
AWS CDK アプリを開発していると、ふいに ${Token[TOKEN.101]} のようなちょっと変わった見た目の値を目にすることがあります。それが今回とり上げるトークンです。いえ、正確にはエンコードされたトークンです。
トークンはあちこち見えないところで、いつのまにか使っているものです。普段はあまり気にする必要のないその仕組みについて、背景にある課題や関連する概念とともにじっくり見ていきましょう。
L2 のプロパティの型
L2 コンストラクトをながめていると、多くのプロパティが string 型であることに気付きます。
おなじみの Amazon S3 バケットの L2 Bucket のプロパティの場合、次のような感じです。
// バケット名 bucketName: string // バケットの ARN bucketArn: string
一見どうということはありませんが、string の代わりに何か別のクラスを使えないだろうか?と考えてみたくもなります。
理由の一つは、L2 は L1 よりも抽象度の高いハイレベルなコンストラクトだからです (第3回) 。
string 型は TypeScript/JavaScript におけるプリミティブ型の一つであり、抽象化する余地が残っているような気がするのです。
もう一つの理由は、これらのプロパティの値が通常の文字列ではないからです。
あとでサンプルコードを見ますが、bucketName の値は my-bucket-name のようなバケット名そのものではなく、冒頭でふれた ${Token[TOKEN.101]} のようなエンコードされたトークンなのです。
ひょっとしてこれは、問題がひそんでいる「かもしれない」ソースコードの兆候、いわゆるコードスメル (code smell) かもしれません。 プリミティブ型の代わりに AWS や S3 など特定の領域に沿った型を使う方が良さそうな「におい」は、Primitive Obsession と呼ばれるコードスメルの一種です。
初期の Bucket のプロパティ
コードスメルはあくまで「かもしれない」であって、絶対に良くないと決めつけているわけではありません。
ただ、ごく初期の Bucket のコードを見ると、string 型以外の選択肢もありえたことが分かります。
以下は開発者プレビュー版の Bucket (@aws-cdk/aws-s3 0.8.0) のプロパティです。
// バケット名 bucketName: BucketName // バケットの ARN bucketArn: BucketArn
それぞれ string 型の代わりに BucketName と BucketArn という専用のクラスを使っています。
これらのクラスは、次のように共通の親クラス Token を拡張しています。
class BucketName extends Token { ... }
class BucketArn extends Arn { ... }
class Arn extends Token { ... }
現在では、このように Token クラスを拡張して使うことはありません。
しかし今回のテーマであるトークン (token) は、昔も今もこのように何らかの値を表す仕組みとして、AWS CDK のあちこちで使われています。
あちこちで使われてはいますが、トークンの主な使いどころであり、設計・実装に大きな影響があるのは、バケット名や ARN といったリソースの物理名や属性です。 トークンを理解するには、先に物理名や属性、関連する概念について理解していなければなりません。
そこでまずは、トークンの前提知識となる以下の用語を説明します。
- シンスタイムとデプロイタイム
- 論理名、物理名、組み込み関数
シンスタイムとデプロイタイム
AWS CDK アプリをシンセサイズしている時とデプロイしている時を、それぞれシンスタイム (synth(esis) time) 、デプロイタイム (deploy time) と言います。 この二つはよく対で使われ、次の図のようにクラウドアセンブリを境に AWS CDK の処理を大きく二つに分ける用語と言えます。
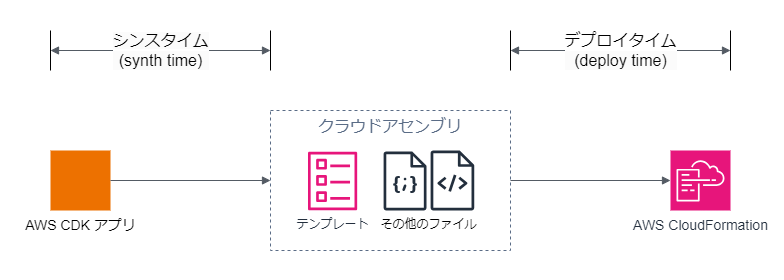
シンスタイムは分けようと思えばさらに細かい処理に分けられます。 コンストラクトツリーを生成する処理や、コンストラクトの設定が妥当かチェック(バリデーション)する処理などです。 また前回見たとおりデプロイタイムも、アセットのパブリッシュと AWS CloudFormation テンプレートのデプロイという、少なくとも二段階の処理に分けられます。
けれどもそれら細かい処理は、理路整然と概念化されているようでそうでもないような、判断に迷うところがあります。
AWS CDK v2 の『Developer Guide』では、アプリのライフサイクル (app lifecycle) の図を描き、シンスタイムを四つのフェーズ “Construct(ion)” → “Preparation” → “Validation” → “Synthesis” に分けて説明しています。 この “Synthesis” を狭い意味でのシンスタイムとみなす場合もあります。
