
前回、Clair には大きく2つの機能があることを説明しました。「既知の脆弱性情報の取得」と「イメージのスキャン」です。この2つのうち、今回は「既知の脆弱性情報の取得」を行う Fetcher コンポーネントについて解説します。前半は Fetcher の概要について解説し、後半はソースコードを見ながら、Fetcher が具体的にどのような処理を行っているかについて解説します。
Fetcher は既知の脆弱性情報をデータソースから取得する
前回解説したとおり、Clair はイメージをスキャンして既知の脆弱性を検出するためのプラットフォームです。 「既知」というのは、既に誰かがどこかで報告済みということです。 Clair はどこにも報告されていない「未知」の脆弱性は検出しません。
Clair は既知の脆弱性情報とイメージに含まれているソフトウェアの情報とを突き合わせて、その脆弱性が存在するかどうかを判定します。 そのため、予めどこかから既知の脆弱性情報を取得しておかなければ脆弱性を検出することはできません。
既知の脆弱性情報の取得元をデータソース (Datasource) といいます。 今回解説する Fetcher コンポーネントは、既知の脆弱性情報をデータソースから取得するコンポーネントです。
Fetcher の処理の概要
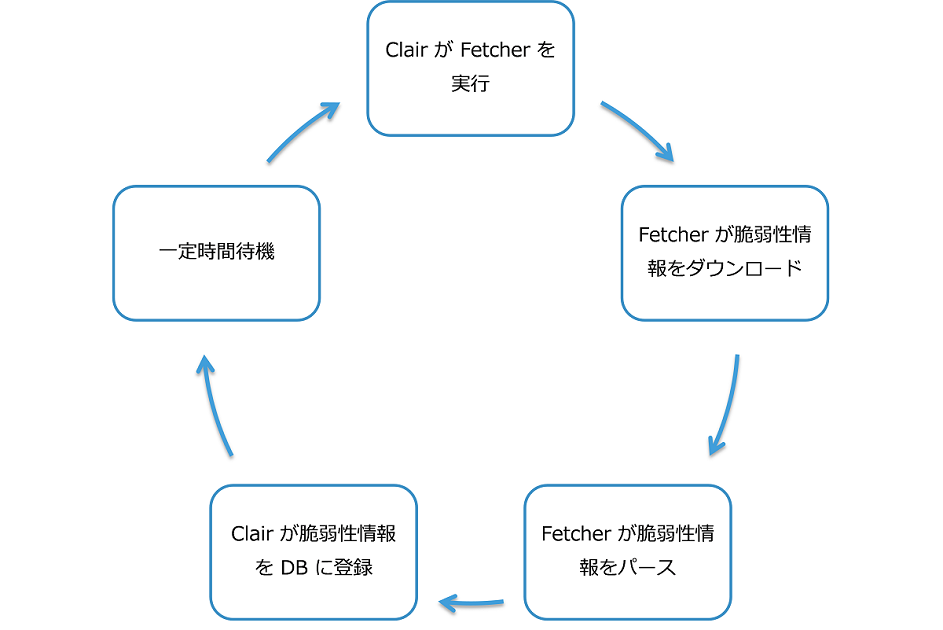
Fetcher は、Clair を起動すると自動的に実行され、脆弱性情報を取得します。 Fetcher が行う処理は、大きく次の2つに分けられます。
データソースから脆弱性情報をダウンロードする
Fetcher が利用するデータソースは、基本的にインターネット上に存在します。 インターネット上には、OS やソフトウェアの開発元やコミュニティ等が脆弱性情報を公開しており、ライセンスの範囲内でダウンロードして利用することができます。
ダウンロードした脆弱性情報をパースする
各データソースは様々な形式で脆弱性情報を公開しています。 例えば、Red Hat のデータソースである Red Hat Security Data は、OVAL という XML形式で脆弱性情報を公開しています。 OVAL は業界標準となることを目指していますが、すべてのデータソースが OVAL を採用しているわけではありません。 例えば Debian は JSON形式ですし、Ubuntu は「キー: 値」という形式です。 Fetcher はそうした各データソースの形式に沿って脆弱性情報をパースします。
