
PrometheusとGrafanaでオブザーバビリティに入門しよう
Prometheus / Grafana Loki / Grafana Tempoを活用して分散システムにおけるメトリクスやログ、トレースの調査・分析を体験してみます。
1. はじめに
皆さんはシステム運用をどのように行っていますでしょうか。筆者は数年前まではモノリシックなシステムの運用が多かったこともあり、CPUやメモリなどの使用率に閾値を設けたり、エラーログを検出することでメールを発報するような運用監視を長年続けていました。しかし近年はクラウドの利用が当たり前になりコンテナやサーバレスでのシステム構築が増えたことで、システム全体の構成が複雑化してきています。複雑化されたシステムは異常が見つかっても複数のアプリケーションにわたって調査する必要が出てくるため、単純なCPUやメモリ、エラーログ等の監視だけでは原因の特定が困難になってきました。そこで今回は複雑な分散システム全体を観測する手法として生まれたオブザーバビリティについて入門してみたいと思います。
なお、本記事内のコードは抜粋となります。コード全体についてはGithubを参照してください。
2. 用語
オブザーバビリティを理解する上で必要となる主要な用語について簡単に解説します。
2.1 オブザーバビリティ
まずはオブザーバビリティそのものです。オブザーバビリティ(observability)とは、システムやアプリケーションの内部状態や振る舞いを観察可能な状態にすることを指します。具体的には、ログ、メトリクス、トレースなどのデータ(テレメトリーデータ)を収集し、それぞれを相互に参照しながら分析することで、システム全体がどのように機能しているかを把握します。
テレメトリーデータはSDKやエージェントを用いてアプリケーションごとに出力設定を行うほか、サービスメッシュなどを用いて横断的に収集することもあります。(この収集のための実装を計装といいます)
2.2 OpenTelemetry
OpenTelemetryは、テレメトリーデータを収集するための標準仕様およびそれを実装したAPIやSDKになります。Cloud Native Computing Foundation(CNCF)のIncubating Projectとなっており、ベンダーに依存しない仕様として標準化されています。OpenTelemetryは分散トレーシングから始まり、現在はメトリクスやログ収集を含めた標準化作業が進められています。ただし、2023年5月現時点ではAPI/SDK/ProtocolすべてがStableとなっているのはトレーシングのみとなっており、メトリクスはSDKがmixed、ロギングはAPI/SDKがexperimentalとなっています。
2.3 トレースとスパン
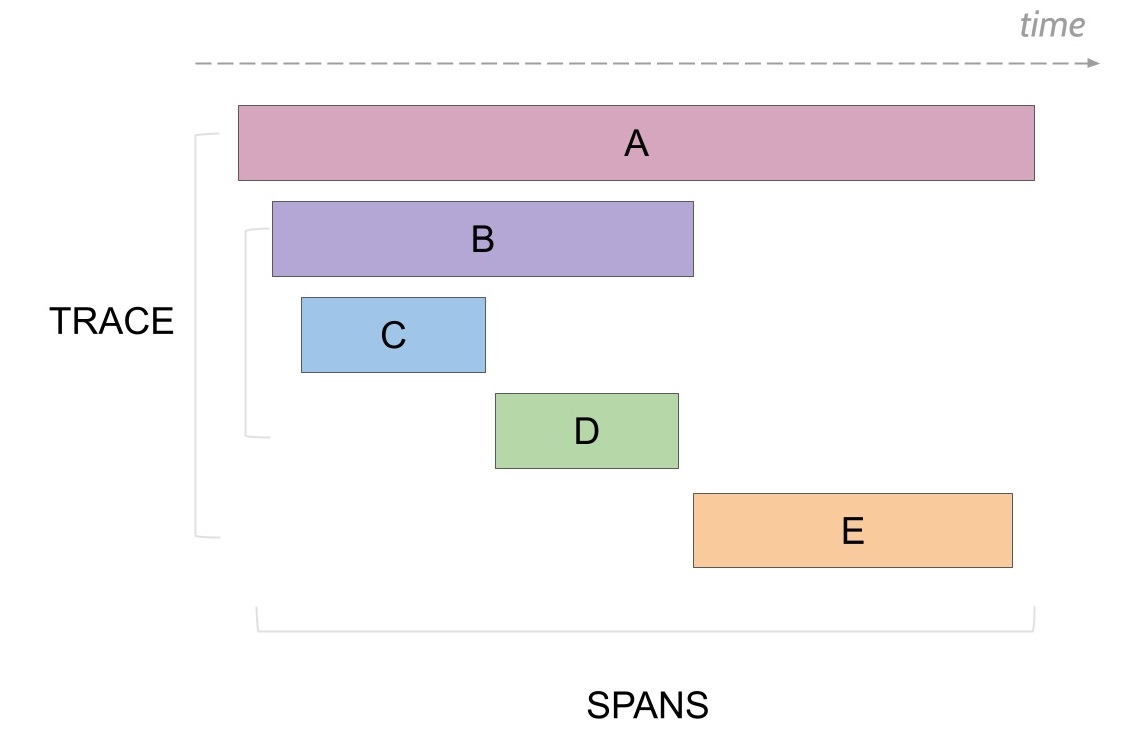
トレースを管理する単位として、トレースそのものとトレース内の処理を識別するスパンがあります。 トレースはリクエストを受けてからレスポンスを返すまでの一連の処理のかたまりとなり、識別するためのトレースIDは通常リクエストごとにユニークな値となります。スパンはトレース内の個別の処理を表しており、トレース内のスパンIDは同じトレース内でユニークとなります。
図示すると以下のようになります。
2.4 Exemplar
Exemplarはそのまま訳すと「規範」、「見本」、「例」のようになります。GrafanaのExemplarはレスポンスタイムのバケット(指定した範囲内の集計値)メトリクスのうち代表1つ(同じ集計値となるものの中から1つを選択)にトレースIDを付与することで、メトリクスからトレースへとつなげます。Exemplarは2023年5月現在ではデータソースとしてPrometheusをサポートしています。
3. アーキテクチャ
3.1 全体構成
オブザーバビリティを実現するためのアーキテクチャを見ていきましょう。 今回はオープンソースのPrometheus / Grafana Loki / Grafana Tempoを使って、メトリクス、ログ、トレースを収集します。収集したデータはGrafanaで一元的に可視化することで、メトリクス、ログ、トレースの情報を互いに参照できるようにします。 また、サンプルアプリケーションはSpringBoot3で用意します。
全体構成を図示すると以下のようになります。
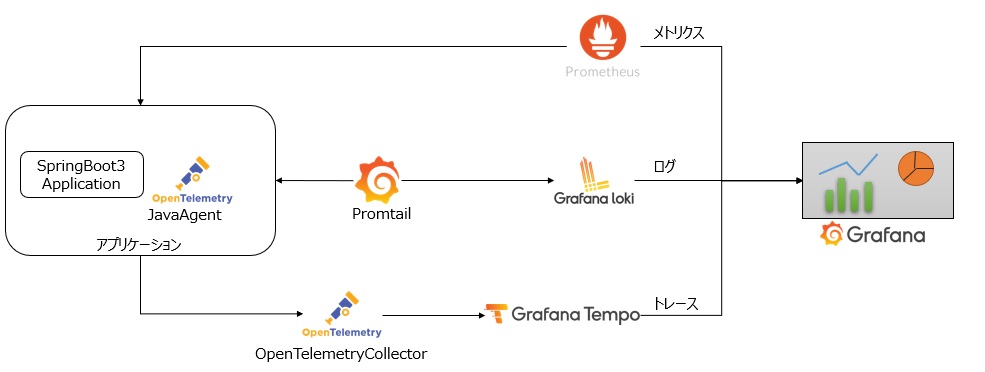
メトリクス・ログ・トレースの収集方法についてもう少し見ていきます。
3.2 メトリクスの収集
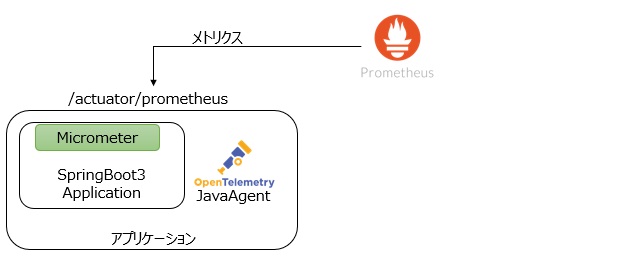
メトリクスはオープンソースのモニタリングツールであるPrometheusを使用して収集します。PrometheusはCPUやメモリのようなノードのメトリクスやコンテナごとのメトリクス、リクエストやアプリケーション内の処理時間等様々なメトリクスを時系列データベースで管理し、専用のクエリ言語であるPromQLを使用して任意のメトリクスを表示することができます。
アプリケーション(SpringBoot)はSpringBootActuatorおよびMicrometerを使うことでPrometheusフォーマットのメトリクスを公開することができるので、この公開されたエンドポイントをPrometheus側からスクレイピングし時系列データベースに格納します。この時トレースIDやスパンIDも含めておくことでトレース情報との紐づけが可能になります。
3.3 ログの収集
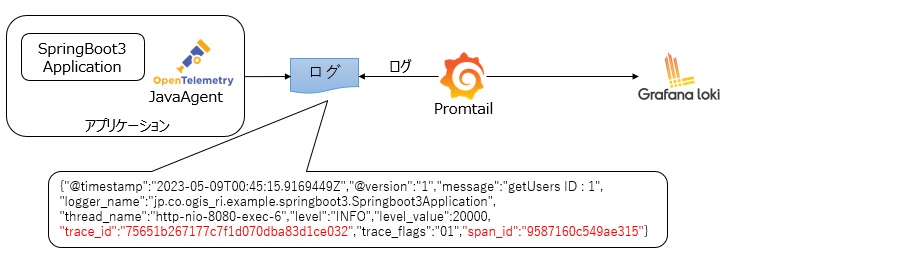
ログはオープンソースのログストレージエンジンであるGrafana Lokiへ収集します。Grafana Lokiはラベル付けされたログエントリを格納し、Prometheusと同じくPromQLを用いて任意のログを表示することが可能です。
ログは送信エージェントであるPromtailを使用してノードに出力されたログをGrafana Lokiへ送信します。このログの内容にもトレースIDやスパンIDも出力しておくことでトレース情報との紐づけを可能にします。なお、Grafanaで構造化ログを参照できるようにするため、アプリケーションではログ出力の際にJSONフォーマットにしておきます。
3.4 トレースの収集
トレースはGrafana Lokiと同じくGrafanaプロダクトの1つであるGrafana Tempoへ収集します。Grafana Tempoはトレース情報をトレースID、スパンIDを使って管理する分散トレーシングシステムになります。
Grafana TempoはOpenTelemetryをサポートしているので、JavaアプリケーションではOpenTelemetryJavaAgentを使用してOTLP(OpenTelemetryProtocol)仕様のデータをOpenTelemetry Collectorへ送信します。OpenTelemetry Collectorは(必要があれば)データを加工した後、Grafana Tempoへ連携します。
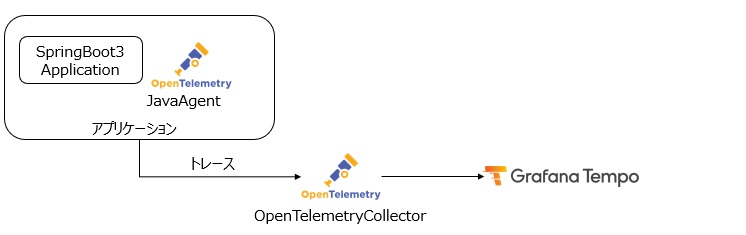
3.5 サンプルアプリケーションの構成
サンプルアプリケーションはサービス間がつながって見えることを確認するために2つのアプリケーションを用意します。 動作はいたってシンプルで、springboot3-frontはspringboot3-backへの中継をするだけ、springboot3-backはパスパラメータのidと固定値の名前(hoge)をJSON形式で返すアプリケーションになります。ただし、この後のユースケースで検証しやすいように、id=10の時は5秒遅延、id=99の時はシステムエラーが発生するようにid固定で処理を埋め込んでいます。

4. 環境構築
3章で記載した構成をローカル環境(Windows WSL2)上のMinikubeに構築していきます。
なお、本構築手順はGitHubにて公開しているコードの利用を前提として記載していますので、コードの詳細はGitHubを参照してください。
4.1 事前準備
