
本連載の第1回で、Clair には大きく2つの機能があることを説明しました。ひとつは「既知の脆弱性情報の取得」、もうひとつは「イメージのスキャン」です。前回解説した Fetcher コンポーネントは「既知の脆弱性情報の取得」を行うコンポーネントでした。今回解説する Detector コンポーネントは「イメージのスキャン」を行うコンポーネントです。スキャン (scan) とは簡単に言うと「細かく調べる」ということですが、その具体的な内容を理解するには、調べる対象であるイメージについても少し細かい知識が必要です。そこでまず始めに予備知識として、イメージの構成要素であるレイヤー (layer) について見ていきたいと思います。
イメージとはレイヤーを積み重ねたもの
第1回で説明したとおり、Docker のイメージは、コンテナを作成し動かすために必要なものをひとまとめにしたものです。 必要なものとは、主にアプリケーションやミドルウェア等のファイルのことなのですが、それらのファイルは、ただ雑然とひとまとめにされているわけではなく、いくつかのグループに分けてまとめられています。 その分かれているグループのことを レイヤー (layer) と言います。
次の図は、イメージとそのレイヤー構成の例です。 イメージとしては1つに見えるファイル構成が、実は3つのレイヤーに分かれているということを表しています。 このように、イメージはレイヤーをいくつも積み重ねて1つのファイル構成として扱えるようにしたものであると言えます。
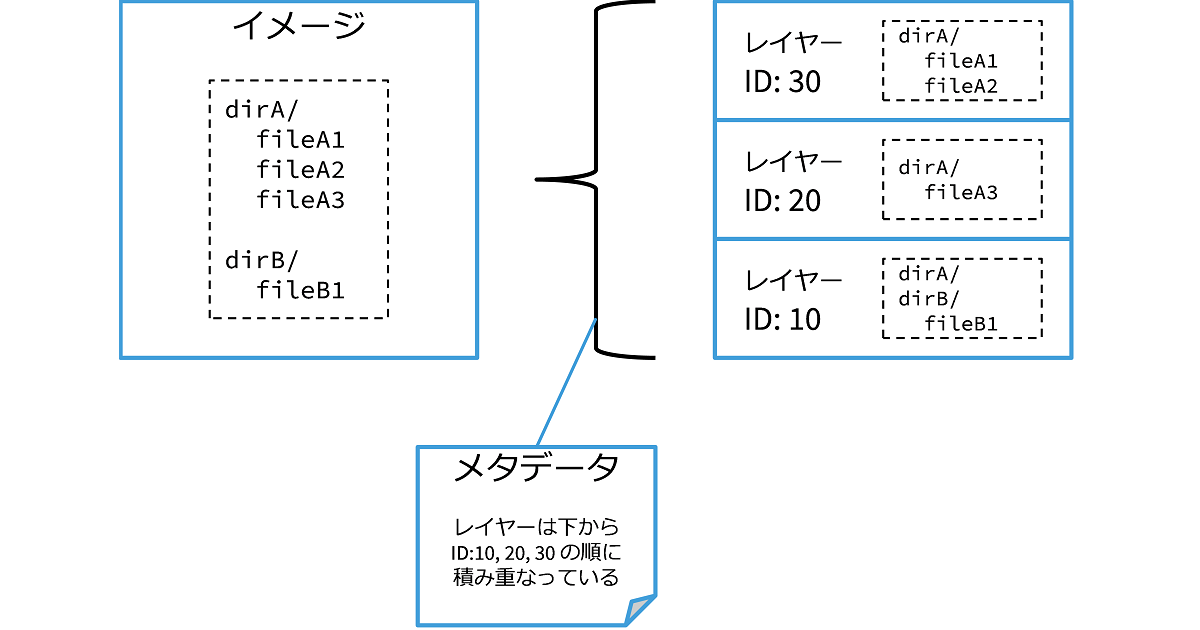
レイヤーはそれぞれ一意に識別するための ID を持っています。 この例では、一番上のレイヤーは ID: 30 を持っています。
あるレイヤーにとって、その下のレイヤーは親レイヤー (parent layer) と呼ばれます。 例えば ID: 20 のレイヤーは、ID: 30 のレイヤーの親レイヤーです。
こうしたレイヤーの ID や親子関係(積み重なる順番)といったイメージに関する情報をメタデータ (metadata)と言います。 メタデータの詳細についてはこちらやこちらを参照して頂くことにして、ここではメタデータはコマンドや API を利用して取得できるということだけ覚えておいてください。
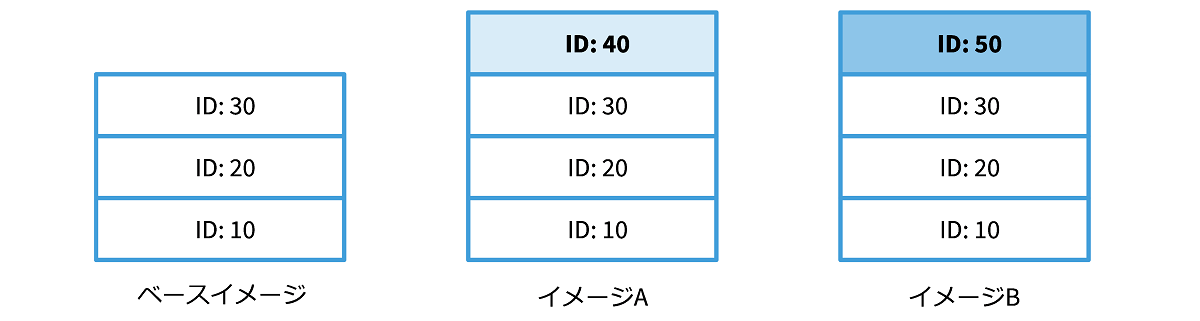
イメージを新たに作成する場合、通常は既存のイメージの上にレイヤーを積み重ねて作成します。 そうした土台になる既存のイメージのことをベースイメージ (base image) と言います。 例えば、下の図の中央のイメージAは、左側のベースイメージの上に ID: 40 のレイヤーを積み重ねて作成したイメージを表しています。 もしこのイメージAが気に入らない場合、右側のイメージBのように別のレイヤー ID: 50 を積み重ねたイメージを作ることができます。 ベースイメージを作り直す必要はありません。 このようにイメージを容易に作成できるのも、イメージがレイヤーに分かれているからこそです。
Detector はレイヤーをスキャンする
さて、冒頭で Detector は「イメージのスキャン」を行うコンポーネントですと書きましたが、実は Detector はイメージを丸ごとそのままスキャンするわけではなく、イメージを構成するレイヤーをスキャンします。
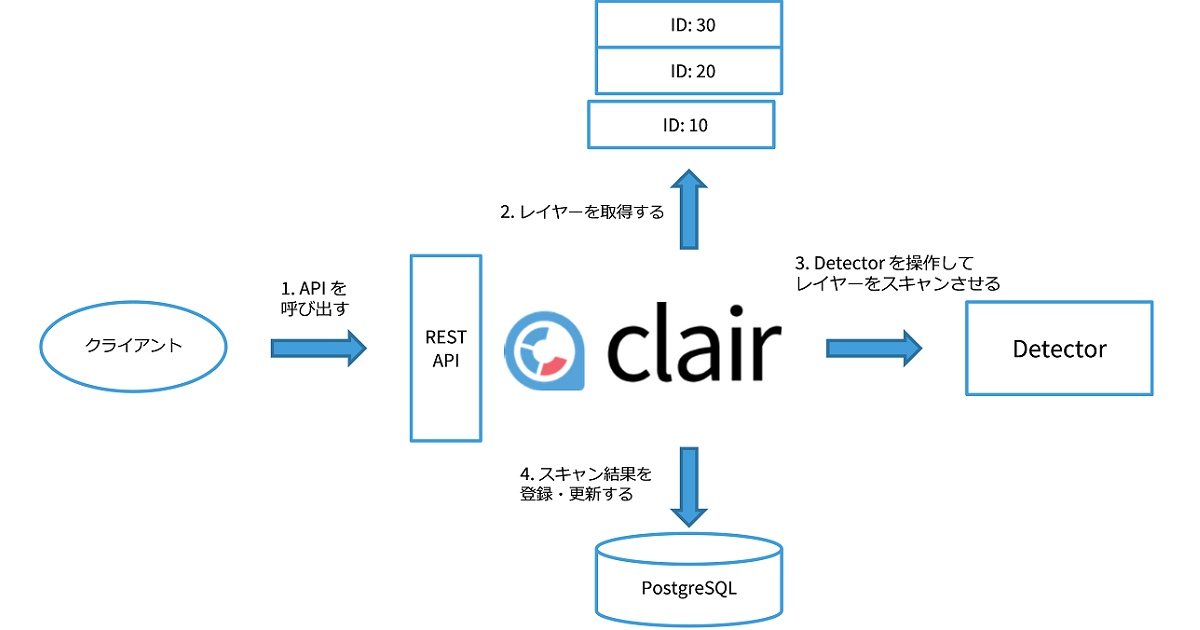
Detector にレイヤーを1つスキャンさせるためには、次の図のように API を1回呼び出す必要があります。
クライアントが API を呼び出す
まず始めにクライアントが REST API を呼び出して、Clair にレイヤーのスキャンを要求します。 API のパラメーターには、レイヤーのパスまたは URL を指定します。 パスや URL は、クライアントがイメージのメタデータから抽出しなければなりません。
Clair がレイヤーを取得する
Clair は API で指定されたパスまたは URL を基にレイヤーを取得します。
