ビットゲートの制御量子ビットと対象量子ビットが逆になる場合は余分にゲートを増やすことになります。今の量子コンピュータはエラー率が高いので、ゲートが多すぎるとまったくのでたらめな結果を返すことになり、むやみにゲート数を増やすのは得策ではありません。これはこのあとの実機の実行結果から明らかになります。
次に、トランスパイル後の量子回路についても確認しておきます。
代表として 13 量子ビットのユニバーサルゲートで構築した最も深い量子回路は
qc = universal_qcs_list[3][-1] # optimization_level=3 の量子回路
print(qc.depth())
# => 61
qc.draw('mpl', idle_wires=False, fold=-1)

対して、ネイティブゲートで構築した最も浅い量子回路は
qc = native_qcs_list[0][-1] # 使用する量子ビットを指定した量子回路
print(qc.depth())
# => 14
qc.draw('mpl', idle_wires=False, fold=-1)

図の描画前に深さを出力していますが、同じ量子状態を作るのに深さが 4 倍以上違うことは要注目です。
ところで、最も浅い場合は使用する量子ビット数と同じ 13 でしたが、上の実行結果を見ると 14 になっています。これは qc.measure_all() が深さとしてカウントされ +1 されているためです。qc.measure_all() はサンプリングを実行するために測定を明示的に示すもので、量子回路図にも測定を表すアイコンが追加されていることが分かります。
また、この量子回路で使う量子ビットは以下の描画関数で確認できます。
from qiskit.visualization import plot_circuit_layout plot_circuit_layout(qc_native_list[-1], backend)

6.4. サンプリングの実行
実機ごとに最大サンプリング数が決まっていて、デフォルトから変える場合はそれを超えない範囲で指定する必要があります。今回は切りの良い 1 万回に設定します。
from qiskit_ibm_runtime import SamplerV2 as Sampler sampler = Sampler(backend) max_shots = backend.configuration().max_shots shots = min(10000, max_shots) sampler.options.default_shots = shots print(shots) # => 10000
実機での実行は即時実行ではなく順番待ちがあります。さらに無償だと最大で3つまでしか実行予約ができません。
そのため、少々煩雑ですが以下のように1つずつ実行します。
# ユニバーサルゲートで構築 qcs_u = universal_qcs_list[0] # 使用する量子ビットの指定あり qcs_u1 = universal_qcs_list[1] # optimization_level=1 qcs_u2 = universal_qcs_list[2] # optimization_level=2 qcs_u3 = universal_qcs_list[3] # optimization_level=3 # ネイティブゲートで構築 qcs_n = native_qcs_list[0] # 使用する量子ビットの指定あり
他も同様なのでひとつの実行例だけ載せます。
job = sampler.run(qcs_u) job.job_id() # => 'ジョブを特定する文字列が表示されます'
他の量子回路についても3つまでは同時に実行して大丈夫ですが、それ以上は予約失敗になるのでご注意ください(エラーメッセージが返ってくるだけなので怖がる必要はありません)。
ちなみに、上記のプログラムで sampler.run() には量子回路のリストを渡しています。このリストの単位でひとつのジョブとして実行されます。このひとつのジョブに実行したい量子回路を全部詰め込んでしまえば1回の実行予約だけで大丈夫です。ただ、実機の実行時間が無償の範囲内だと1か月当たり 10 分となっていて、その枠内で色々実験するには量子回路を小分けにした方が調整しやすいです。
今回の量子回路だと上のプログラムの実行で 52 秒消費されました。全部で 5 種類の量子回路を実行するので、計 260 秒(4 分 20 秒)消費されます。サンプリング数を増やした方がより正確な評価ができますが、消費時間も増えるので適度な値に設定しています。
6.5. 実行結果の取得
時間帯によっては数分で実行が完了することもありますが、何時間も待つこともあります。おそらく実行が完了する頃にはパソコンの前から離れて Google Colaboratory の接続が切れていることがほとんどかと思います。その場合は再度 2 章の環境構築をしてください。
実行したジョブを取得する用に次の関数を定義します。
from qiskit.providers.jobstatus import JobStatus
def get_job_data(job_id):
job = service.job(job_id)
print(job.status())
if job.status() != JobStatus.DONE:
return None
return {
'result': job.result(),
'depths': job.metrics()['circuit_depths'],
'shots': job.inputs['options']['default_shots'],
