
1. はじめに
昨年度Kubernetes活用への道のりというタイトルで記事を執筆しながらKubernetes本体や、その周辺技術について検証を進めてきました。ちょうど一年がたったので、今回は一度立ち止まり執筆者の齋藤、山中でこの一年の内容からいくつかピックアップして振り返りました。
ちなみに、齋藤は東京オフィス、山中は大阪オフィスに勤務しています。これまで2年間Kubernetesやクラウド関連の仕事を一緒にしていますが、昨今のコロナ禍で出張することもなく実はリアルでは一度も会ったことがありません(笑)。
今回の対談もWEB対談になります。
2. Terraform
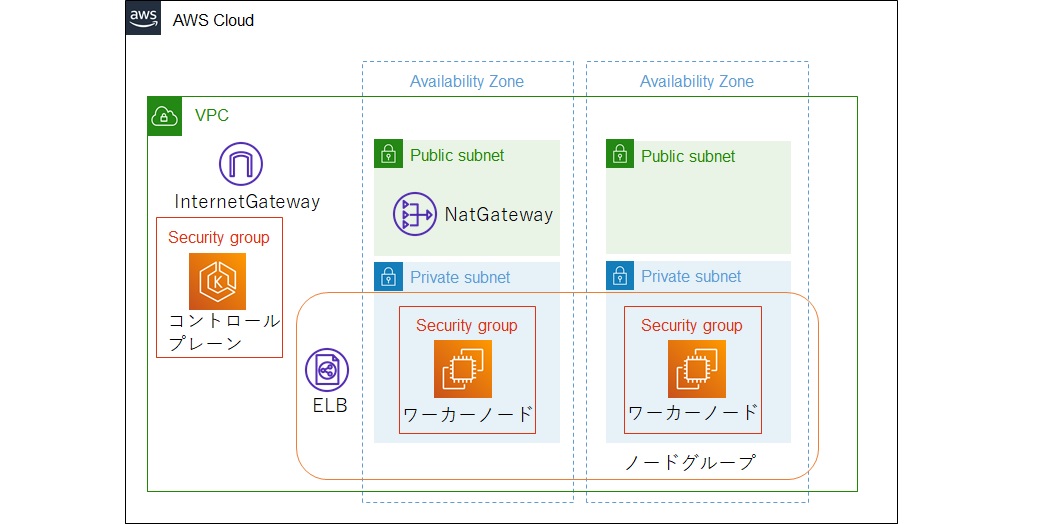
まず初めにTerraformです。TerraformはInfrastructure as Code(IaC)を実現するプロダクトとなっており、コードからクラウドの各リソースや各種SaaSのセットアップなどを実行します。Kubernetesの活用 第1回では下図のようなKubernetes(EKS)環境を構築しました。また執筆以降にも構築したEKS上で動作するアプリケーション向けのリソースやAzure環境の構築など、継続的にTerraformを活用していて感じていることについて振り返ります。
Terraformで考え方が変わった
山中:まずTerraformを使って良かったところですが、当たり前ですが一番はIaCで簡単に環境の再現ができるようになったことですね。何が良かったかって、これまでは一度環境を作ったらそこから修正していくのが当たり前だったのが、作り直したり複製したりするのが当たり前という風に自分の考え方が変わりました。
齋藤:考え方が変わるって、凄い影響力ですね(笑)。
でもその話は分かります。私も既存の環境を変更して周りに迷惑かけたくないって気持ちがあって、何か試したい時はよく別環境を作ってました。既存のIaCの設定からプレフィックスやサフィックス変更するだけでお手軽に環境複製できるので今は当たり前のようにやってますけど、以前はそうはいかなかったですからね。
山中:そうそう。コード化できるって事実よりも、その考え方の変化のほうが影響として大きかったなと感じています。
Terraformはいいとこだらけ
山中:齋藤さんのTerraformの印象ってどうでした?
