
前回の L1 コンストラクトに続いて、今回は L2 コンストラクトをとりあげます。L2 は L1, L3 など関連する領域が広く、説明を要することがらの多いコンストラクトですが、今回は L1 との違いや構造など基本的なことについて説明します。
L1 もリソース、L2 もリソース
はじめに押さえておきたいのは、L1 も L2 も個々のリソースを表すコンストラクトであるということです。 どちらも EC2 インスタンスや S3 バケットなどを TypeScript のクラスで表現しているという点では同じなのです。
L1 と L2 で異なるのは、抽象化の度合い、具体性です。 同じリソースを表すにしても、L1 は抽象度の低いローレベル (low-level, 低水準) なコンストラクトです1。 それにくらべて L2 は抽象度の高いハイレベル (high-level, 高水準) なコンストラクトです。
CloudFormation のリソース、AWS のリソース
L2 コンストラクトが L1 よりハイレベルであることは、継承するクラスにも表れています。 前回のおさらいもかねて、L1 と L2 のクラス階層をくらべてみましょう。
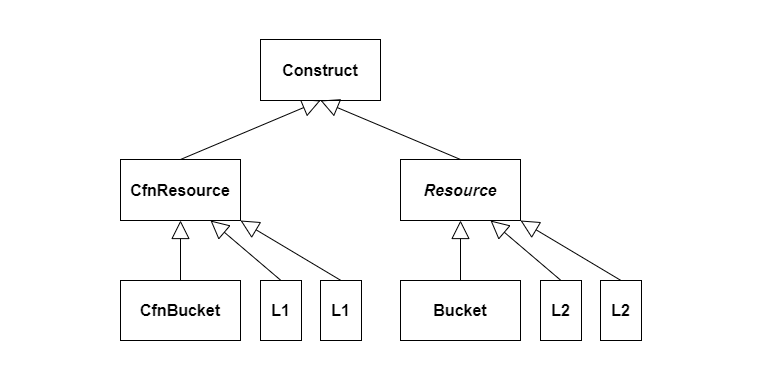
L1 が継承するのは CfnResource クラスです。
このクラスは CloudFormation テンプレートの Resources セクションのリソース全般を表します。
L1 はその一種であり (is-a 関係)、CloudFormation の個々のリソースを表すコンストラクトです。
いっぽう L2 が継承するのは Resource という抽象クラスです。
このクラスは AWS で使えるリソース全般を表します。
L2 はその一種であり、AWS の個々のリソースを表すコンストラクトです。
L2 はあくまで「AWS の」リソースです。 AWS の具体的なサービスの一つである CloudFormation との結びつきは、抽象化して表に出しません。
そのことはクラス名を見てもわかります。
L1 の例として描いた CfnBucket のあたまには Cfn がついていますが、L2 の Bucket にはついていません。
Bucket は AWS で使えるバケットではありますが、CloudFormation で管理するかどうかという具体的なことまで踏み込んで表現してはいないのです。
サービスのメンタルモデル、ユーザーのメンタルモデル
L2 はユーザーのメンタルモデル (mental model) に合わせたコンストラクトであるとも言えます。 この点について、AWS CDK コンストラクトライブラリのデザインガイドラインを見てみましょう。
このガイドラインには、主に L2 のようにハイレベルなコントストラクトを設計するにあたっての指針、規則が述べられています。 その中で AWS CDK の教義、原則 (tenets) とされている以下の記述に注目したいと思います。
Meet developers where they are: our APIs are based on the mental model of the user, and not the mental model of the service APIs, which are normally designed against the constraints of the backend system and the fact that these APIs are used through network requests. It’s okay to enable multiple ways to achieve the same thing, in order to make it more natural for users who come from different mental models.