}
この関数の引数 job_id は前節で最後に実行した job.job_id() の出力になります。この job_id は IBM Quantum Platform のジョブ一覧からも確認できます。量子回路と job_id の対応付けを間違えないように注意して以下のプログラムを実行します。
job_u = get_job_data('ユニバーサルゲートで initial_layout を指定した量子回路の job_id をコピペ')
job_u1 = get_job_data('ユニバーサルゲートで optimization_level=1 とした量子回路の job_id をコピペ')
job_u2 = get_job_data('ユニバーサルゲートで optimization_level=2 とした量子回路の job_id をコピペ')
job_u3 = get_job_data('ユニバーサルゲートで optimization_level=3 とした量子回路の job_id をコピペ')
job_n = get_job_data('ネイティブゲートで initial_layout を指定した量子回路の job_id をコピペ')
実行済みであれば「JobStatus.DONE」が出力されます。すべて実行済みであれば次に進みます。
6.6. 実行結果の確認
サンプリングの実行結果として、得られた量子状態の頻度をヒストグラムで表示する関数が用意されています。
試しに量子ビット数が 13 の結果を可視化してみます。
from qiskit.visualization import plot_histogram counts = job_u['result'][-1].data.meas.get_counts() plot_histogram(counts, figsize=(30,5))
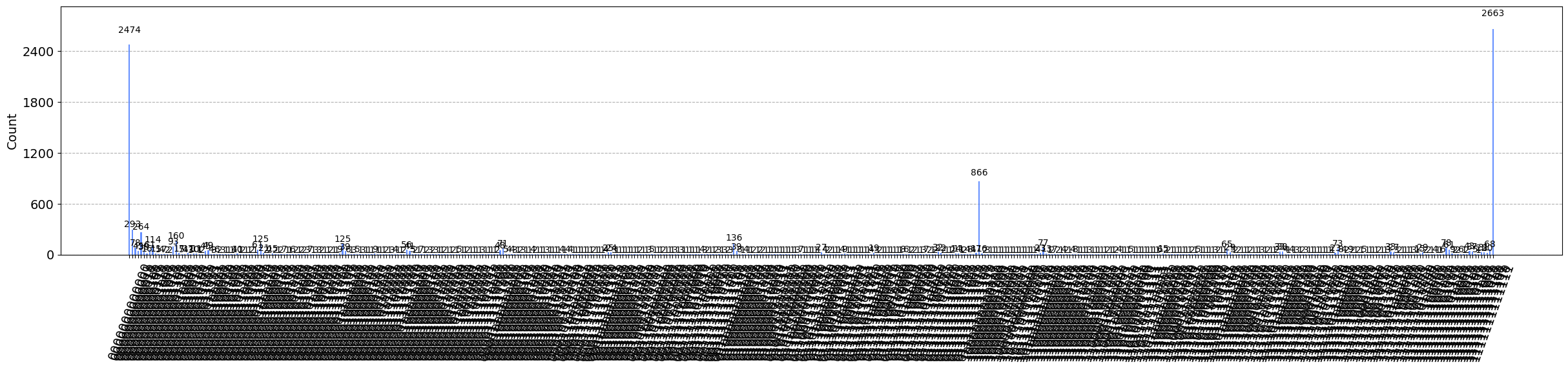
両端が期待される2つの状態で、それらが 5000 ずつだと期待通りです。それらが多いのは確かですが、頻度は期待より半分程度しかありません。
図の横軸ですが、取りうる状態数が 213 = 8192 通りもあるためラベルがつぶれてしまってよく分かりません。そこで、量子状態が |1〉である量子ビットの数をカウントしたヒストグラムを表示します。プログラムの細かな説明は省きますがそのために以下の関数を使います。
import itertools
def calc_counts_sum(job, n_qubits=13):
counts = job['result'][n_qubits-2].data.meas.get_counts()
counts_dict = {}
for i in range(n_qubits + 1):
_idx = '0' * n_qubits
count_sum = 0
for pair in itertools.combinations(range(n_qubits), i):
idx_list = np.array(list(_idx))
idx_list[list(pair)] = '1'
idx = ''.join(idx_list)
try:
count = counts[idx]
except:
continue
else:
count_sum += count
counts_dict[i] = count_sum
return counts_dict
すべての結果についてヒストグラムに必要な計算をします。
counts_sum_u = calc_counts_sum(job_u) counts_sum_u1 = calc_counts_sum(job_u1) counts_sum_u2 = calc_counts_sum(job_u2) counts_sum_u3 = calc_counts_sum(job_u3) counts_sum_n = calc_counts_sum(job_n)
これらをまとめて可視化すると以下のようになります。
fig, axs = plt.subplots(nrows=2, ncols=3, figsize=(20, 10), sharey=True)
plot_histogram(counts_sum_u1, ax=axs[0,0])
plot_histogram(counts_sum_u2, ax=axs[0,1])
plot_histogram(counts_sum_u3, ax=axs[0,2])
plot_histogram(counts_sum_u, ax=axs[1,0])
plot_histogram(counts_sum_n, ax=axs[1,1])
for ax in axs.reshape(-1):
ax.set_xlabel(r'The number of $\left| 1 \right\rangle$', fontsize=18)
ax.set_ylabel('Counts', fontsize=14)
ax.axhline(2500, color='lightgray', linestyle='dashed')
ax.set_ylim(0, 5000)
axs[0,0].set_title('Universal: optimization_level=1', fontsize=18)
axs[0,1].set_title('Universal: optimization_level=2', fontsize=18)
axs[0,2].set_title('Universal: optimization_level=3', fontsize=18)
axs[1,0].set_title('Universal: with Layout', fontsize=18)