以下のものは事前に導入し、Minikubeを起動しておいてください。
- Git(サンプルコードをcloneする場合)
- Docker
- kubectl
- Minikube
以下のコマンドでノードの状態(Ready)が確認できれば問題ありません。
kubectl get nodes NAME STATUS ROLES AGE VERSION minikube Ready control-plane 71d v1.25.2
また、今回のサンプルはArgoCDのApplicationマニフェストで用意していますので、MinikubeにArgoCD(v2.5以上必須)を導入しておきます。
./argocd/install.sh
4.2 Prometheus / Grafanaの導入
まずはkube-prometheus-stackを使用して、Prometheus、Grafanaを導入します。(AlertManagerも導入されますが、今回は使用しません)
kubectl apply -f prometheus/application.yaml
スクレイピング対象の設定
導入時のHELMパラメータでアプリケーションの/actuator/prometheusエンドポイントをスクレイピングするように設定します。サンプルアプリケーション名を変更する場合や、別のアプリケーションもスクレイピングする場合等は以下の設定を変更してください。
additionalScrapeConfigs:
- job_name: otel
metrics_path: "/actuator/prometheus"
static_configs:
- targets: ['springboot3-front.default.svc.cluster.local:8080','springboot3-back.default.svc.cluster.local:8080']
Exemplarの有効化
Prometheus側でexemplarも保存するようにexemplar-storageを有効にしています。
enableFeatures:
- exemplar-storage
(補足)ServerSideApply
ArgoCD v2.5よりServerSideApplyがサポートされているので「ServerSideApply=true」を指定します。通常のApply(ClientSideApply)だとkube-prometheus-stackはmetadata.annotationsのサイズオーバーでエラーとなるので注意が必要です。
syncPolicy:
automated:
prune: true
syncOptions:
- CreateNamespace=true
- ServerSideApply=true
4.3 Grafana Lokiの導入
GrafanaのHELMチャートを使用してGrafana Lokiを導入します。
kubectl apply -f loki/application.yaml
動作モード設定
Minikubeにデプロイするので、シンプルなsingleBinalyモードに設定します。また今回は認証も外しておきます。
loki:
auth_enabled: false
commonConfig:
replication_factor: 1
storage:
type: 'filesystem'
singleBinary:
replicas: 1
4.4 Promtailの導入
GrafanaのHELMチャートを使用してPromtailを導入します。
kubectl apply -f promtail/application.yaml
Grafana Lokiへの送信設定
導入時のHELMパラメータで送信先となるGrafana Lokiのエンドポイントを指定します。なお、Promtailは各ノードごとにDaemonSetとして導入され、ノードの標準出力内容を収集するので収集元については特に設定は必要ありません。
config:
clients:
- url: http://loki:3100/loki/api/v1/push
4.5 Grafana Tempoの導入
kubectl apply -f tempo/application.yaml
導入パラメータ
OpenTelemetry Collectorからのtrace情報を受け取れるようにOpenTelemetryProtocolの受信を許可しておきます。
traces:
otlp:
http:
enabled: true
grpc:
enabled: true
distributor:
receivers:
otlp:
protocols:
grpc:
http:
4.6 OpenTelemetry Collectorの導入
OpenTelemetry Collectorの利用にはCertManagerが必要になるため、事前に導入しておきます。その後オペレータを使ってOpenTelemetry Collectorを導入します。
./certmanager/install.sh kubectl apply -f otel/operator.yaml kubectl apply -f otel/collector.yaml
受信及び送信設定
トレース情報をアプリケーションから受けとって、Grafana Tempoに送信するための設定を行います。今回は送信元の制限なしで受信し、Grafana TempoのHTTPエンドポイントに送信するように設定しています。送信前にデータ加工を挟む場合はprocessorで処理を行いますが、今回は何もしないため空欄となります。
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
exporters:
otlphttp:
endpoint: http://tempo-distributor:4318
service:
pipelines:
traces:
receivers: [otlp]
processors: []
exporters: [otlphttp]
※ Grafana Tempoのエンドポイントについては5.1 Grafana Tempoのアーキテクチャ図を参照してください
4.7 サンプルアプリケーションの導入
サンプルアプリケーションをMinikubeに導入します。本手順ではフロント(springboot3-front)について手順を記載しますが、バック(springboot3-back)もfrontをbackに読み替えるだけで導入できます。
eval $(minikube docker-env) cd examples/front docker build . -t springboot3-front:latest kubectl apply -f manifests/
(1) メトリクスの出力
メトリクスを出力するためspring-boot-starter-actuatorおよびmicrometerを導入します。Gradle(もしくはMaven)でライブラリを導入すれば基本的なメトリクスは/actuator/prometheusエンドポイントで公開可能になります。また、メトリクスにトレースID、スパンIDを含める実装を行うため、opentelemetry-apiもあわせて導入しておきます。
dependencies {
...
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'io.micrometer:micrometer-registry-prometheus:1.10.6'
implementation 'io.opentelemetry:opentelemetry-api:1.25.0'
...
}
標準ではhealthエンドポイントのみ公開されるのでprometheusのエンドポイントを公開するように設定ファイルに追記します。また、URIごとのレイテンシをモニタリングするためhttp.server.requestsを有効化しておきます。
application.properties