Fetcher はパースした結果を、Clair の標準的なデータ構造 (後半で説明する FetcherResponse) に変換して Clair 本体に返します。
Clair 本体は、Fetcher から受け取ったデータをデータベース(PostgreSQL)に登録します。
一定時間が経過すると、Fetcher は再び自動的に実行され、最新の脆弱性情報を取得します。 Clair は Fetcher を定期的に実行して、脆弱性情報を最新の状態に保つのです。
Fetcher はイロイロ、自作もできる
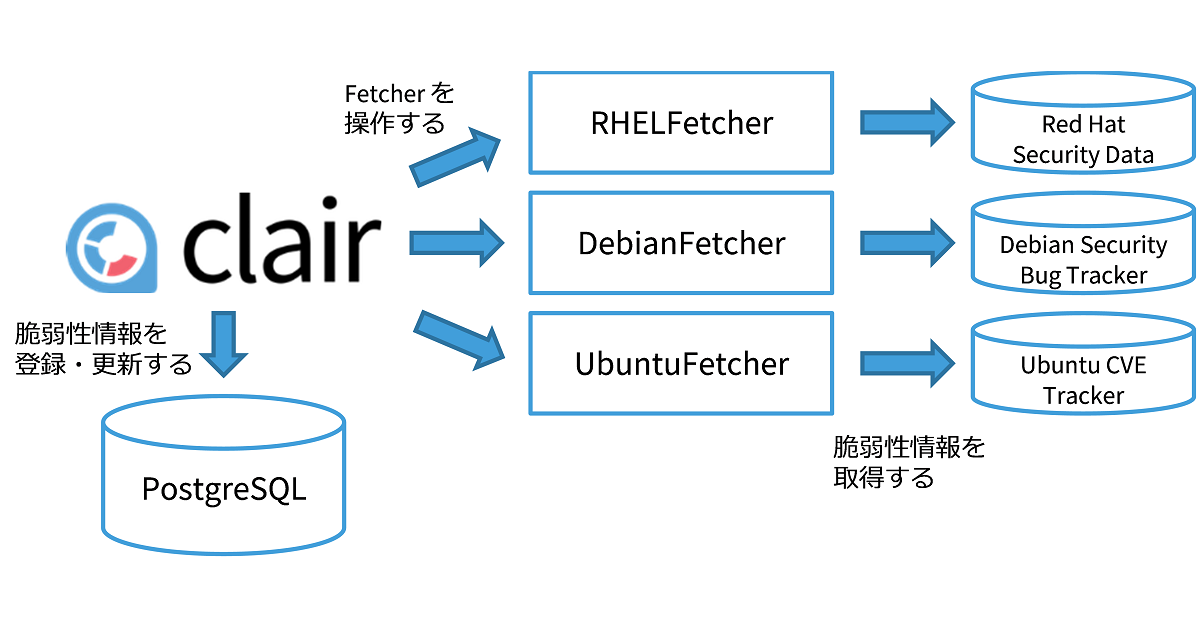
Fetcher は予めいくつか Clair に組込まれています。 本稿執筆時の最新版 v1.2.6 には、以下の Fetcher が組込まれています。
| Fetcher | データソース | フォーマット |
|---|---|---|
| RHELFetcher | Red Hat Security Data | OVAL |
| DebianFetcher | Debian Security Bug Tracker | JSON |
| UbuntuFetcher | Ubuntu CVE Tracker | 「キー: 値」 |
これら Red Hat (CentOS), Debian, Ubuntu の他にも、Oracle Linux や Alpine Linux 向けの Fetcher の開発も進められています。 Alpine は Docker イメージで利用されることが増えてきている Linux ディストリビューションです。 Alpine のようにイメージとして人気のある OS の Fetcher は、今後も随時追加されていくと思われます。
もしも自分が利用したい Fetcher が存在しない場合は自作することも可能です。 後半で説明するインタフェース等、所定のルールに従って実装すれば、独自の Fetcher を Clair に組込んで利用することができるのです。
このように既存のものや自作のものを、必要に応じて取捨選択できるのが、コンポーネントである Fetcher の利点です。
データソースどうしましょう? ~ npm の Fetcher の場合 ~
どの Fetcher を利用すれば良いか考える際に重要なポイントが、どのデータソースを利用しているかです。 しかしながら、どのデータソースを利用すべきか判断することは、それほど簡単なことではありません。