axs[1,1].set_title('Native: with Layout', fontsize=18)
fig.delaxes(axs[1, 2]) # 描画されない領域を削除
plt.tight_layout()
plt.show()

理想的なカウント数は両端(横軸が 0 と 13)が 5000で、他は 0 です。その隣(横軸が 1 と 12)は 1 つの量子ビットが期待と違って反転してしまった場合に対応します。さらにその隣(横軸が 2 と 11)は2つの量子ビットが反転した場合というように続きます。
図の上段は使用する量子ビットを指定しなかった場合ですが、optimzation_level に依らずどれも二峰分布になっています。両端はピークができるどころか山のすそ野になっており、まったく期待通りに計算できていないことが分かります。
図の下段は使用する量子ビットを指定した場合で、両端にピークができているのは期待通りです。ただ、カウント数が理想に対して半分程度しかないので、正しく計算できたのはせいぜい 50% と見積もれます。より正確な評価は次節で行います。
ここでは実験で使った最大の 13 量子ビットの結果のみ載せましたが、他の結果も同様に可視化できます。calc_counts_sum() 関数の引数 n_qubits を 13 から変えるだけです。興味のある方はぜひ他の結果もご確認ください。
6.7. 実行結果の評価
これが本記事の結論になりますが、量子計算の忠実度(Fidelity)を計算します。計算には以下のプログラムを使用します。
from qiskit.quantum_info import hellinger_fidelity
def calc_fidelity(job):
shots = job['shots']
fidelity_dict = {}
for i, res in enumerate(job['result']):
counts = res.data.meas.get_counts()
n_qubits = i + 2
ideal_counts = {
'0' * n_qubits: shots // 2,
'1' * n_qubits: shots // 2
}
fidelity = hellinger_fidelity(counts, ideal_counts)
fidelity_dict[n_qubits] = fidelity
return fidelity_dict
理論的には全部 0 か全部 1 が半々になるのが理想で、それを ideal_counts として定義しています。忠実度はその理想との一致度のことです。計算結果は 0 ~ 1 の値になり、大きいほど理想に近いです。
すべての結果について忠実度を計算します。
fidelity_u = calc_fidelity(job_u) fidelity_u1 = calc_fidelity(job_u1) fidelity_u2 = calc_fidelity(job_u2) fidelity_u3 = calc_fidelity(job_u3) fidelity_n = calc_fidelity(job_n)
横軸を使用する量子ビット数として、忠実度を可視化すると
plt.plot(fidelity_u.keys(), fidelity_u.values(), marker='o', label='Universal: with Layout')
plt.plot(fidelity_u1.keys(), fidelity_u1.values(), marker='.', label='Universal: optimization_level=1')
plt.plot(fidelity_u2.keys(), fidelity_u2.values(), marker='.', label='Universal: optimization_level=2')
plt.plot(fidelity_u3.keys(), fidelity_u3.values(), marker='.', label='Universal: optimization_level=3')
plt.plot(fidelity_n.keys(), fidelity_n.values(), marker='x', label='Native: with Layout')
plt.axhline(0.9, color='gray', linestyle='dashed')
plt.axhline(0.5, color='gray', linestyle='dashed')
plt.ylim(0, 1)
plt.xlabel('n_qubits', fontsize=14)
plt.ylabel('Fidelity', fontsize=14)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0, fontsize=12)
plt.show()

忠実度は量子ビット数が増えて量子回路が深くなるほど下がっていることが分かります。しかもその下がり方は急で、4 量子ビットで 0.9 未満になっています。8 量子ビットのところで急激に忠実度が下がっている理由は把握できていませんが、13 量子ビットの段階でせいぜい 0.5 にまで下がっています。つまり、13 量子ビットの結果は 50% 程度しか期待通りの結果が得られていません。これは前節でヒストグラムから見積もった通りです。
しかし、使用する量子ビットを指定した方(図中の with Layout の線)がずっと忠実度が高いことは特筆すべき結果です。トランスパイル時の自動最適化アルゴリズムに任せるだけだと 13 量子ビットの段階で忠実度は 0.03 しかありませんでした。これは 97% が間違いということなのでまったく信用できない結果です。結果がでたらめなのは前節で見たヒストグラムからも明らかです。