Meet developers where they are: AWS CDK の API (注:コンストラクトライブラリ) はユーザーのメンタルモデルに基づいている。サービスの API のメンタルモデルではない。サービスの API はふつう、バックエンド・システムの制約と、ネットワーク越しに呼び出されるという現実に対処できるよう設計されている。同じことを成し遂げるために複数のやり方があってかまわない。異なるメンタルモデルをもつユーザーにとってより自然な形にしようというのであれば。
L1 は、ここでいう「サービスの API のメンタルモデル」に近いコンストラクトと言ってよいでしょう。 L1 は CloudFormation テンプレートの仕様から自動生成され、テンプレートとほとんど違いがないからです。
いっぽう L2 は、「ユーザーのメンタルモデル」つまり AWS CDK アプリの開発者の考え方や都合に寄り添うコンストラクトです。 L2 のプロパティやメソッドは自動生成ではなく、人間が開発者にとって使いやすいものを考えて設計します。 “Meet developers where they are” という AWS CDK の解説でよく見かけるフレーズは、そのことを端的に表しています。
L2 などハイレベルなコンストラクトの設計に、ただ一つの正解はありません2。 ガイドラインに示されているようないくつかの規則にしたがえば、あとは開発者やプロジェクトに合わせて、さまざまなコンストラクトを作ってよいのです。
コンポジション
ハイレベルとはいえ、L2 コンストラクトもふつうは CloudFormation テンプレートを生成します (生成しない場合については別の回で説明します) 。 テンプレートを生成するには、前回見た L1 をはじめとするローレベルなコンストラクトが必要です。
一般に、L2 や L3 などハイレベルなコンストラクトは、自身と同等かよりローレベルなコンストラクトをコンポジション (composition) することで成り立っています。 コンポジションとは、一言でいうと、一つ以上のコンストラクトを組み合わせて新たなコンストラクトにまとめあげることです。
L2 は主に L1 をコンポジションしています。 L2 はいくつかの L1 をまとめあげて、テンプレートの生成に利用しているわけです。
コンポジションは必要に応じてくり返してかまいません。 L2 が別の L2 をコンポジションし、その別の L2 が L1 をコンポジションしている、ということもよくあります。
L2 の構造:コンストラクトツリーとメインの L1
AWS CDK におけるコンポジションは、構造としてはコンストラクトツリーを作ることと同じです。 L2 コンストラクトの場合、おおよそ次のようなツリーを作ります。
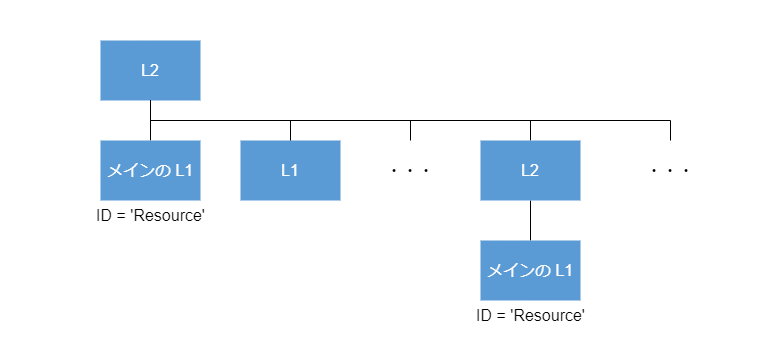
図のように L2 がコンポジションする複数の L1 の中には、メイン (main) と言える L1 が一つあります。 メインというのは、L2 が抽象化する主な対象ということです。
メインの L1 の ID は 'Resource' にする決まりになっています。
ときどき L1 ではなく L2 がメインなこともありますが、その場合でも ID が 'Resource' であることがメインの目印になります。
以下の図は L2 の Bucket コンストラクトが形成するツリーの例です。
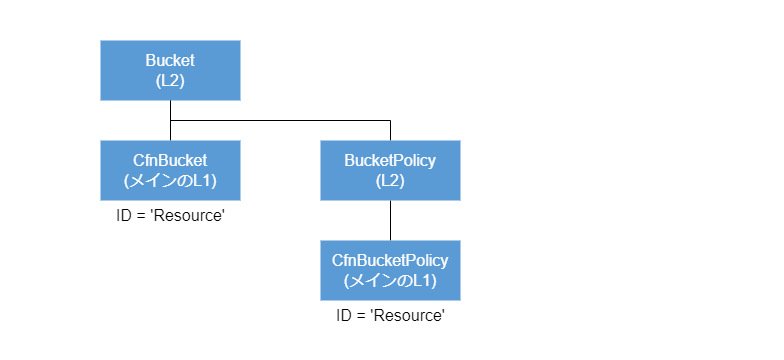
Bucket のメインの L1 は CfnBucket コンストラクトです。
Bucket は L2 の BucketPolicy コンストラクトをコンポジションすることもありますが、それはメインである CfnBucket を抽象化し便利に使えるようにするためです。
BucketPolicy も L2 ですので、図のようにメインの L1 CfnBucketPolicy をコンポジションしツリーを形成します。
このように、コンポジションはくり返され、ツリーは伸びていきます。
part-of 関係としてのコンポジション
公式ドキュメントではそれほど詳しく説明されていませんが、コンポジションはオブジェクト指向からそのまま AWS CDK にとりいれた概念と見てよいでしょう。 そこでちょっとオブジェクト指向の観点から AWS CDK におけるコンポジションをながめてみたいと思います。
コンポジションはよく has-a 関係であるとか part-of 関係であるなどと説明されます。 この二つの関係は、似ているようで関係の強さが異なります。
has-a というのは「… は … を持っている」ということです。 もしも持っている側が消えても、持たれている側は残ります。 has-a 関係は、それほど強い関係ではありません。
part-of というのは「… は … の一部である」ということです。 もしも全体が消えたら、その一部であったものも消えてしまいます。 part-of 関係は、非常に強い関係です3。