齋藤:まず単純にかなり印象が良かったです。この一年色々検証して他のエコシステムなどもいいところはいっぱいありましたけど、難しい点とかもやっぱりそれなりにはあります。その点Terraformはマイナス面が少なくて製品としてのクォリティが高いなと感じています。独自言語で記述する必要がありますが、学習コストもかなり低いですし。
山中:Terraformを記述するHCL言語は、ほぼJSONみたいなものですからね。変数定義や繰り返し構文とかありますけど、特殊な要件でもない限りはあまり使い方で悩むことはなかったですね。
齋藤:言語の簡単さもそうですが、公式ドキュメントがしっかり整備されているのも大きくて、ほとんどのケースが公式サイトの情報だけで事足ります。
山中:たしかに私もTerraformでリソース作成するときほとんど公式ドキュメントを参照するだけで、あとは値に何が設定できるとかクラウド側の細かい仕様を確認したい時は各クラウドの公式ドキュメント見て作ってました。それでわからなくて色々調べながら試行錯誤するってあんまり記憶にないですね。
齋藤:そうですよね。あと、これはAWSモジュールの話にはなるんですが、モジュールのExampleにあるcompleteがかなりいいです。全機能のサンプルになるので、ほとんどの項目の記述方法がわかります。以前はなかったと思うんですけどいつから増えたのかな?
山中:モジュールによりそうですが、EKSは履歴辿ったところ、17.19.0で追加されたみたいですよ。
completeはTerraformのEKSモジュールページのExamplesプルダウンでcompleteを選択すると確認できます。
また、ページ上部にSourceCodeへのリンクがあるので、リンクを辿るとGithubでコードの確認が可能です。
齋藤:もうひとつ、実プロジェクトでの利用を想定した機能がしっかりしている印象もあります。
実際にプロジェクトで使用した場合、途中で命名規則を変更したくなったり手動で作ったリソースができたりとかイレギュラーなことが必ずあると思うんですよね。Terraformってそういった時もmoveで変更したりimportで取り込んだりと、実利用で出てきそうなイレギュラーにも対応できることが多い。痒い所に手が届くって感じですね。利用シーンを想定したり、自分たちでも使いながら機能を追加しているんだろうなと感じています。
山中:利用者がかなり多いOSSなので、いろいろプルリクなんかも上がったりしてそれにしっかり対応してるってのもありそうですね。
あと、私はもうひとつ大きな変化があったなと思うところがあって、コード化することで意味のあるまとまりで管理できるようになったと感じています。管理コンソールで作った場合は誰がどのリソース管理しているとか、どのリソースとどのリソースが関連して作られているとかが(タグ付けてないケースも多くて)把握が難しかったですが、Terraformでモジュール化したりプロジェクト分けたりすることで管理単位が明確になりました。
齋藤:コード化することで単にリソースを作成する以上の情報が付与できるようになったって考えることができますね。
山中:うまいこといいますね(笑)。
Terraformの難しいところ
齋藤:Terraformでリソースを作るとき、いきなりTerraformで作り始める時と、そうでないときがあります。どういうことかというと、VPCとかEC2のようなものはいきなり作り始めても引っかかることはほとんどないのですが、EKSのように複数のリソースで形成されるものは注意が必要です。
山中:暗黙でいろいろ関連リソースが作られるようなケースですか。最近だとEKSモジュールバージョンも大きく変わって作り直したりもしましたが、いきなり作り始めることができないケースはどのような手順で作ったんですか?