次に、横軸を量子回路の深度を変えた場合は以下のようになります。
plt.plot(job_u['depths'], fidelity_u.values(), marker='o', label='Universal: with Layout')
plt.plot(job_u1['depths'], fidelity_u1.values(), marker='.', label='Universal: optimization_level=1')
plt.plot(job_u2['depths'], fidelity_u2.values(), marker='.', label='Universal: optimization_level=2')
plt.plot(job_u3['depths'], fidelity_u3.values(), marker='.', label='Universal: optimization_level=3')
plt.plot(job_n['depths'], fidelity_n.values(), marker='x', label='Native: with Layout')
plt.axhline(0.9, color='gray', linestyle='dashed')
plt.axhline(0.5, color='gray', linestyle='dashed')
plt.ylim(0, 1)
plt.xlabel('Depth', fontsize=14)
plt.ylabel('Fidelity', fontsize=14)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0, fontsize=12)
plt.show()

この図からは、量子回路が深くなるほど忠実度が下がる傾向にあることが分かります。
ところで、頑張ってネイティブゲートで構築したより浅い量子回路(× の線)と単純にユニバーサルゲートで構築した量子回路(● の線)とで忠実度にそれほど差がありませんでした。今回は 13 量子ビットまでの実験でしたが、量子ビット数を増やせば深さの差が広がるので、ネイティブゲートでより浅い回路を構築するメリットが生まれてくると思われます。
6.8. 実行結果について補足
上の結果は4月初頭に行ったもので、3月末に実験した時は下図のように量子ビット数が増えるにつれて忠実度に差が出ていました。

この3月末時点の結果からの忠実度の差を可視化すると

このように 4 量子ビット以上で大きく忠実度が上がっていました。とくに、ユニバーサルゲートで構築した量子回路の方がより改善しており、3月末時点での忠実度の差が埋まったようです。
まったく同じ量子回路の実行結果なので、以下のようなことが理由として考えられます。
- 4月初頭の方が実機があまり利用されておらず、個々の量子ビットの性能が良かった
- 実機のハードウェアに関するアップデート(キャリブレーション含む)があり、ゲート操作のエラー率が低減していた
- エラー緩和の性能が向上していた
ひとつめの理由が一番ありそうと考えています。これは利用者が多く頻繁に使われているほど、量子コンピュータが発熱して熱雑音が増えるという意味です。もしくは、大きな量子チップを区分けにして同時にいくつもの量子回路を実行しているとすれば、隣接する領域でのゲート操作がクロストークと呼ばれる現象でノイズを生み出している可能性もあります。
いずれにせよ量子コンピュータの性能が良ければ、量子回路が深くなることによる悪影響は無視できると言えます。今回は深さが約 2 倍違いますが、深さが 30 未満では忠実度に差が出ないようです。
本記事の内容としては忠実度に差が出ることを示せたら良かったのですが、量子コンピュータがまだまだ不安定で実行するたび結果が変わりうるという良い教訓が得られました。
7. さいごに
前回記事で
このベル状態のように量子もつれと重ね合わせが同時に現れる状態が量子計算の真髄です。
と述べました。本記事ではそのもっともシンプルな例で話を進めてきましたが、本物の量子コンピュータで計算させることを考えるとなかなか複雑な話になりました。6 章で見たように実行結果が期待通りにはいかない様子も感じ取れたかと思います。
しかし、本記事をもって量子コンピュータはまだ使い物にならないと判断するのは時期尚早です。
エラー緩和(Error-Mitigation)ではなくエラー抑制(Error-Suppression)と呼ばれる手法を用いて Q-CTRL が驚くべき成果を上げています。有償プランでないと使えないのですが、リンク先の記事を見ると、彼らのエラー抑制技術を使うことで格段に精度良く計算できることが示されています12。
さらに、各ゲート操作の正確性が増したり、量子ビット数が増えて誤り訂正が可能になれば、計算精度が向上することが見込まれています。
量子コンピュータはまだ黎明期で、これから更なる発展が期待されています。実用化はもう少し先の見通しですが、日々確実に進化しているので失望するのはまだ早いです。
量子コンピュータが実用的になる前に本連載を通してさまざまな技術やユースケースを紹介できればと思います。
次回は量子ソフトウェア研究拠点主催の 2022 年度の量子ソフトウェア勉強会におけるグループワーク成果をまとめる予定です。そこでは量子リザバー計算を行ったのですが、もう1年以上前の成果なので新たに計算し直すことを検討しています。
今回で入門を終えたので、次回はより実践的な計算例を示せればと思います。乞うご期待!