おそらく AWS CDK のコンポジションは has-a 関係ではなく part-of 関係でしょう。 なぜならコンストラクトツリーにおいて、子ノードは親ノードの一部であり、親ノードが消えたら、子ノードもいっしょに消えてしまうからです。
例として AWS CDK アプリで使っている L2 の ID を 'Old' から 'New' に変える場合を考えてみましょう。
この場合、もともとあった ID が消えて新たな ID が作られたわけですから、'Old' のノードは消えて別物である 'New' のノードが作られたとみなされます。
この影響は、子ノードであるメインの L1 にもおよびます。
メインの L1 の ID はあいかわらず 'Resource' ですが、スコープ (親ノード) が違うので別物とみなされます。
そのため、メインの L1 もスコープとともに消えて、新たに作られたとみなされるのです。
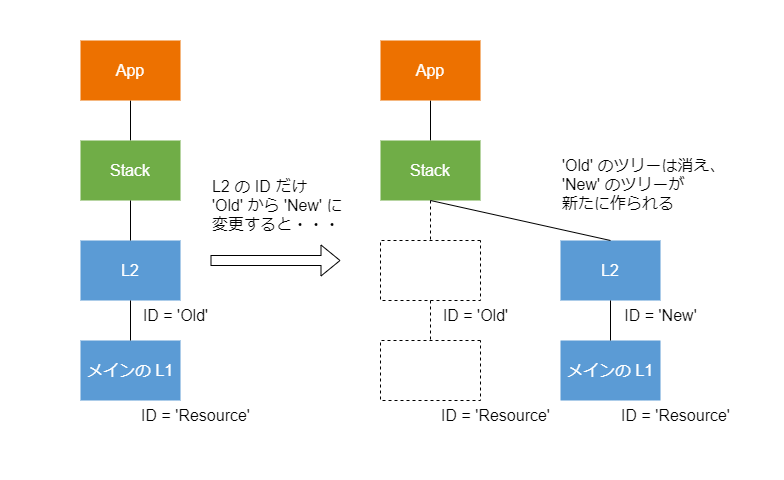
筆者は AWS CDK を使いはじめたころ、こうしたコンポジション/コンストラクトツリーの特徴を知らず、ちょっと L2 の ID を修正しただけのつもりが思いがけずいくつもリソースが消えてしまって困った、ということが何度もあります。
ベストプラクティスとセンシブルデフォルト
L2 や L3 などハイレベルなコンストラクトが、L1 のようにローレベルなコンストラクトをコンポジションする利点はさまざまです。 ここではベストプラクティスとセンシブルデフォルトという二つのキーワードに着目してみましょう。
ベストプラクティス
ハイレベルなコンストラクトには、ベストプラクティスを盛り込むことができます。 AWS CDK アプリの開発者にかわって、あらかじめ適切な形でローレベルなコンストラクトをコンポジションし、適切な設定をほどこしておけるのです。
AWS CDK のコンストラクトライブラリが提供する L2 や L3 には、AWS CDK の開発チームの知見にもとづくベストプラクティスが盛り込まれています。 また、自作の L2 や L3 には、自身が所属するチームやプロジェクトにとってのベストプラクティスを盛り込むことができます。
コンストラクトを npm などパッケージ、ライブラリとして共有すれば、ベストプラクティスもまた共有されます。 ハイレベルなコンストラクトを使うと、特に意識しなくても手軽にベストプラクティスの恩恵を受けられるのです。
センシブルデフォルト
センシブル (sensible) とは、よく練られたとか、実用的であるとか、「いい感じ」のとかいう意味の言葉です。 ソフトウェアの世界では、「いい感じ」のデフォルト値を選ぶことの意義がさまざまな形で語られていますが、センシブルデフォルトもそのうちの一つと言えます。
センシブルデフォルトの起源は、調べてみてもあまり情報が出てこないのですが、どうやら十数年前に二人のコンサルタントのやりとりから生まれた言葉のようです4。 そのやりとりの中で、センシブルデフォルトの例として、あのスティーブ・ジョブズ氏の服装が挙げられています。 ジョブズ氏がよく同じ服装をしていたように、センシブルデフォルトにしたがうことで、あれこれ考える時間と労力を省くことができるというわけです。
ハイレベルなコンストラクトは、開発者がいちいち指定しなくても、コンポジションしているローレベルなコンストラクトに「いい感じ」の設定をほどこしてくれます。 これといった理由がないときはセンシブルデフォルトにしたがうことで、効率的に開発を進められるのです。
両者の違い
ベストプラクティスとセンシブルデフォルトは、よく似た発想でもあります。 センシブルデフォルトにしたがっていたらそれがベストプラクティスだった、というふうに境界線がよくわからないこともあります。
ただ、ベストプラクティスは文字通り「ベスト」という意味合いが強いのに対し、センシブルデフォルトは「スタート」という意味合いが強いように思います。 センシブルデフォルトはあくまで初期値であって、状況しだいで変えていくものです。
筆者はよく、初めて使う L2 はただ単に new することから始めます。
プロパティは必須のもの以外設定せず、メソッドも呼びません。
そうして一度シンセサイズやデプロイをしてみてから、デフォルトでは要件に合わない点だけ、あれこれ考えて変えていきます。
L2 の例:Bucket
ここまで L2 のおおよその特徴や構造を見てきました。
ここからはもう少し具体的に、Bucket コンストラクトを例として L2 の使い方を見てみましょう。
ベストプラクティス/センシブルデフォルトにしたがう
以下のようなコードを含む AWS CDK アプリがあるとします。
// L1 new CfnBucket(stack, 'CfnBucket') // L2 new Bucket(stack, 'Bucket')
L1 と L2 どちらも new しただけです。
第一引数のスコープに stack (これまでの連載でたびたび出てきた Stack コンストラクト) を、第二引数に ID を指定していますが、それら最低限必要なこと以外はなにもしていません。