management.endpoints.web.exposure.include=health,prometheus management.metrics.distribution.percentiles-histogram.http.server.requests=true management.metrics.distribution.minimum-expected-value.http.server.requests=5ms management.metrics.distribution.maximum-expected-value.http.server.requests=6000ms
(2) Exemplarの出力
PrometheusのメトリクスにトレースIDを埋め込むためのConfigurationを作成します。
PrometheusConfiguration.java
@Configuration
public class PrometheusConfiguration {
@Bean
public PrometheusMeterRegistry prometheusMeterRegistryWithExemplar
(PrometheusConfig prometheusConfig, CollectorRegistry collectorRegistry,
Clock clock) {
return new PrometheusMeterRegistry(prometheusConfig, collectorRegistry,
clock, new DefaultExemplarSampler(new OpenTelemetryAgentSpanContextSupplier() {
@Override
public String getTraceId() {
if (!Span.current().getSpanContext().isSampled()) {
return null;
}
return super.getTraceId();
}
})
);
}
}
(3) ログの構造化
logstash-logback-encoderを導入し、ログをJSONフォーマットで出力するようにしておきます。なお、trace_idやspan_idは次のopentelemetry-javaagentの導入をしておけば自動で付与されるので、ここでは特に設定は必要ありません。
build.gradle
dependencies {
...
implementation 'net.logstash.logback:logstash-logback-encoder:7.3'
...
}
logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
</root>
</configuration>
(4) トレース情報の出力
トレース情報はJava起動時に-javaagentでOpenTelemetryJavaAgentのJarファイルを指定すれば導入できますので、DockerfileのENTRYPOINTに設定を組み込みます。
ENTRYPOINT ["java", "-javaagent:/app/opentelemetry-javaagent.jar", "-jar","/app/spring-boot-application.jar"]
また、トレース情報の送信先を指定するためDeploymentの環境変数でOpenTelemetry Collectorのエンドポイントを指定します。なお、opentelemetry-javaagentではデフォルトでメトリクスデータも出力するようになっていますが、今回メトリクスはPrometheus側からスクレイピングするため明示的にnoneに設定しておきます。
manifests/deployment.yaml
env:
- name: OTEL_EXPORTER_OTLP_TRACES_ENDPOINT
value: "http://example-collector.monitoring.svc.cluster.local:4317"
- name: OTEL_TRACES_EXPORTER
value: otlp
- name: OTEL_METRICS_EXPORTER
value: none # 明示的にnoneにしておかないとメトリクスの送信エラーのログが出力される
- name: OTEL_SERVICE_NAME # Tempo連携時の名前
value: "springboot3-front"
(5) 補足:プロキシ設定
プロキシサーバーを経由して接続する場合、examples/front/envにgradle.propertiesを作成し、以下の設定を追加してください。
systemProp.http.proxyHost=<プロキシホスト名> systemProp.http.proxyPort=<ポート番号> systemProp.http.proxyUser=<ユーザーID(認証ありの場合)> systemProp.http.proxyPassword=<パスワード(認証ありの場合)> systemProp.https.proxyHost=<プロキシホスト名> systemProp.https.proxyPort=<ポート番号> systemProp.https.proxyUser=<ユーザーID(認証ありの場合)> systemProp.https.proxyPassword=<パスワード(認証ありの場合)> systemProp.jdk.http.auth.tunneling.disabledSchemes=""
なお、env配下のファイルは.gitignoreにて除外されているのでコミットされません。ローカルでのみ利用する環境変数になります。
4.8 導入後の動作確認
(1) ブラウザから簡単な動作確認
アプリケーションの導入ができたら動作確認してみましょう。ポートフォワードを設定してブラウザでアプリケーションのエンドポイントやメトリクスのエンドポイントへアクセスしてみます。
ポートフォワード
kubectl port-forward svc/springboot3-front 8080:8080
ブラウザでアクセス
http://localhost:8080/users/1
{"name":"hoge","id":1}
メトリクスエンドポイントへのアクセス
http://localhost:8080/actuator/prometheus
# HELP jvm_memory_max_bytes The maximum amount of memory in bytes that can be used for memory management
# TYPE jvm_memory_max_bytes gauge
jvm_memory_max_bytes{area="nonheap",id="CodeHeap 'profiled nmethods'",} 1.22908672E8
jvm_memory_max_bytes{area="heap",id="G1 Survivor Space",} -1.0
...
http_server_requests_active_seconds_bucket{exception="none",method="GET",outcome="SUCCESS",status="200",uri="UNKNOWN",le="120.0",} 130.0
http_server_requests_active_seconds_bucket{exception="none",method="GET",outcome="SUCCESS",status="200",uri="UNKNOWN",le="137.438953471",} 130.0
http_server_requests_active_seconds_bucket{exception="none",method="GET",outcome="SUCCESS",status="200",uri="UNKNOWN",le="160.345445716",} 130.0
...