その良い例が npm の Fetcher です。 npm とは、Node.js (JavaScript) のパッケージ管理ツールです。 npm の Fetcher は、約1年ほどデータソースを Snyk というものと nsp というもののどちらにするかで揺れ動き、未だ完成には至っていません。(2016年末時点)
Clair の GitHub Issue #40, #175 によると、npm の Fetcher の開発は次のような経過をたどっています。
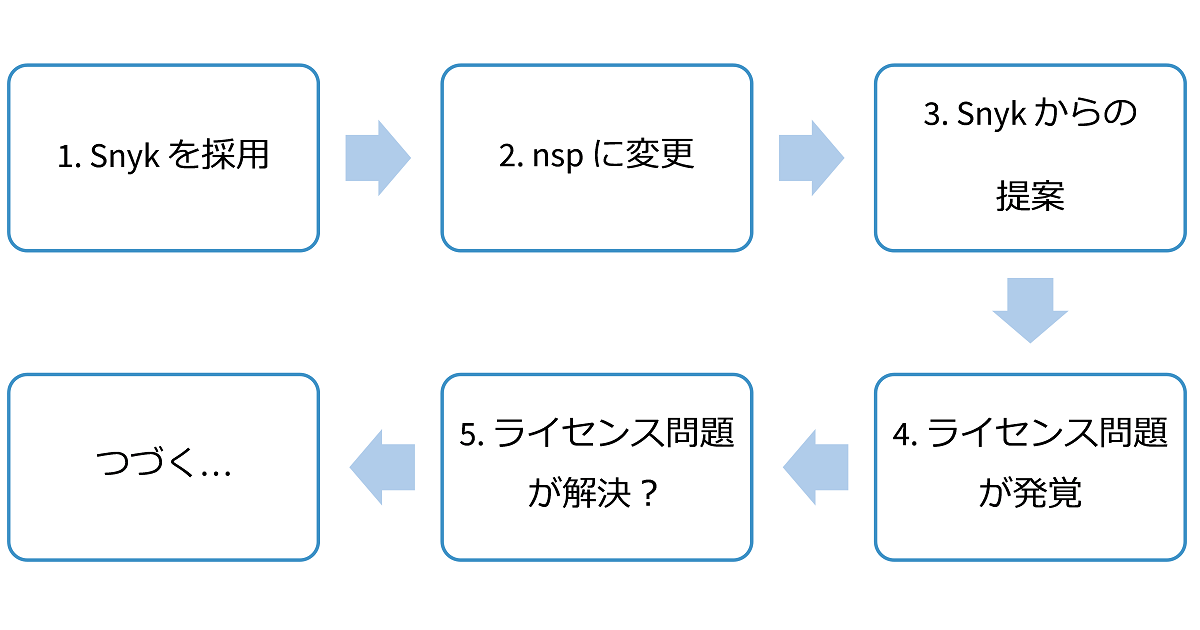
Snyk を採用
2015年12月、Snyk に関する短いコメントとともに Issue #40 が作成されました。 作成したのは Clair の開発元である CoreOS社の CTO です。 おそらくこの頃、npm の Fetcher について CoreOS社内で検討が進められていたのでしょう。 翌2016年3月、#40 のタイトルが「New Fetcher for NPM CVE Snyk Database」へと変更され、Snyk をデータソースとする Fetcher の開発が本格的にスタートしたようです。
nsp に変更
2016年4月、Clair の主要なメンテナから、Snyk よりも良いデータソースがあるのでは?というコメントが付きました。Snyk の脆弱性情報は nsp から取得しているようなので、Clair も nsp をデータソースとして直接利用した方が良いのでは?というわけです。
検討の結果、Snyk から nsp にデータソースが変更されました。 理由は、Snyk よりも nsp の方がデータの鮮度が高いこと、Snyk は脆弱性情報をダウンロードするために Git のコマンドを使うが nsp は Web API が使えること等です。
Snyk からの提案
nsp をデータソースとする Fetcher の開発がかなり進んだ頃、Snyk の CEO から、データソースとして Snyk を使いませんか、というコメントが付きます。 このコメントの主な内容は、Snyk を使う利点(Snyk が提供するパッチが使える)や実装上のアドバイスだったのですが、軽く Snyk と nsp のライセンスに言及したことで、この後の話題の中心はライセンスに移ります。
ライセンス問題が発覚
ひと月以上経過した後、nsp のライセンスに関するコメントが付きました。 Snyk の提案どおりにすると nsp の許可がおりないかもしれない、Clair を有償の製品に組込む場合は別途 nsp の有償ライセンスが必要かもしれない、等です。
ライセンス問題が解決?