-
IBM Quantum Platform に環境構築済みの IBM Quantum Lab というブラウザ開発環境が用意されているので、そちらを使っても構いません。 ↩
-
クラウド上で動くシミュレータは 2024/05/15 で稼働停止になるようです。代わりにローカル環境での利用法が公式にガイドされています。 ↩
-
この画像は IBM Quantum Platform からダウンロードしたものです。 ↩
-
1年前の 2023 年 2 月頃に色々試していた時は無料で使えるのは 7 量子ビットまででした。この記事を書き始める前に 127 量子ビットも使えるようになっていることに気づいて正直かなり驚いています。一方で、当時は無料枠でも利用制限はなかったのが、今は1か月あたり 10 分までになっています。とはいえ、10 分は今回やるような簡単な実験をするには十分な時間です。 ↩
-
公式ではこの
transpile()関数を使ったトランスパイルよりPassManagerを使う方法が推奨されています。本記事では議論を分かりやすくするため従来のtranspile()関数を使って説明します。PassManagerについては公式ドキュメントの Transpile に関する説明をご参照ください。 ↩ -
ここより前の
transpiled_qc2の図でも量子ビットの置き換えがありましたが、説明が行ったり来たりするのであえてスルーしていました。 ↩ -
最近は数年後に Early-FTQC と呼ばれる誤り耐性を獲得した小規模な量子コンピュータが実現されると期待されています。そこでは効率の良いゲート操作やエラー抑制技術が肝となると考えられます。参考文献として NTT の記事を挙げておきます。 ↩
-
FTQC は 2040 年頃と想定されていますが、少し前(2023 年 12 月)に中性原子量子コンピュータを開発している QuEra Computing が誤り訂正された 48 個の量子ビットで大規模アルゴリズムの実行に成功したという論文を発表しました(プレスリリース記事はこちら)。このようなブレイクスルーが続くと当初の想定よりずっと早く FTQC の時代が訪れるかもしれません。 ↩
-
この量子回路だと RZ ゲートを操作するのはどの量子ビットでも構いません。ここでは単純に 0 番目の量子ビットを選択しています。 ↩
-
ここでは一直線上に並んだ結合構造を仮定しましたが、木の枝のように分岐していく結合構造であれば2量子ビットゲートを並列に操作させることでより浅い量子回路を作れます。しかし、最も浅い回路を作ることが目的ではないので具体的な説明は割愛します。ここでの目的は、特定の結合構造に対応した量子回路を設計し、使用する量子ビットを指定することの有効性を示すことです。 ↩
-
qiskit_ibm_runtimeライブラリは量子コンピュータにおける計算の Primitives(ベース)としてサンプリングを行うSamplerと期待値計算を行うEstimatorを用意しています。それらは旧来のbackend.run()での実行とは異なり、デフォルトで測定エラーの緩和がされています。エラー緩和がないとノイズの影響を受けた精度の低い結果を返すので基本的には Primitives を使うことが推奨されます。情報が少し古いですが、Primitives で行われるエラー緩和の詳細は YouTube の動画が参考になりました。 ↩ -
今回実験した 13 量子ビットの量子回路でDynamic-Decoupling (DD) と呼ばれるエラー抑制を有効にした場合も試してみましたが、より悪い結果になりました。量子ビットは放置しているとよりエネルギーの低い |0〉になってしまいます。DD は測定まで待機状態になっている量子ビットに X ゲートや Y ゲートを操作することで、意図せず |0〉になることを防ぐ手法です。しかし、そのためのゲート操作が正確にできないとゲート操作によるエラーが積み重なってより悪い結果になることが予想されます。現時点では DD を活用するには各ゲート操作の正確性が足りていないと思われます。 ↩