上記のように出力されていればサンプルアプリケーションはひとまず動作しています。それではメトリクスやログをもう少し見ていきます。
(2) メトリクス
先ほどブラウザから見たときはtrace_idやspan_idが含まれていませんでした。(ブラウザ上でtrace_idをサイト内検索しても引っかからない)これは、trace_idやspan_idはContent-Typeが「application/openmetrics-text;」の場合に出力されるためです。
curlを使って/actuator/prometheusにアクセスしてメトリクスを確認します。この時Content-Typeに「application/openmetrics-text;」を指定します。
curl -H 'Accept: application/openmetrics-text; version=1.0.0; charset=utf-8' http://localhost:8080/actuator/prometheus | grep trace_id
http_server_requests_seconds_bucket{error="none",exception="none",method="GET",outcome="SUCCESS",status="200",uri="/actuator/prometheus",le="0.005"} 368.0 # {span_id="f01103fc9322e30b",trace_id="08e53cb41e65746ea6bc24d37d8fca90"} 0.00191 1682496689.652
http_server_requests_seconds_bucket{error="none",exception="none",method="GET",outcome="SUCCESS",status="200",uri="/actuator/prometheus",le="0.005592405"} 404.0 # {span_id="49a4ad47bb2f01d0",trace_id="a2e9506bccd4a11cc3e434c66d4cdf8d"} 0.0053064 1682496149.656
http_server_requests_seconds_bucket{error="none",exception="none",method="GET",outcome="SUCCESS",status="200",uri="/actuator/prometheus",le="0.006990506"} 438.0 # {span_id="63aa340bdbf34bac",trace_id="4e2df46b2b47af8fa2f841d97d807013"} 0.0066758 1682495999.657
http_server_requests_seconds_bucket{error="none",exception="none",method="GET",outcome="SUCCESS",status="200",uri="/actuator/prometheus",le="0.008388607"} 447.0 # {span_id="965f808e4c073825",trace_id="a0d94a2e0e315eb39772d5579b427141"} 0.0070605 1682495549.658