このアプリをシンセサイズすると、以下のような CloudFormation テンプレートが出力されます。 (説明のため一部を修正、省略しています。)
"Resources": {
// L1 の出力
"CfnBucket": {
"Type": "AWS::S3::Bucket"
},
// L2 の出力
"Bucket": {
"Type": "AWS::S3::Bucket",
"UpdateReplacePolicy": "Retain",
"DeletionPolicy": "Retain"
}
}
L1 の CfnBucket は、リソースタイプ AWS::S3::Bucket 以外なにも出力していません。
コードで特になにもしていなかったので当然です。
いっぽう L2 の Bucket は、リソースタイプ以外になにやら二つ XXXXPolicy という項目を出力しています。
二つともリソース属性 (resource attribute) という設定項目の一種で、CloudFormation スタックを操作したときの動作を制御するものです。
このように特になにもしなくても、L2 はたいていなにかしら設定をほどこしてくれます。 これがセンシブルデフォルトです。
この例では DeletionPolicy の値が Retain ですので、スタックを削除しても Bucket は削除されず残ります。
バケットに入れた大事なデータをうっかりスタックもろとも消してしまうよりは、残しておいて後で確認してから消すほうがいいだろうと、L2 の作者は考えたのでしょう。
その意味では、これはベストプラクティスでもあります。
カスタマイズする
このようなベストプラクティス/センシブルデフォルトから離れて独自の設定をほどこしたいときは、プロパティを設定したり、メソッドを呼び出したりします。
以下は Bucket のプロパティを表す BucketProps インターフェースを用いて versioned プロパティを設定する例です。
const bucket = new Bucket(stack, 'Bucket', {
versioned: true,
})
versioned は CloudFormation テンプレートの仕様には存在しない、この L2 独自のプロパティです。
値は true ですので、バケットのバージョニングが有効になります。
開発者は、バージョニングを有効にするためのテンプレートの書き方 "VersioningConfiguration": { ... } を知らなくてもかまいません。
かわりに L2 が、コンポジションしている L1 を使って、以下のようなテンプレートを出力してくれます。
"Resources": {
"Bucket": {
"Type": "AWS::S3::Bucket",
"Properties": {
// コードの `versioned: true` による出力
"VersioningConfiguration": {
"Status": "Enabled"
}
},
"UpdateReplacePolicy": "Retain",
"DeletionPolicy": "Retain"
}
}
L2 の作り方
続いて L2 の作り方を見てみましょう。
L2 には、コンストラクトのクラスとそのインターフェースが一つずつ必要です。 また、必須ではありませんが、ふつうはプロパティとしてのインターフェースと、コンストラクトの基底クラスも作ります。
以下の例では MyBucket という L2 を実装してみます。
MyBucket は、個人にとって定番の設定をほどこした S3 バケットを表すものとします。
コンストラクトのインターフェース
はじめに MyBucket のインターフェースを作ります。
以下のように、名前はふつう「I + コンストラクト名」とします。
export interface IMyBucket extends IResource { ... }
継承、拡張 (extends) している IResource は AWS CDK のコアフレームワークが提供するインターフェースです。
L2 のインターフェースは、このように IResource を継承しなければなりません。
コンストラクトの基底クラス
次に、必須ではありませんが MyBucket の基底クラスを作ります。
この例では、基底クラスで上記の IMyBucket インターフェースを実装 (implements) します。
また、冒頭で見た Resource クラス (L2 共通の親クラス) の継承も基底クラスでやってしまいます。
abstract class MyBucketBase extends Resource implements IMyBucket { ... }
これらインターフェースや基底クラスの役割は、また別の回で説明します。
今回はこんな風に L2 は IResource インターフェースと Resource クラスを継承するのだと押さえておけば十分です。