Clair が Detector を操作してレイヤーをスキャンさせる
Clair は取得したレイヤーを Detector に渡してスキャンさせます。 スキャンの詳細については後ほど説明します。
Clair がスキャン結果を登録・更新する
Clair は Detector からスキャン結果を受け取り、データベース(PostgreSQL)に登録・更新します。
イメージはレイヤーを積み重ねたものですので、イメージをスキャンするにはレイヤー1つ1つに対して API を1回1回呼び出す必要があります。 また、Detector は親レイヤーのスキャンが完了していないレイヤーはスキャンしてくれませんので、イメージの一番下のレイヤーから順番に API を呼び出す必要があります。 これらの条件をクリアするために、クライアントは予めメタデータを取得してイメージのレイヤー構成を把握しておく必要があります。
クライアントの実例が知りたいという方は、analyze-local-images や hyperclair をご覧ください。 analyze-local-images はローカルマシンの中にあるイメージをスキャンできる Clair 付属のツールです。 hyperclair はレジストリの中にあるイメージをスキャンできるツールです。
スキャンは3段階、Detector も3種類
Detector が行うスキャン処理は、以下の表のとおり3段階に分けられます。 また、各段階に対応して Detector は3種類に分けられます。
| 段階 | Detector |
|---|---|
| (1) ファイルの抽出 | DataDetector |
| (2) 名前空間の判定 | NamespaceDetector |
| (3) フィーチャーの検出 | FeaturesDetector |
Fetcher と同様に、Detector は予めいくつか Clair に組込まれています。 また、3種類の Detector それぞれにインタフェースが存在し、自作も可能となっています。
以下では、Clair v1.2.6 に基づき、3種類の Detector がそれぞれどのような処理を行うのか見ていきます。
(1) ファイルの抽出:DataDetector
DataDetector は、レイヤーからファイルを抽出し、Clair にとっての標準的な形式に変換します。 具体的には「キー:ファイルのパス、値:ファイルそのもの」という map に変換します。 このファイル構成の map は、後続の (2), (3) の処理の入力値となります。
Clair には予め以下の DataDetector が組み込まれています。
| DataDetector | イメージの形式 |
|---|---|
| DockerDataDetector | Docker |
| ACIDataDetector | ACI (rkt) |
この表の「ACI (rkt)」とは、CoreOS社が提唱しているイメージの形式です。 イメージの形式は Docker ただ1つとは限らないのです。 また Docker 自体もイメージの仕様を変更することがあります。 DataDetector のようにファイルを抽出・標準化する仕組みがあることで、イメージの形式の違いや変化を後続処理で意識しなくて済むのです。
(2) 名前空間の判定:NamespaceDetector
NamespaceDetector は、(1) で標準化されたレイヤーのファイルをスキャンして名前空間 (Namespace) を判定します。 名前空間とは、レイヤーや脆弱性情報を分類するためのもので、ここではとりあえず OS の名前及びバージョンとみなして頂いて結構です。 例えば「ubuntu:16.04」や「debian:9」のように「OS名 + “:” + バージョン」が名前空間となります。
第2回で Fetcher が Red Hat や Ubuntu 等 OS 毎のデータソースから脆弱性情報を取得していたことを思い出してください。 レイヤーの名前空間を判定することで、そのレイヤーをどの OS の脆弱性情報と照合させるのかが決まるのです。