(3) ログ
アプリケーションPodのログを参照してみましょう。trace_id、trace_flags、span_idが自動で付与されているのがわかると思います。
kubectl get po # アプリケーションのPod名を確認
kubectl logs springboot3-front-xxxxxxxx-xxxxx # xxx部分は環境ごとに異なります
{"@timestamp":"2023-05-09T00:44:57.7184671Z","@version":"1","message":"Initializing Servlet 'dispatcherServlet'","logger_name":"org.springframework.web.servlet.DispatcherServlet","thread_name":"http-nio-8080-exec-2","level":"INFO","level_value":20000,"trace_id":"d1338d600bec0f861a5f158a2ecaf952","trace_flags":"01","span_id":"9fc284ef00b1101a"}
{"@timestamp":"2023-05-09T00:44:57.7197092Z","@version":"1","message":"Completed initialization in 1 ms","logger_name":"org.springframework.web.servlet.DispatcherServlet","thread_name":"http-nio-8080-exec-2","level":"INFO","level_value":20000,"trace_id":"d1338d600bec0f861a5f158a2ecaf952","trace_flags":"01","span_id":"9fc284ef00b1101a"}
{"@timestamp":"2023-05-09T00:45:15.9169449Z","@version":"1","message":"getUsers ID : 1","logger_name":"jp.co.ogis_ri.example.springboot3.Springboot3Application","thread_name":"http-nio-8080-exec-6","level":"INFO","level_value":20000,"trace_id":"75651b267177c7f1d070dba83d1ce032","trace_flags":"01","span_id":"9587160c549ae315"}
メトリクス、ログとも出力内容にトレース情報が付与されていることが確認できました。これで各出力内容がtrace_id、span_idによって紐づくようになったので、相互に参照することができます。