しかしその図が描かれたのは v1 が GA になる前であり、その説明文も v2 では既に廃止されているコンストラクト関連の prepare メソッドを含むなど、古くなってしまっています。
またデプロイタイムは、パブリッシュもデプロイも “Deploy” という一つのフェーズで説明されています。
それらは現在の実装や、実装のもとになったであろう AWS CDK RFC の 0049, 0192 あたりを踏まえて、あらためて見直し・修正が必要でしょう。
この連載では、特に必要ないかぎり細かく処理は分けず、シンスタイムとデプロイタイムで大きく分けて説明していきます。
論理名、物理名、組み込み関数
次にトークンの前提知識となる AWS CloudFormation の用語をいくつか説明します。
リソースの論理名
EC2 インスタンスや S3 バケットなど、CloudFormation で管理するリソースには論理名 (logical name) という名前が必要です。 論理名は論理 ID (logical ID) とも呼ばれ、テンプレートの中で一意な値でなければなりません。
以下の例において、論理名は Ec2Instance と S3Bucket です。
{
"Resources": {
"Ec2Instance" : {
"Type" : "AWS::EC2::Instance"
},
"S3Bucket": {
"Type": "AWS::S3::Bucket"
}
}
}
リソースの物理名
論理名とは別に、リソースには物理名 (physical name) や物理 ID (physical ID) と呼ばれるもう一つの名前があります。
物理名はリソースによって異なり、たとえば EC2 インスタンスは i-1234567890abcdefg のようなインスタンス ID が、S3 バケットは s3bucket-123456abcdef のようなバケット名が物理名です。
論理名をテンプレートの中で通用する仮の名前とするならば、物理名はテンプレートの外で通用する真の名前です。
物理名はテンプレートを離れたさまざまな場面で用いられます。
例えば AWS CLI のコマンド aws s3 ls s3://<バケット名> を実行すると指定したバケットのオブジェクトを一覧できます。
物理名の自動生成
基本的に、物理名は開発者が命名せず、CloudFormation がリソースを作成するときに自動生成します。 上のテンプレートの例でも、物理名は指定していないので自動生成されます。
自動生成される物理名は、他の物理名と同じにならないように生成されます。
そのおかげで、同じテンプレートを用いて繰り返しリソースを作成しても、物理名が衝突してエラーになることを避けられます。
しかしそのために、自動生成される物理名には 123456abcdef のような意味の分からない文字列が含まれ、見分けづらくなるという欠点があります。
物理名のカスタマイズ
一部のリソースでは、物理名を自動生成する代わりに自分で考えたカスタム名を付けられます。
以下の例では、バケット名としてカスタム名 custom-bucket-name を指定しています。
{
"Resources": {
"S3Bucket": {
"Type": "AWS::S3::Bucket",
"Properties": {
"BucketName": "custom-bucket-name"
}
}
}
}
カスタム名を付ける際の注意事項や、どのリソースに付けられるのかなど、詳しくは CloudFormation 公式ガイドの『Name type』を参照してください。
組み込み関数
カスタム名を付けない・付けられないリソースは、物理名が具体的にどんな文字列になるか、デプロイするまで決まりません。 また ARN などリソースの多くの属性 (attribute) もデプロイするまで決まりません。
先ほど説明した AWS CDK の用語でいうと、シンスタイムには決まらずデプロイタイムに決まる属性が、リソースにはいくつもあるのです。 そのような属性であっても、CloudFormation テンプレートでは組み込み関数 (intrinsic function) を使えばうまくあつかえます。
{
"Resources": {
"S3Bucket": {
"Type": "AWS::S3::Bucket"
}
},
"Outputs": {
"BucketName": {
"Value": { "Ref": "S3Bucket" }
},
"BucketArn": {
"Value": { "Fn::GetAtt": [ "S3Bucket", "Arn" ] }
}
}
}
Ref は論理名を指定すると物理名などそのリソースを参照するための値を返す関数です。
上の例の Outputs セクションでは、{ "Ref": "S3Bucket" } を用いて論理名が S3Bucket である S3 バケットのバケット名を出力しています。
Fn::GetAtt は論理名と属性名を指定すると、そのリソースの属性値を返す関数です。
上の例の { "Fn::GetAtt": [ "S3Bucket", "Arn" ] } は、論理名が S3Bucket である S3 バケットの ARN を出力しています。