さらにその3か月後の2016年12月、これで nsp のライセンス問題は解決するのでは? というニュースを紹介するコメントが付きました。 どうやら nsp の管轄が、一企業である ^Lift Security から 中立的な団体である Node.js Foundation へ移るということのようです。
果たしてこれで本当にライセンス問題は解決するのでしょうか? また、管轄が移ったことで Snyk や nsp を利用するための実装に影響は出て来ないのでしょうか?
このように、データの鮮度、ダウンロード方法、ライセンス等によって、どのデータソースを利用すべきかという判断は変わってきます。 判断するために必要十分な情報を予め入手できるかというと、Clair の開発元でさえ難しいようです。 また、nsp の管轄が変わったように、それらの情報は時と共に変化するものです。
「既知の脆弱性情報の取得」という処理が Fetcher という形でコンポーネント化されている理由は、 こうした変化に対応するためでもあると言えるでしょう。
Fetcher の実装を見てみましょう
さて、ここからは Clair のソースコード (v1.2.6) を参照しながら、Fetcher が具体的にどのような処理を行っているのかを見ていきましょう。 Clair は Go言語で実装されていますので、Go言語で不明な点があればチュートリアル等をご覧ください。
Fetcher は共通のインタフェースを実装している
全ての Fetcher は以下の Fetcher インタフェースを実装しています。
独自の Fetcher を自作する場合もこの Fetcher インタフェースを実装します。
type Fetcher interface {
// データソースから脆弱性情報を取得する
FetchUpdate(database.Datastore) (FetcherResponse, error)
Clean()
}
type FetcherResponse struct {
FlagName string
FlagValue string
Notes []string
// 脆弱性情報
Vulnerabilities []database.Vulnerability
}
脆弱性情報を取得するために、Clair 本体は各 Fetcher の FetchUpdate メソッドを呼出します。
そして、その戻り値 FetcherResponse を基にして PostgreSQL に脆弱性情報を登録します。
こうした操作は、既存の Fetcher であっても自作の Fetcher であっても同じです。
Fetcher インタフェースのおかげで、Clair は異なる Fetcher を同じように操作できるわけです。
UbuntuFetcher はどのような処理をしているか
Fetcher の具体例として、UbuntuFetcher (ubuntu.go) の処理を見てみましょう。
インターネット上にある Bazaar ブランチをコピーする
UbuntuFetcher のデータソースである Ubuntu CVE Tracker は、Bazaar レポジトリで脆弱性情報を公開しています。 Bazaar は、Git 等のバージョン管理システムの一種です。
Bazaar レポジトリの URL は、以下のように定数で記述されています。
const (
trackerRepository = "https://launchpad.net/ubuntu-cve-tracker"
)
この URL を引数にして、UbuntuFetcher は bzr branch コマンドを実行します。
out, err := utils.Exec("/tmp/", "bzr", "branch", trackerRepository, pathToRepo)
これで一時ディレクトリに以下のようなブランチのコピーが生成されます。
/tmp/ubuntu-cve-tracker123456789/repository/
active/
CVE-2002-2439
CVE-2004-2771
CVE-2015-4471
CVE-...
retired/
CVE-1999-1572
CVE-2001-0775
CVE-2001-1413
CVE-...