5. Grafanaの設定
必要なエコシステムやサンプルアプリケーションの導入まで完了したので、Grafanaで可視化するために各データソースを設定していきます。
5.1 Grafanaへ接続
ポートフォワード
kubectl port-forward svc/kube-prometheus-stack-grafana -n monitoring 18080:80
ブラウザでアクセス
http://localhost:18080/ ID : admin PW : prom-operator
※PWは初期パスワードのため、適宜変更してください
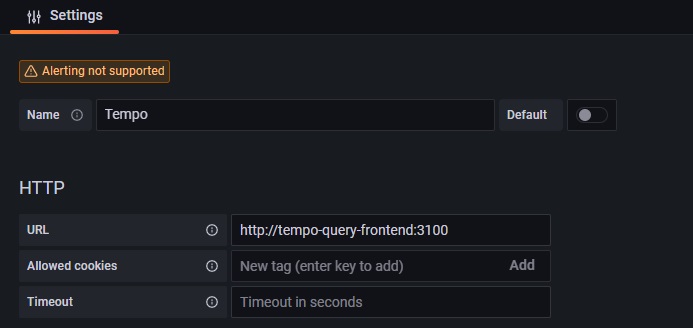
5.1 Grafana Tempoのデータソース設定
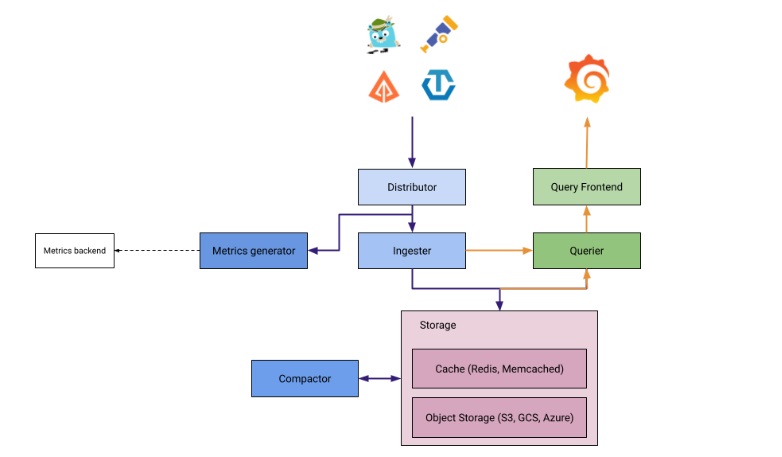
GrafanaからGrafana Tempoにクエリを投げるための設定を行います。エンドポイントはアーキテクチャ図にあるQuery Frontendのサービスになります。
GrafanaのConfigurationから新規データソースでTempoを選択し、エンドポイントの設定を行います。
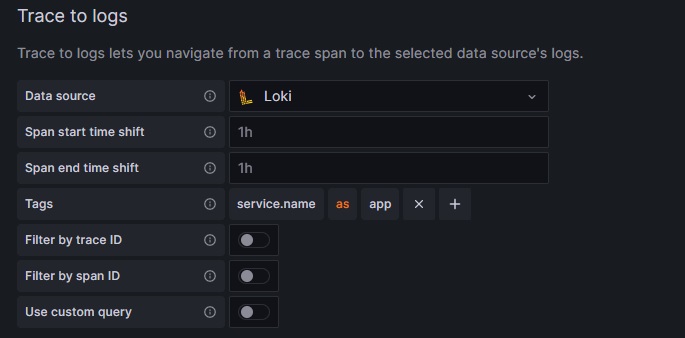
また、トレース情報からログへ連携するための設定を行います。
- Data source : Loki
- Tags : service.name = app
※ Tagsを指定することで、Grafana Lokiへ遷移した際にapp=“アプリケーションのマニフェストで指定したOTEL_SERVICE_NAMEの値"でフィルタリングできます
5.2 Grafana Lokiのデータソース設定
GrafanaからGrafana Lokiにクエリを投げるための設定を行います。
ログに出力されたTraceIDからTempoへ連携するためのリンクを作成します。
本例ではTraceID項目にtrace_id項目の値をセットしています。Queryには${__value.raw}を指定することで対象データの情報でリンクを生成します。
- Name : TraceID
- Regex : "trace_id”:“(\w+)”
- Query : ${__value.raw}
- URL Label : Tempo
- Internal link : ON(Tempo)

ログを参照すると、下図のようにリンクが付与されます。

5.3 Prometheusのデータソース設定
最後にPrometheusの設定です。Prometheusはデフォルト設定がありますがデフォルトはUIから変更ができないため、今回は別にもう一つ作成してしまいます。
- URL : http://kube-prometheus-stack-prometheus:9090/
- Default : ON
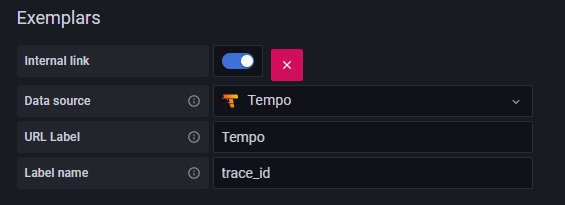
Exemplarのtrace_idからGrafana Tempoへリンクするための設定を行います。