バケット名は自動生成であり、ARN ともどもデプロイタイムまで決まらない値です。
シンスタイムが終わってもまだこの世に存在しない値なわけですが、それでもこのように Ref や Fn::GetAtt など組み込み関数を用いると記述できるのです。
トークンの使いどころ
さて、ここまでの説明をもとに、トークンの使いどころである物理名や ARN の特徴をまとめると以下のようになります。
1. 具体的な値が最初に決まらず、もっと後で決まる
「最初」とは、コンストラクトの場合 AWS CDK アプリの中で new した初期状態でということです。
たとえば Bucket コンストラクトを new した直後は、自動生成するバケット名や ARN は決まっていません。
決まるのは「もっと後」、値を決めるための情報や条件が全部そろった後です。 自動生成するバケット名や ARN にとって、その時とはデプロイタイムです。
2. デプロイ用の言語で記述されることがある
第1回で述べたように、開発者は AWS CDK アプリという抽象化されたものを開発するのであって、CloudFormation やテンプレートという具体的な実体には直接ふれません。 もちろん現実的には AWS CDK と CloudFormation は切っても切れない関係にありますが、概念的には CloudFormation はたまたまデプロイのために使っているバックエンドのサービスにすぎないのです。
よって Bucket のように抽象度の高い L2 コンストラクトでは、バケット名や ARN の値として組み込み関数など CloudFormation の言語をそのまま設定するわけにはいきません。
Bucket の bucketName プロパティを Outputs セクションに出力しようとしても、その bucketName には { "Ref": "S3Bucket" } のような値は設定されていないのです。
にもかかわらず、シンスタイムが終わったときには、テンプレートは CloudFormation の言語で記述されていなければならないのです。
トークンの実体
以上をふまえて、ここからは具体的にトークンの仕組みや使い方を見ていきましょう。
はじめに紹介したとおり、初期のトークンは Token クラスのオブジェクトとして実装されていました。
Token が表現したいものは、バケット名や ARN など何かしらの値です。
現在のトークンは Token クラスではなく、IResolvable インターフェースを持つオブジェクトとして実装します。
IResolvable を実装していれば、コンストラクトでもふつうのクラスでもなんでもトークンになれます。
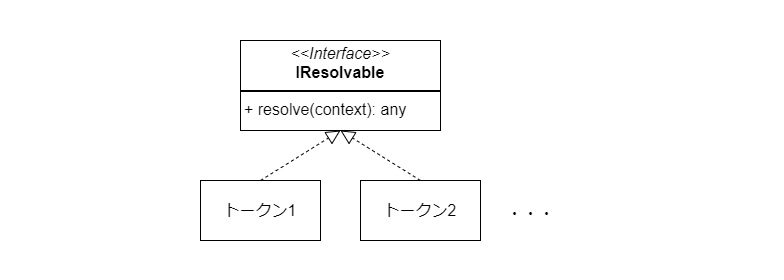
トークンの解決
各トークンは IResolvable の resolve メソッドを実装しなければなりません。
resolve メソッドを呼び出すと、戻り値としてそのトークンが表したい実際の値が得られます。
このことを、トークンを解決する (resolve) といいます。
トークンは AWS CDK アプリのあちこちで使われますが、すべてシンスタイムに解決されます。 CloudFormation テンプレートなどクラウドアセンブリは、それら解決した値をもとにして出力されます。 解決するのは通常 AWS CDK のコアフレームワークの役目であり、アプリの開発者は気にする必要はありません。
トークンのエンコード
Bucket など L2 コンストラクトは、トークンを IResolvable のオブジェクトそのままでは使いません。
代わりにトークンを string など別の型にエンコード (encode) して使います。
エンコードされたトークンは、冒頭で紹介したとおり ${Token[TOKEN.101]} のようなちょっと変わった見た目をしています。
エンコードされたトークンは、もとのトークンと一対一の関係にあります。 その関係は、マップ (Map) として AWS CDK アプリが見えないところで管理しています。 一対一の関係が管理されているおかげで、もとのトークンを知らなくても、エンコードされたトークンをもとにトークンを解決できます。
エンコードされたトークンの例:Bucket
例として、以下の AWS CDK アプリを見てみましょう。
import * as core from 'aws-cdk-lib/core'
import * as s3 from 'aws-cdk-lib/aws-s3'
const app = new core.App()
const stack = new core.Stack(app)
const bucket = new s3.Bucket(stack, 'Bucket')
// バケット名
const bucketName: string = bucket.bucketName
// ARN
const bucketArn: string = bucket.bucketArn
// Outputs セクション
new core.CfnOutput(stack, 'BucketName', {