齋藤:まずは管理コンソールで作ってみて、どんなリソースが作られているか全体像を確認しています。その上でTerraformで作りながら差分を確認していくって方法を取ってましたね。
山中:なるほど。まずは管理コンソールで正解を用意してから調整していったんですね。Terraformも依存関係は解決してくれますがリソースを自動で生成するわけではないのでそのあたりの手間はどうしても残りますね。
私が気にしている点としては、バージョンアップの追従ですね。Terraform本体はGAもしたので仕様は安定していると思うのですが、プロバイダーはバージョンアップで大きく仕様が変わるケースがあるので注意が必要ですよね。案件での利用とかだとメジャーバージョンを固定するケースもあると思うのですが、最新バージョンを常に取り込んでおきたいケースだと頻繁にではないにしろ破壊的変更への対応が必要になってくる。
齋藤:EKSモジュールなんかは今年に入って大きく変わりましたね。当初の構成はまだどういう使われ方するか手探りの状態で作られたように見えていたのですが、v1.18.0以降に大幅に見直されました。間違いなくいい方向に進化しているのですが、ほとんど作り直しになりました。
山中:ここは新機能にいち早く対応する必要があることと、クラウドの進化が速いため初期設計時点では想定しきれない部分がどうしても出てくるでしょうから仕方ないとは思うんですけどね。
Azureへの展開も簡単?
山中:Azureの話もしましょうか。AWSの環境構築後にAzureもTerraformで環境構築しましたが、複数クラウドに対応した時の学習コストとかどうでしたか?
齋藤:Azureの知識が1から必要なのは間違いないですが、Terraformの知識という意味ではAWSで新しくリソースを追加するのもAzureのリソース作るのも変わりませんね。クラウドが変わったからと言って特に意識することはないです。
山中:先ほど公式ドキュメントが充実しているって話がありましたがその辺が大きいですかね?
齋藤:それもありますが、Terraformが依存関係を意識して実行してくれることが大きいですね。そのため、このリソース作ってからこれを作るみたいな順番を意識しなくていいのでクラウドが変わっても学習コストが上がらないんだと思います。
ただ、Azureは自分で1から学習しようと思うと情報量がAWSに比べて少なくて苦労しました。もちろん公式ドキュメントはしっかりしていてまずは公式ドキュメントを参照するんですが、やっぱりそれでわからないときがあるんですよね。値はわかるけど、それがどう作成リソースに影響しているかが理解しきれないとか。そういった時にAWSだと検証記事とかも多いのでそれを参考にしながらトライしてみることができるんですが、Azureについてはあまり参考情報がなく、トライアンドエラーを繰り返して苦労しました。
山中:確かに検証記事などはAWSが多いですね。ただAzureは公式の学習教材はしっかりしている印象なので、公式ドキュメントの他にMicrosoftLearnなどを利用して一通り学習するのが近道な気がしますね。
あと、他の人も同じように情報が少ないと思っているかもしれないので、今回齋藤さんが引っかかったところとか今後記事にして情報を提供する側になれば価値がありそうですね。
3. Skaffold
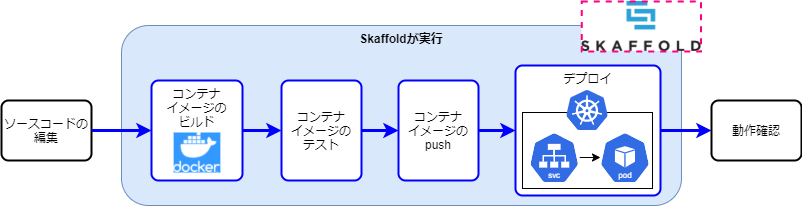
続いてはSkaffoldです。SkaffoldはKubernetesの活用 第2回で紹介しましたが、ローカルでコンテナアプリケーションを開発する際にコードの編集だけすればビルドからコンテナのデプロイまでを自動化してくれるツールになります。アプリケーション開発する際も実際に使用していたので、その際の使用感について振り返ります。
Skaffoldの使いどころ
山中:次にSkaffoldの話に移りましょうか。これまでJavaやGolangのアプリケーションを開発する際にSkaffoldを使ってみましたがどうでした?