- Internal link : ON
- Data source : Tempo
- URL Label : Tempo
- Label name : trace_id
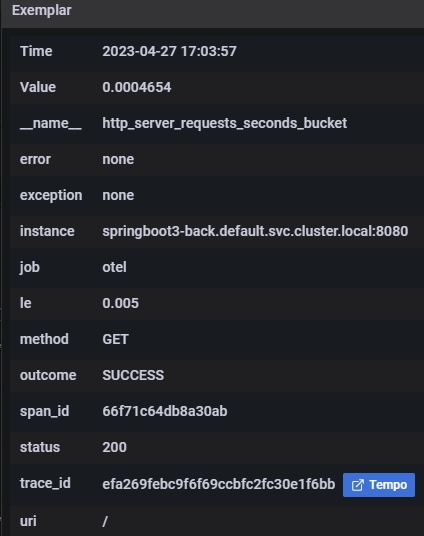
PrometheusでExemplarを参照すると、下図のようにリンクが付与され、クリックするとGrafana Tempoの画面に遷移します。
6. オブザーバビリティを体験する
Grafanaで可視化する準備が整いましたので、実際にオブザーバビリティを体験していきたいと思います。今回はメトリクスの異常値から原因を探る手順と、エラーログから原因を探る手順の2つを試してみます。
6.1 メトリクスの異常値から原因を探る
1つ目はメトリクスの異常値(遅延)から原因を特定するための手順です。分散アプリケーションではレスポンスが遅延しても、フロントアプリケーションではなくバックエンドサービスのどこかで処理遅延が発生しているケースが多いと思います。メトリクスの異常値からトレースを探ることで遅延個所を特定してみましょう。
まずは異常値を作成するためサンプルアプリケーションのエンドポイントに何度かアクセスしておきます。/users/1や/users/2などに何度かアクセスし、その中に/users/10へのリクエストも含めておきます。(5秒遅延するリクエスト)
GrafanaのExploreから新規に作成したPrometheusデータソースを開き、HTTPリクエストのパフォーマンス値(パーセンタイル)を指すhttp_server_requests_seconds_bucketを参照します。
グラフが表示されたら、OptionsのExemplarsを有効にしてExemplarを表示します。
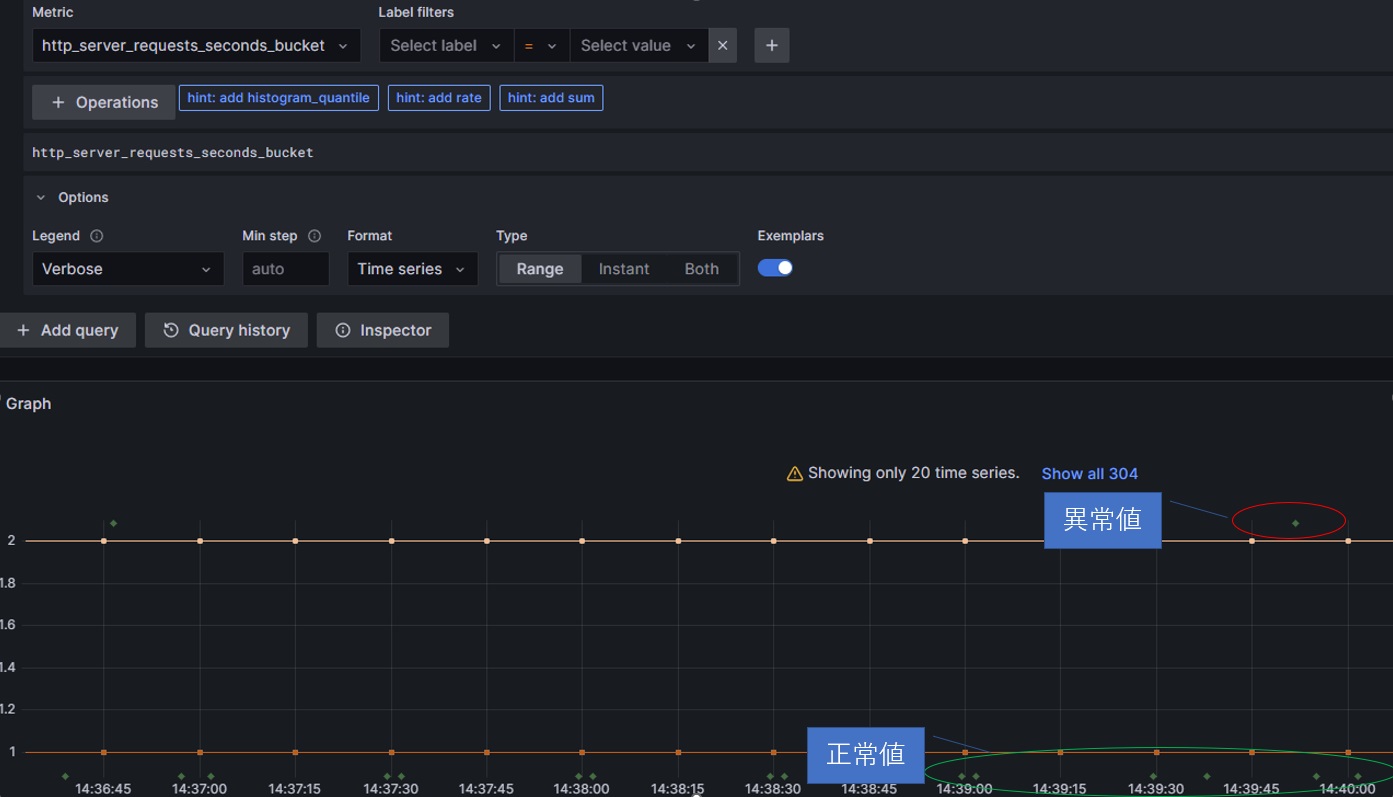
※ グラフのスケールによっては、正常値と異常値がもっと近いケースもあります。グラフから判断できないときはExemplarの内容を確認してValueが5.xxxになっているサンプリングデータを選択してください。
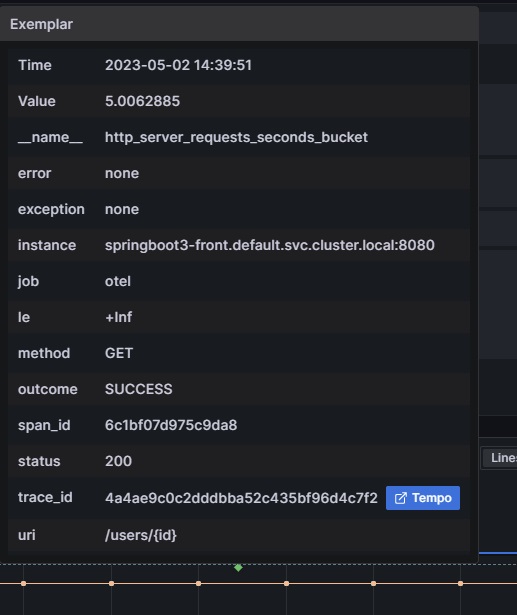
グラフ上のポイントにマウスカーソルをあわせることでExemplarの内容が表示できるので、そのtrace_idからGrafana Tempoへ遷移してトレース情報を確認します。
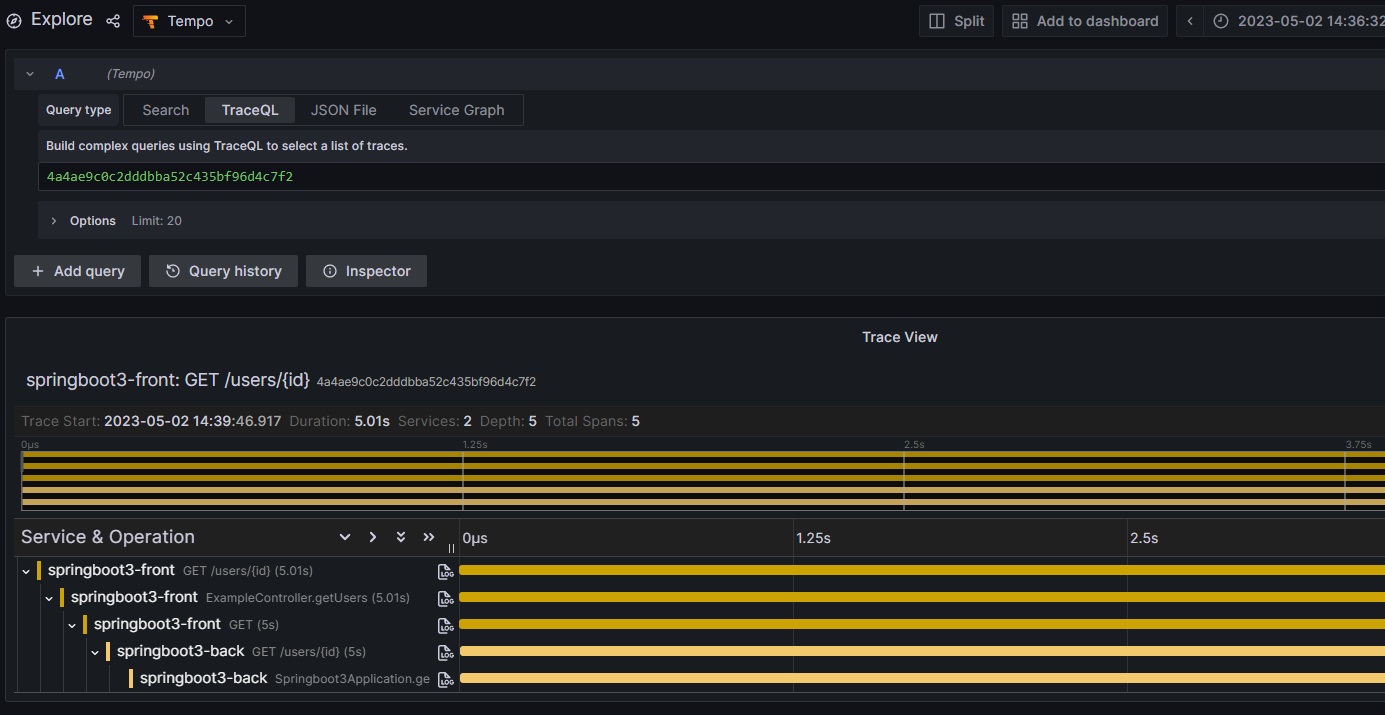
Grafana Tempoを参照すると、該当リクエストがどのサービスを経由してリクエストを処理しているかがわかります。今回はspringboot3-backのgetUsersに5秒遅延を仕込んでいるため、一番下のスパンで時間がかかっており、呼び出し元がその影響で遅延していることがわかります。
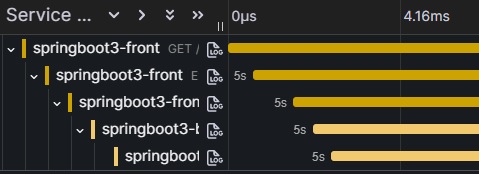
なお、全体の処理時間に対して遅延時間が長いため全部並列に動いているように見えますが、時間を絞るとちゃんと順番に呼び出されています。