value: bucketName
})
new core.CfnOutput(stack, 'BucketArn', {
value: bucketArn
})
CfnOutput は、AWS CloudFormation テンプレートの Outputs セクションを表すコンストラクトです。
この例では、作成するバケットのバケット名 (bucketName) と ARN (bucketArn) をテンプレートに出力しようとしています。
S3 バケットの L2 コンストラクト s3.Bucket を new するとき、プロパティには何も設定していません。
けれども取得できるバケット名と ARN は string 型ですので、undefined ではない何らかの値がデフォルトで設定されているはずです。
何が設定されているのか確かめるため、次のようにログを出力するコードを追加します。
console.log('bucketName', '=', bucketName)
console.log('bucketArn', '=', bucketArn)
そうして cdk synth コマンドでシンセサイズすると、次のようなログが出力されます。
bucketName = ${Token[TOKEN.22]}
bucketArn = ${Token[TOKEN.23]}
バケット名や ARN というと、想像されるのはそれぞれ my-bucket-name や arn:aws:s3:::my-bucket-name のような文字列です。
ところが s3.Bucket は、new されるとこのようにエンコードされたトークンを設定するのです。
このエンコードされたトークンを解決してみます。
ふつうはアプリの開発者がトークンを解決することはありませんが、もし解決したいときは Stack コンストラクトの resolve メソッドが使えます。
resolve メソッドの引数に指定するトークンは、エンコードされたトークンでも、もとのトークンでもかまいません。
console.log('resolved bucketName', '=', stack.resolve(bucketName))
console.log('resolved bucketArn', '=', stack.resolve(bucketArn))
この例では、エンコードされたトークンを解決しています。 出力されるログを見ると、以下のとおり CloudFormation の組み込み関数が得られることが分かります。
resolved bucketName = { Ref: 'Bucket123488AA' }
resolved bucketArn = { 'Fn::GetAtt': [ 'Bucket123488AA', 'Arn' ] }
Bucket123488AA はバケットの論理名です。
末尾の 123488AA は、論理名が重複しないよう AWS CDK コアフレームワークが生成したものです1。
このようにトークンを解決するというのは、固定の値を返すことではありません。論理名など必要な情報や条件がそろうのを待ち、それらをふまえた上で最終的な値を決める処理なのです。
これら解決した値を用いて、テンプレートは以下のように出力されます。
{
"Resources": {
"Bucket123488AA": {
"Type": "AWS::S3::Bucket"
}
},
"Outputs": {
"BucketName": {
"Value": { "Ref": "Bucket123488AA" }
},
"BucketArn": {
"Value": { "Fn::GetAtt": [ "Bucket123488AA", "Arn" ] }
}
}
}
三種類のエンコード
上の例を含め、エンコードされたトークンは以下の三種類があります。
1. string トークン
TypeScript の string 型にエンコードされたトークン (string-encoded token) です。
上の例で見た、バケット名や ARN のエンコードはこれです。
次の例のように、先頭の ${Token[ が目印です。
${Token[TOKEN.101]}
大文字 TOKEN の代わりに、Bucket.Name のようなトークンの表す値を示唆する文字列が入っていることもあります。
末尾の 101 はトークンごとにカウントアップされるカウンターの値です。
エンコードされたトークンとともに、カウンターも開発者には見えないところで管理されています。
2. リストトークン
string[] 型にエンコードされたトークン (list-encoded token) です。
次のように、先頭の #{Token[ が目印です。
[ '#{Token[TOKEN.102]}' ]
大文字の TOKEN や末尾の 102 は上の string トークンと同様です。
3. number トークン
number 型にエンコードされたトークン (number-encoded token) です。
次のように、絶対値の大きな負の数の指数表記が目印です。
-1.8765432123456789e+289