コンストラクトのプロパティ (インターフェース)
次に MyBucket のプロパティを作ります。
以下のように、名前はふつう「コンストラクト名 + Props」とします。
export interface MyBucketProps {
readonly noVersioning?: boolean;
...
}
MyBucket はデフォルトではバージョニングを有効にします。
MyBucket は「バケットはふつうバージョニングをしてほしい」というメンタルモデルの開発者に合わせた L2 なのです。
もしもバージョニングをしたくないときは、noVersioning に true を設定してもらいます。
コンストラクト
さて、これで準備ができたので、最後に L2 コンストラクトの本体となる MyBucket クラスを実装します。
export class MyBucket extends MyBucketBase {
constructor(scope: Construct, id: string, props?: MyBucketProps) {
super(scope, id)
const bucket = new CfnBucket(this, 'Resource', {
// デフォルトまたは false の場合はバージョニングが有効
versioningConfiguration: props?.noVersioning
? undefined
: { status: 'Enabled' },
})
// Policy は常に RETAIN
bucket.applyRemovalPolicy(RemovalPolicy.RETAIN)
...
}
...
}
コンストラクターの中で、メインの L1 である CfnBucket を new していますね。
第一引数のスコープには this、つまりこの MyBucket を指定しています。
メインの L1 ですので、第二引数の ID は 'Resource' です。
要するに MyBucket の下に CfnBucket をつけてコンストラクトツリーを伸ばしているわけです。
このようにコンストラクターの中でツリーを伸ばすのは、AWS CDK の定番の書き方です。
これまでの連載では、説明のためにコンストラクターの外でツリーを伸ばしていました。
しかし、特に理由がないときはこの定番の書き方にしましょう。
コンストラクトを new するだけで同じ構造のツリーを複数作ることができて、再利用性が高いからです。
L2 にかぎらず、他のハイレベルなコンストラクトでも同様です。
Stack コンストラクトも、ふつうは以下のように継承して新たなクラスを作り、コンストラクターの中でツリーを伸ばします。
export class MyStack extends Stack {
constructor(scope: Construct, id: string, props?: StackProps) {
super(scope, id, props)
new MyBucket(this, 'MyBucket')
}
}
こうしておけば、同じように MyBucket を使ったスタックを複数作りたいとき、この新たに作った MyStack を new するだけですみます。
const app = new App() new MyStack(app, 'MyStack1') new MyStack(app, 'MyStack2')
以上は L2 の作り方の概要です。 その他の細かい指針や規則については、先ほど紹介したガイドラインや公式サンプルコードを参照してください。
エスケープハッチ
最後に、抽象化の欠点を補うエスケープハッチ (escape hatch) について説明します。
抽象化されたハイレベルなコンストラクトは便利ですが、決して完璧ではありません。 具体的な細かい設定をしたいのに、そのためのプロパティやメソッドが提供されていないことはしばしばあります。 そのたびに要件に合うコンストラクトを新たに自作していてはたいへんです。
そんなときに使えるのがエスケープハッチです。 エスケープハッチは、ハイレベルな AWS CDK の世界からローレベルな世界へと脱出する「非常口」です。
エスケープハッチのおかげで、ふだんは抽象化の利便性を享受しつつ、いざとなったら抽象化を破って具体的な処理を行えます。 ハイレベルなコンストラクトを設計するときも、エスケープハッチを念頭において、抽象化の欠点をおそれずに思い切った設計が可能になります。
ここでは例として、Bucket のプロパティやメソッドが機能不足で、メインの L1 である CfnBucket に思ったような設定ができない場合を考えてみましょう。
この場合、以下のようにコンストラクトツリーの特性を活かして Bucket から CfnBucket を取り出します。
(1) node.children プロパティ
ひとつ目は、前回紹介した node.children プロパティを使う方法です。
このプロパティからは、すぐ下の子ノードをすべて取得できます。