遅延の原因となっているspringboot3-backのログマークをクリックしてGrafana Lokiへ遷移してログを確認します。
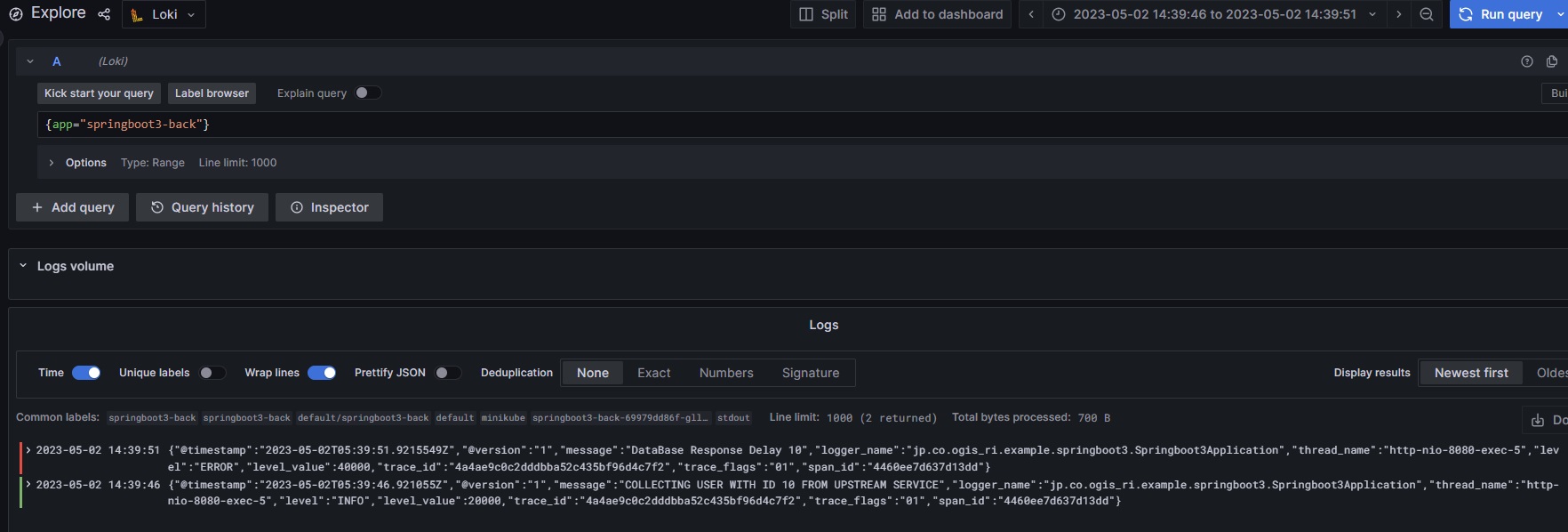
ログを拡大

アプリケーションにあらかじめ仕込んでおいた遅延ログが出力されていることが確認できました。
このようにリクエストのメトリクス情報からトレース情報→ログ情報と辿っていき、原因を特定していきます。
6.2 エラーログから関連するサービスのログを調査する
2つ目はエラーログから原因を追究する手順になります。複数のサービス間でリクエストのやり取りがあると、エラーが発生しても該当サービスのログだけではなく、前後のサービスなどの調査も行いたいケースがあると思います。これまではログに含まれるキーなどを使ってログ検索時に絞り込んで調査を行うケースなどがあったと思いますが、トレース情報と連動することで簡単に関連ログを辿ってみたいと思います。
こちらもまずはブラウザを開き、サンプルアプリケーションの/users/99エンドポイントにアクセスしておきます。(Internal Server Errorになります)
GrafanaのExploreでLokiを開き、ラベルにapp=springboot3-frontを指定してフロントアプリケーションのエラーを検出します。(左が赤くなっているログがエラー)
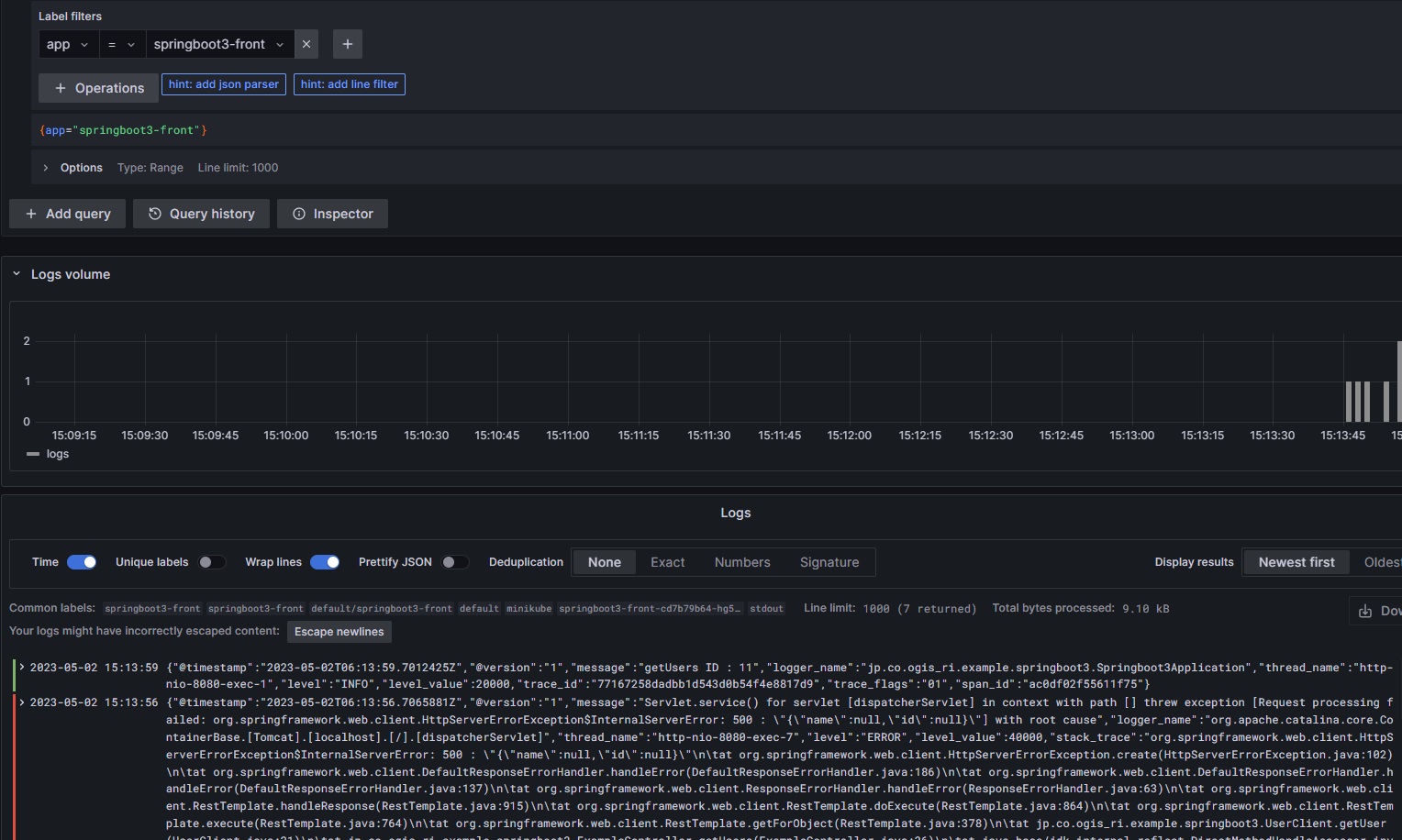
エラーログの内容を確認するとTraceIDが出力されているので、TraceIDからGrafana Tempoへ遷移します。
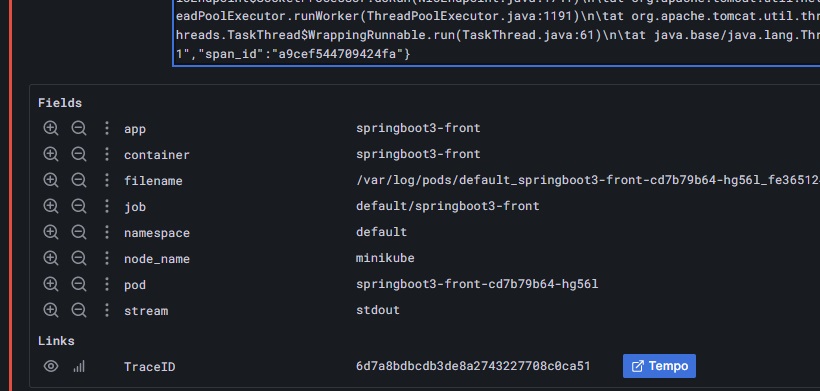
該当IDのトレースを確認するとspringboot3-backでもエラーが発生していることがわかります。
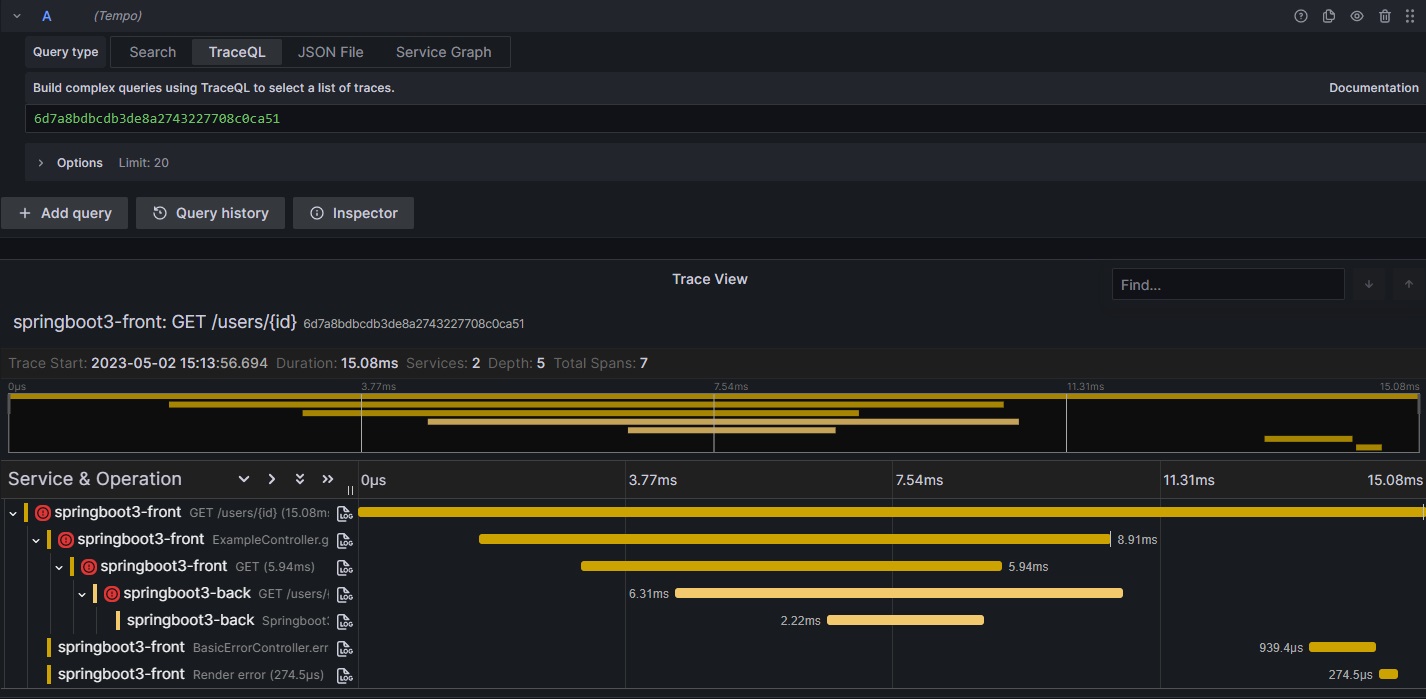
springboot3-backのログを確認し、エラーログを確認します。
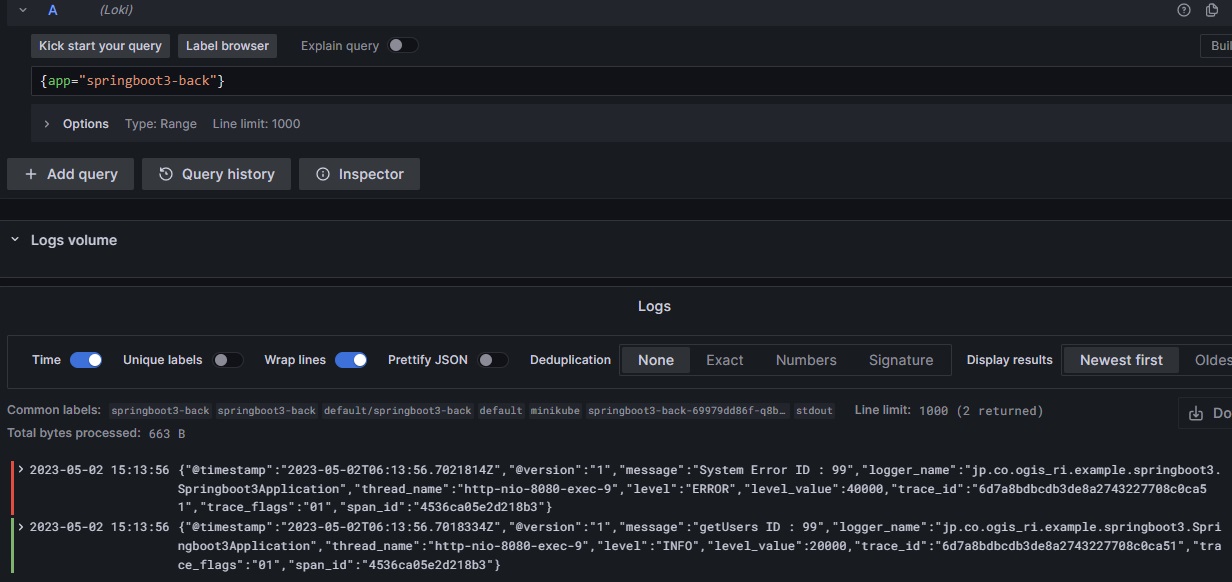
このようにエラーログから同一トレース(同一リクエスト)のログを辿ることで、関連するサービスを含めて調査を行い原因を特定していきます。
7. おわりに
今回はオブザーバビリティに入門ということで、メトリクスやログにトレースIDを仕込み、トレース情報と連動した運用について検証してみました。以前はメトリクスに異常値があると該当時刻からあたりをつけてログを調べたり、エラーログがあるとログのキーから他のログや周辺システムを調べたりしてましたが、トレースという単位で各テレメトリーをグルーピングして可視化することによって調査方法が非常にシンプルになったと思います。
マイクロサービスのような複雑なシステムはもちろんですが、モノリシックなシステムにおいても膨大なメトリクスやログから関連する情報を抜き出して原因の調査・分析するのは時間がかかります。オブザーバビリティの仕組みを導入することでこれらを瞬時に可視化して分析・調査できるのは運用の品質向上・負担軽減につながるので、積極的に導入を検討していきたいですね。