Clair には予め以下の NamespaceDetector が組み込まれています。
| NamespaceDetector | 名前空間(OS) | スキャンするファイル |
|---|---|---|
| AptSourcesNamespaceDetector | Debian, Ubuntu | etc/apt/sources.list |
| LsbReleaseNamespaceDetector | Ubuntu | etc/lsb-release |
| OsReleaseNamespaceDetector | Debian, Ubuntu | etc/os-release, usr/lib/os-release |
| RedhatReleaseNamespaceDetector | CentOS, RedHat | etc/centos-release, redhat-release, system-release |
各 NamespaceDetector で判定できる名前空間は限られており、Clair は名前空間が判定できるまで順番に NamespaceDetector を実行します。
例として、AptSourcesNamespaceDetector の処理を見てみましょう。 スキャン対象である etc/apt/sources.list には、apt が取得するパッケージの取得元が記述されています。 Debian の Wiki によると、取得元は以下の形式で記述することになっています。
deb https://site.example.com/debian distribution component1 component2 component3
さて、AptSourcesNamespaceDetector が etc/apt/sources.list をスキャンしたところ、以下の記述が見つかったとします。
deb https://jp.archive.ubuntu.com/ubuntu/ xenial main restricted
「distribution」の位置に「xenial」という文字列が書かれているのが分かります。 どうやらこのレイヤーの OS のコードネームは「xenial」とみなしてほぼ間違いなさそうです。
この「xenial」を、以下のように Clair が予め持っている Ubuntu のコードネームの定義と対応づけます。
var UbuntuReleasesMapping = map[string]string{
"precise": "12.04",
"quantal": "12.10",
"raring": "13.04",
"trusty": "14.04",
"utopic": "14.10",
"vivid": "15.04",
"wily": "15.10",
"xenial": "16.04",
}
その結果、AptSourcesNamespaceDetector は名前空間を「ubuntu:16.04」と判定します。
(3) フィーチャーの検出 FeaturesDetector
FeaturesDetector は、(1) で標準化されたレイヤーのファイルをスキャンしてフィーチャー (Feature)を判定します。 フィーチャーとは、脆弱性情報と照合するためのキーになるもので、ここではとりあえず dpkg や rpm で管理されているパッケージの名前及びバージョンとみなして頂いて結構です。
Clair には予め以下の FeaturesDetector が組み込まれています。
| FeaturesDetector | パッケージ管理ツール | スキャンするファイル |
|---|---|---|
| DpkgFeaturesDetector | dpkg | var/lib/dpkg/status |
| RpmFeaturesDetector | rpm | var/lib/rpm/Packages |