齋藤:Skaffoldを使ってて感じたのは開発初期から使うよりは、疎通テストできるくらいのタイミングで調整するときとか、不具合修正するときに利用するのがいいのかなと思いました。あとはいくつかのリソース組み合わせた構成の技術検証などをトライアンドエラーで調べたいときとかはすごく便利ですね。サンプルアプリと必要なリソース立ち上げてソースを修正しながら都度動作を見るようなケースでコードに集中できるのがありがたい。
山中:なるほど、たしかに外部リソースを使い始めるまではアプリケーションをコンテナ化せずに進めるほうが楽ですからね。あまり早いタイミングから導入してもSkaffoldの良さは体験できないってことですね。
あと、もう一つ気になっていることがあって、外部リソースと合わせてコンテナ化する手段としてはdocker-composeが有名ですよね。Skaffoldを使っている理由って何があります?齋藤さんがdocker-compose使うとこって全然見ないんですよね。
齋藤:Skaffold使い始めてからdocker-composeほとんど使わなくなりました。正直Skaffoldのほうが使い慣れたのですぐ使えるって理由が大きいですね(笑)。
山中:それは私もそうです(笑)。あとはSkaffoldの場合ローカルにもKubernetesのYAML定義を使ってデプロイするので、テスト環境等のKubernetesにデプロイするのもスムーズなんですよね。なのでやっぱりKubernetes前提だと使い勝手がよくて選んでいるのもあるんでしょうね。
Skaffoldは結構ゴミが出る
山中:Skaffoldを最初使って気になったのが、コードを修正するたびにコンテナイメージが次々できますよね。そのゴミってどうしてます?実行コンテナはCtrl+cで止めると消えるんですけど。
齋藤:1個答えは持っていて、イメージを都度削除する--no-prune=false --cache-artifacts=falseオプションがあって、このオプションを使うとSkaffold終了時にイメージも削除してくれます。ただこれの使い方が少し工夫が必要で、そのまま使ってしまうと毎回イメージが全部削除されるので、変更があるごとにイメージが最初から作り直しになってビルド時間がかかります。なので、まずはベースとなるイメージを事前に作っておいて、アプリ部分のみが都度差分更新されるようにするやり方がいいと思います。
山中:なるほど。これまで定期的にスクリプトで消してましたけど、確かに事前にベースイメージだけ作っておけば、アプリ部分は自動削除してくれて便利ですね。
齋藤:ただ、このやり方なかなかうまく伝えられてなくて、事前にイメージ作っておくとか手順があるのでドキュメント化もしづらいんですよね。オプションについての説明であれば公式ドキュメントに書いてあるんですけどね。
山中:Skaffold関連の情報検索してても、実行コンテナの削除はだいたい書かれてますがイメージのゴミ削除の運用についてまでは書かれてないことがほとんどなので、ノウハウとしては残しておきたいですね。
ここは注意しておこう
齋藤:あと、Skaffold使っていていくつか引っかかったところがあって、まず1つ目が差分検知する仕組みのところですね。skaffold.yamlの中に走査対象のパスを書けば認識してくれると最初は思ってたんですが、実は制約があります。
今、nautibleのサンプルアプリの構成って、コード用のリポジトリとマニフェストのリポジトリが分かれていて、skaffold.yamlはコード用リポジトリに置いていますよね。今コードの変更は検知して自動で再ビルドされますが、マニフェストは更新しても差分検知されてないですよね?
山中:されてないですね。あれって上の階層は指定しても検知しないですよね?