その中から ID が Resource のコンストラクトを取り出せば、それが メインの L1 です。
const bucket = new Bucket(this, 'Bucket') const cfnBucket = bucket.node.children .find(c => c.node.id == 'Resource') as CfnBucket
(2) node.findChild(id), node.tryFindChild(id) メソッド
ID がわかっているなら、上のようにプロパティを使うよりも node.findChild(id) メソッドを使う方が便利です。
const cfnBucket = bucket.node.findChild('Resource') as CfnBucket
ただ、もしも指定した ID のコンストラクトが見つからない場合、このメソッドはエラーになってしまいます。
それを避けたければ、代わりに node.tryFindChild(id) メソッドを使います。
このメソッドは、エラーになる代わりに undefined を返します。
(3) node.defaultChild プロパティ
上の二つの方法は、メインの L1 にかぎらずコンストラクト全般で使えるものです。
実はメインの L1 については、もう一つの方法 node.defaultChild プロパティを使うのがふつうです。
このプロパティからは、ID が Resource または Default の子ノードを取得できます。
よって L2 は以下のようにしてメインの L1 を取得できます。
const cfnBucket = bucket.node.defaultChild as CfnBucket
公式ドキュメントでは、このほかのエスケープハッチも紹介されています。 抽象化のせいでやりたいことができない、というときは思い出して参照してみてください。
おわりに
今回は L2 コンストラクトについて、L1 との違いや構造など基本的なことを説明しました。 L2 は他にも説明すべきことがいくつもありますが、それはまた別の回にしたいと思います。
参考資料
今回説明したことは、主に本文中でも紹介した以下の資料や、AWS CDK コンストラクトライブラリのコードをもとに、適宜筆者の解釈で補ったものです。
引用した英文の翻訳は筆者が行いました。
-
L1, L2 の別名がそれぞれ「ローレベルコンストラクト」「ハイレベルコンストラクト」であるかのように説明されることがありますが、あまり適切ではないように思います。L3 のように、L2 以外にも抽象度が高いコンストラクトはありますし、L3 も higher-level と形容されることがあるからです。この連載でも「ローレベル」「ハイレベル」は L1 や L2 にかぎらない抽象度の高低を表す用語として使います。 ↩
-
正解はありませんが参考になるものとして、ガイドラインでは AWS マネジメントコンソール (AWS の Web 画面) が挙げられています。"When designing the props of an AWS resource, consult the AWS Console experience for creating this resource. Service teams spend a lot of energy thinking about this experience. This is a great resource for learning about the mental model of the user.“, "A good way to determine what’s the right sensible default is to refer to the AWS Console resource creation experience.” ↩
-
たとえば UML 仕様 2.5.1 の「9.5.3 Semantics」より “Composite aggregation is a strong form of aggregation that requires a part object be included in at most one composite object at a time. If a composite object is deleted, all of its part instances that are objects are deleted with it.” ↩
-
2010 年 11 月の Patrick Rhone 氏と Jamie Phelps 氏のブログ: https://patrickrhone.com/2010/11/05/final-choices/, https://jxpx777.me/2010/final-choices-and-sensible-defaults/, https://patrickrhone.com/2010/11/08/sensible-defaults/ ↩