例えば、DpkgFeaturesDetector がスキャンする var/lib/dpkg/status の中身は以下のようになっています。
Package: python-apt-common
Status: install ok installed
Priority: optional
Section: python
Installed-Size: 244
Maintainer: Ubuntu Developers <ubuntu-devel-discuss@lists.ubuntu.com>
Architecture: all
Source: python-apt
Version: 1.1.0~beta1build1
Replaces: python-apt (<< 0.7.98+nmu1)
Depends: python | python3
Breaks: python-apt (<< 0.7.98+nmu1)
Enhances: python-apt, python3-apt
Description: Python interface to libapt-pkg (locales)
The apt_pkg Python interface will provide full access to the internal
libapt-pkg structures allowing Python programs to easily perform a
variety of functions.
.
This package contains locales.
Original-Maintainer: APT Development Team <deity@lists.debian.org>
これらの「項目名: 値」は、dpkg のパッケージ情報を記述したもので、その意味は Debian Policy Manual というドキュメントに定義されています。 その定義に基づいて、DpkgFeaturesDetector は「Package」「Source」「Version」等の項目からパッケージ名とバージョンを抽出し、フィーチャーを生成します。 生成されたフィーチャーは Clair 本体に返され、先述の「4. Clair がスキャン結果を登録・更新する」でデータベースに登録されます。
以上のように NamespaceDetector も FeaturesDetector も、決して難解な理論に基づいて実装されたものではなく、OS やパッケージ管理ツールの仕様・知識を地道に実装に落とし込んだものとなっています。 もしもうまくスキャンできないレイヤーがあった場合、それは Detector が前提としている仕様・知識でカバーできないレイヤーです。 その場合はインタフェースに沿って、新たな仕様・知識に基づく Detector を自作すればよいでしょう。
まとめ
今回は、イメージをスキャンする Detector コンポーネントについて解説しました。 スキャンの結果として、イメージの各レイヤーが含んでいる OS(名前空間)のパッケージ(フィーチャー)が検出されることがお分かり頂けたかと思います。 そのスキャン結果と、前回解説した Fetcher が取得する脆弱性情報(どの OS のどのパッケージにどのような脆弱性が存在するか)を組合せることで、Clair はコンテナ・イメージの脆弱性を検出することができるのです。
さて、本連載は今回で一旦終了しますが、実は連載と同時期に開発されていた Clair の次期バージョン v2 では大幅なリファクタリングが行われており、コンポーネントの名前が以下のように変更される見込みです。
- Fetcher → Updater
- DataDetector → Extractor
- NamespaceDetector → Detector
- FeaturesDetector → Lister
本連載で解説した基本的な仕組みが大きく変わることはなさそうですが、名前は適宜読み替えて頂けますようお願いします。 また機会があれば、こうした Clair の最新動向についてもお伝えできればと思います。