見た目からは読みとれませんが、やはりトークンごとにカウントアップされるカウンターが管理されています。
エンコード用のメソッド
これら三種類のエンコードを行うには、それぞれ以下の Token クラスの static メソッドを使います。
Token.asString(value: any, options?: EncodingOptions): stringToken.asList(value: any, options?: EncodingOptions): string[]Token.asNumber(value: any): number
各メソッドの引数 value にトークンを渡すと、エンコードされたトークンを返してくれます。
value の型は any なので、トークンではないもの、つまり IResolvable を実装していないオブジェクトや文字列なども渡せます。
その場合、value からトークンを生成し、エンコードして返してくれます。
もしもトークンを自作しようと思ったら、独自に IResolvable インターフェースを実装する前にこれら Token.asXXXX メソッドが利用できないか検討するとよいでしょう。
これら Token.asXXXX メソッドはエンコードとともに、もとのトークンとの一対一のマッピングやカウンターのカウントアップもしてくれます。
トークンでできること、できないこと
string トークンは、他の文字列と結合したり文字列補間 (string interpolation) したりできます。
// `string` トークン
const stringToken: string = Token.asString({ Ref: 'Bucket123488AA' })
// 文字列補間
console.log(`This is a bucket name: ${stringToken}`)
// 解決一回目
const resolved = stack.resolve(`This is a bucket name: ${stringToken}`)
console.log(resolved)
// 解決二回目
console.log(stack.resolve(resolved['Fn::Join']))
この例の出力結果は次のようになります。
This is a bucket name: ${Token[TOKEN.101]}
{ 'Fn::Join': [ '', [ 'This is a bucket name: ', [Object] ] ] }
[ '', [ 'This is a bucket name: ', { Ref: 'Bucket123488AA' } ] ]
解決一回目では、組み込み関数 Fn::Join を用いた値が得られました。
さらに解決二回目では、一回目で [Object] だったものが組み込み関数 { Ref: 'Bucket123488AA' } に解決されました。
このように文字列補間しても解決できるのは、文字列補間の結果 This is a bucket name: ${Token[TOKEN.101]} を解析し、Fn::Join のように適切な組み込み関数を適用する処理が作り込まれているからです。
多くの場合そのような処理は実装されていない・できないため、string トークンはふつうの string ならできることの多くができません。
たとえば、次のように split や substring をしてみます。
stringToken.split('T')
stringToken.substring(3)
この結果、エラーにはなりませんが、得られるのは次のように意味のない文字列です。
[ '${', 'oken[', 'OKEN.101]}' ]
oken[TOKEN.101]}
この結果を解決できないことは明らかでしょう。 一対一の関係にあるもとのトークンが無いからです。
このように、バケット名などエンコードされたトークンが設定される可能性があるものについては、どのような処理ができるか・できないか注意する必要があります。
対応策の一つとして、以下のように Token クラスの isUnresolved メソッドを用いてトークンかどうか判定し、処理を分岐させる方法があります。
if (!Token.isUnresolved(bucketName)) {
// bucketName がトークンでない場合だけ、通常の string の処理を実行する
}
ただし、あらかじめ完璧にこのような対策をできるかというと、なかなかそうはいかないでしょう。
AWS CDK 本体でも isUnresolved で判定せずにバグとなった事例があるくらいです。あまり神経質になりすぎず、問題が発生したら対処できるようおぼえておく、くらいの心持ちでいようと筆者は思っています。
Lazy とは
以上のように Token クラスから始まり、IResolvable インターフェースやエンコードの仕組みを導入して発展してきたトークンは、その後 Lazy という仕組みを導入するに至りました。
Lazy はトークンの一種です。