README
脆弱性情報のファイルをパースする
上記ブランチのコピーの README を読むと、以下のことが分かります。
- 「active」ディレクトリには未解決の脆弱性情報が格納されている
- 「retired」ディレクトリには解決済みの脆弱性情報が格納されている
- 脆弱性情報はそれぞれ「CVE-*」ファイルとして格納されている
「CVE-*」ファイルは以下のようなテキストファイルです。
Candidate: CVE-2015-4471
PublicDate: 2015-06-11
References:
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2015-4471
https://www.openwall.com/lists/oss-security/2015/02/03/11
https://github.com/kyz/libmspack/commit/18b6a2cc0b87536015bedd4f7763e6b02d5aa4f3
https://bugs.debian.org/775499
https://openwall.com/lists/oss-security/2015/02/03/11
Description:
Off-by-one error in the lzxd_decompress function in lzxd.c in libmspack
before 0.5 allows remote attackers to cause a denial of service (buffer
under-read and application crash) via a crafted CAB archive.
Ubuntu-Description:
Notes:
Bugs:
https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=775499
Priority: medium
Discovered-by:
Assigned-to:
Patches_libmspack:
upstream_libmspack: released (0.4-3)
precise_libmspack: DNE
trusty_libmspack: needed
utopic_libmspack: ignored (reached end-of-life)
vivid_libmspack: not-affected (0.5-1)
vivid/stable-phone-overlay_libmspack: DNE
vivid/ubuntu-core_libmspack: DNE
wily_libmspack: not-affected
xenial_libmspack: not-affected
yakkety_libmspack: not-affected
devel_libmspack: not-affected
UbuntuFetcher は、この「CVE-*」ファイルをパースし、戻り値となる脆弱性情報を抽出していきます。
抽出した値は Vulnerability 構造体に格納されます。
この Vulnerability の値は、後に Clair によって PostgreSQL に登録されます。
type Vulnerability struct {
Name string
Link string
Severity types.Priority
// 他の項目は省略
}
例えば「Candidate」の値は CVE-ID(CVE が脆弱性に付与している一意の識別子)なのですが、これは脆弱性の名称 (Name) や参照URL (Link) の一部として抽出します。
if strings.HasPrefix(line, "Candidate:") {
vulnerability.Name = strings.TrimSpace(strings.TrimPrefix(line, "Candidate:"))
vulnerability.Link = fmt.Sprintf(cveURL, vulnerability.Name)
continue
}
「Priority」は Ubuntu が独自に定義している脆弱性の優先度です。 似たような指標を、Red Hat や Debian 等、他のデータソースもそれぞれ独自に定義しています。 このままでは、異なるデータソース同士で比較して優先度の高い脆弱性から対策を打つ、というようなことが困難です。 そこで、Clair は「Priority」を、Clair が定義する 「Severity(重大度、深刻度)」に変換します。
type Priority string
const (
Unknown Priority = "Unknown"
Negligible Priority = "Negligible"
Low Priority = "Low"
Medium Priority = "Medium"
High Priority = "High"
Critical Priority = "Critical"
Defcon1 Priority = "Defcon1"
)
func ubuntuPriorityToSeverity(priority string) types.Priority {
switch priority {
case "untriaged":
return types.Unknown
case "negligible":
return types.Negligible
case "low":
return types.Low
case "medium":
return types.Medium
case "high":
return types.High
case "critical":
return types.Critical
}
log.Warning("Could not determine a vulnerability priority from: %s", priority)
return types.Unknown
}
以上、UbuntuFetcher がどのような処理をしているのかを見て来ました。
これらの処理は、UbuntuFetcher 構造体に対し、Fetcher インタフェースの FetchUpdate メソッドとして実装されています。
これまで UbuntuFetcher と呼んできたものの実体は、FetchUpdate メソッドのレシーバとなる UbuntuFetcher 構造体のことだったのです。
type UbuntuFetcher struct {
repositoryLocalPath string
}
func (fetcher *UbuntuFetcher) FetchUpdate(datastore database.Datastore) (resp updater.FetcherResponse, err error) {...}
Fetcher を自作する場合は、この UbuntuFetcher のように、対象のデータソースの仕様に合わせて、データのダウンロード処理やパース処理を FetchUpdate メソッドとして実装することになります。
まとめ
今回は、既知の脆弱性情報を取得する Fetcher コンポーネント について解説しました。 次回は、イメージをスキャンする Detector コンポーネントについて解説する予定です。