主に Lazy というクラスを用いて操作しますが、内部ではここまで説明したトークンの仕組みを使用しています。
Lazy クラスには静的メソッド Lazy.string や Lazy.list がありますが、それらも内部では Token.asXXXX メソッドを呼び出しており、エンコードされたトークンを返します。
Lazy クラスの詳しい使い方は公式ドキュメントを参照してください。
Lazy の使いどころ
Lazy の主な目的は、デプロイタイムまで待たずともシンスタイムで具体的な値が決まるものを区別することです。 よく Lazy が使われるのは、状態を変更できるメソッドを提供しているコンストラクト、つまりミュータブル (mutable) なコンストラクトの中です。
たとえば Bucket コンストラクトは、バケットのライフサイクルルールを追加する addLifecycleRule メソッドを提供しており、Bucket を new した後でルールが変わる可能性があります。
けれども、シンスタイムが終わり CloudFormation テンプレートが出力されたときにはルールは決まっています。
つまり、アプリの都合ですぐに決めないだけで、組み込み関数 { Ref: ... } で参照するバケット名などとは異なり、デプロイタイムまで決まらない値ではないのです。
そのような場合には Lazy を使います。
string 型の理由
トークンの仕組みについては以上なのですが、それではなぜ冒頭で紹介したように L2 のプロパティは BucketName 型ではなく string 型になったのでしょうか?
当時の GitHub の Issue を見てみると、その大きな理由はいわゆる開発者体験 (developer experience) だったことがわかります。
開発を主導していた Elad Ben-Israel 氏によると、string であるリソースの属性は CDK のコードとしても string にするのが自然 (“the experience will be natural”) なのだそうです。
たとえばバケット名に抽象的な BucketName 型を適用した場合、具体的な string 型のバケット名が必要な場面では string 型に変換する何らかの処理が必要です。
一つの候補として toString() メソッドがありますが、string が必要なときに毎回 toString() を呼ぶのは、良い開発者体験ではないというわけです。
このような考え方に対し、反論もありました。
BucketName 型ではなく、string | Token のような Union 型や、Token<string> のような Generics を活用する方法も提案されました。
そうした意見に対し Elad Ben-Israel 氏は、認知負荷 (cognitive load) やエルゴノミクス (ergonomics) といった人間の心理や特性に関する言葉を持ち出し、string 型である利点を説いています。
BucketName のような型を導入することは現実的な使いやすさを損なうものであり、氏に言わせればオーバーモデリング (over-modeling)、つまり行きすぎた抽象化だったのです。
おわりに
今回はトークンについて説明しました。 また前提知識として、シンスタイムとデプロイタイム、論理名と物理名なども説明しました。
現在のトークンの仕組みは、いくつもの案を何度も検討した上で実現したものです。 それらの概要は紹介しましたが、さらに詳しく知りたい方は下記の参考資料をご覧ください。
参考資料
AWS CDK の公式 Twitch 動画『CDK Construction Zone | S1 E4 | Tokens』では、AWS CDK の初期からの主要な開発者である Rico 氏らが、コードを示しながらトークンについて詳しく説明しています。 トークンの数少ない解説の一つであり、この記事を書くにあたっても大いに参考にしています。
初期から現在のトークンまで、どのような検討がなされていたかは GitHub の Issue/PR から窺い知ることができます。 以下は、筆者が参考にした主なものです。
- Proposal: Token.toString() · Issue #24
- Interchangeability of Tokens and Literals · Issue #168
- Framework: Tokens can be converted to strings by rix0rrr · Pull Request #518
- Do we really need strong types for all attribute types? · Issue #695
- Change the usage of tokens for lazy evaluation · Issue #736
- Revisit tokens APIs · Issue #1933
- refactor(core): refactor API of Tokens by rix0rrr · Pull Request #2757
-
説明のためこれまでの連載では省略してきましたが、ここでは逆に説明のため省略しませんでした。 ↩