齋藤:そう。ルートパス配下しか見てくれない。
山中:僕もGolangのアプリを用意するときにskaffold.yamlをscriptsフォルダに入れたら全く差分検知しなくて引っかかりました。とりあえず今はシェルを用意して、苦し紛れでシェルで上の階層に移動してからskaffold.yamlをファイル指定してskaffoldコマンドを実行するようにしてます。上の階層に移動してからコマンド実行したらなんとかなるんですよね。
齋藤:ファイルパスからじゃなくてコマンド実行パスからになるからそれで回避できるんですね。ただ、やっぱりSkaffoldの設定にルートパスが書けるパラメータがあればいいなと思いますね。
齋藤:次に引っかかった点がプロジェクトの構成を見直したときとかにアプリが無限にデプロイを繰り返しちゃうってことがありました。ビルド結果の生成物が差分検知されると繰り返してしまうので除外設定をするんですが、その辺の設定がうまくいかないと起きてしまいます。
山中:構成変更もそうですが、WindowsとLinuxとか環境変わるとパスの書き方が変わるのでその時も動きがおかしくなりそうですね。
齋藤:スラッシュとバックスラッシュの違いとかエスケープで2つ書くとか、公式ドキュメントを見てもどこの項目に書けばいいかはわかるけど、書き方のサンプルまでは載っていないことが多いんですよね。あってもLinux用ですし。なのでこの辺り引っかかることがあって、書いてみてうまく動かなければデバッグモードで動かしてログを調べるってことが何度かありましたね。
齋藤:あとは、Daprとの絡みにもなるのでSkaffold単独の話ではないんですが、アプリ起動時にDaprのSidecarがアクセスするリソースが先に動いてないとSkaffoldが落ちてしまうことがありました。Redisとかlocalstackの準備ができてないときですね。EKSだと順序を意識しなくても起動しますがローカルだと落ちてしまうってところがいまいちだなと。
山中:EKSでもエラーにはなるんでしょうが、Kubernetesの仕組みで復旧するまでリトライされるから結果的にうまくいくんでしょうね。ローカルのコンソールで起動している分にはエラーが出たら終了してしまうのでその違いってことですか。
齋藤:そうなんです。それの回避策として、今はDeploymentのinitコンテナで事前準備が整うのを待つようにしてるんですが、本当にそのやり方でいいのか実はすっきりしてないんですよね。ローカルのためだけの処理が入るってのが気になって。
山中:そうですね。skaffoldのYAMLならともかく、Kustomizeでローカル用にファイル分けているとはいえ設定差分ではなくDeploymentにローカル固有の挙動が入ってくるってのは気になりますね。実は僕も同じことは気になってはいたんですが、そもそもアプリ起動に全部まとめて起動する必要あるんですかね?いっそ分けてしまうのとどっちがいいかモヤモヤしていて。
齋藤:事前リソースの起動とアプリ起動の2ステップに分けるってことですか?そのほうがいいかもしれないですね。
山中:そうそう。その2ステップを手動実行しないといけないのか、Skaffoldがうまく順次実行してくれる機能があるかとか考えることはあるんですが。
齋藤:Skaffoldのパラメータはいろいろ調べたんですが、順次実行らしいものは見当たらなかったんですよね。Skaffold使うときって、開発初期ではなくデータベースとか何かしらのリソースと結合したい時なので、複数コンテナの起動順を制御して起動してくれる機能があってもよさそうなんですけど。
山中:今Skaffold.yaml見ながら話してるんですが、deploy.kustomize項目ではpathsで複数のkustomize指定できますね。これアプリと事前準備リソースでkustomize分けてしまって順に書いたらうまく起動できないですかね?
齋藤:確かにkustomize分けたらうまくいくかも。事前リソースはディレクトリ分けてしまって別Kustomizeにしてしまうほうがいいかもしれませんね。今度試してみましょうか。
まだまだ使ってない機能もある
齋藤:あと山中さんがSkaffold使っていて気になることってありますか?
山中:気になるってわけではないですが、使ってみたい機能でFileSyncがあります。HTMLやスクリプトをローカルで直したらイメージを作り直さずにコンテナ内のファイルを差し替えてくれる機能ですね。JavaやGoのようにバイナリ作るときには必要性低いんですが、フロントアプリのような場合は便利だと思うんですよね。nautibleもReactのフロントサンプル作りましたが当時はこの機能知らなくてまだ使ってないんですよね。
齋藤:最近はフロントアプリもコンテナで用意することも増えてきたので、フロントアプリの時には便利そうな機能ですね。Skaffoldも機能が多いので、他にもまだ効率的に使えてない機能とかもありそうですね。
4. Dapr
続いてはDaprです。DaprはKubernetesの活用 第4回で主にServiceInvocationやStateManagement、PubSubをデモを作成しながら機能検証しました。その際に実際に使ってみて感じたメリットや今後に期待したい点などについて振り返ります。
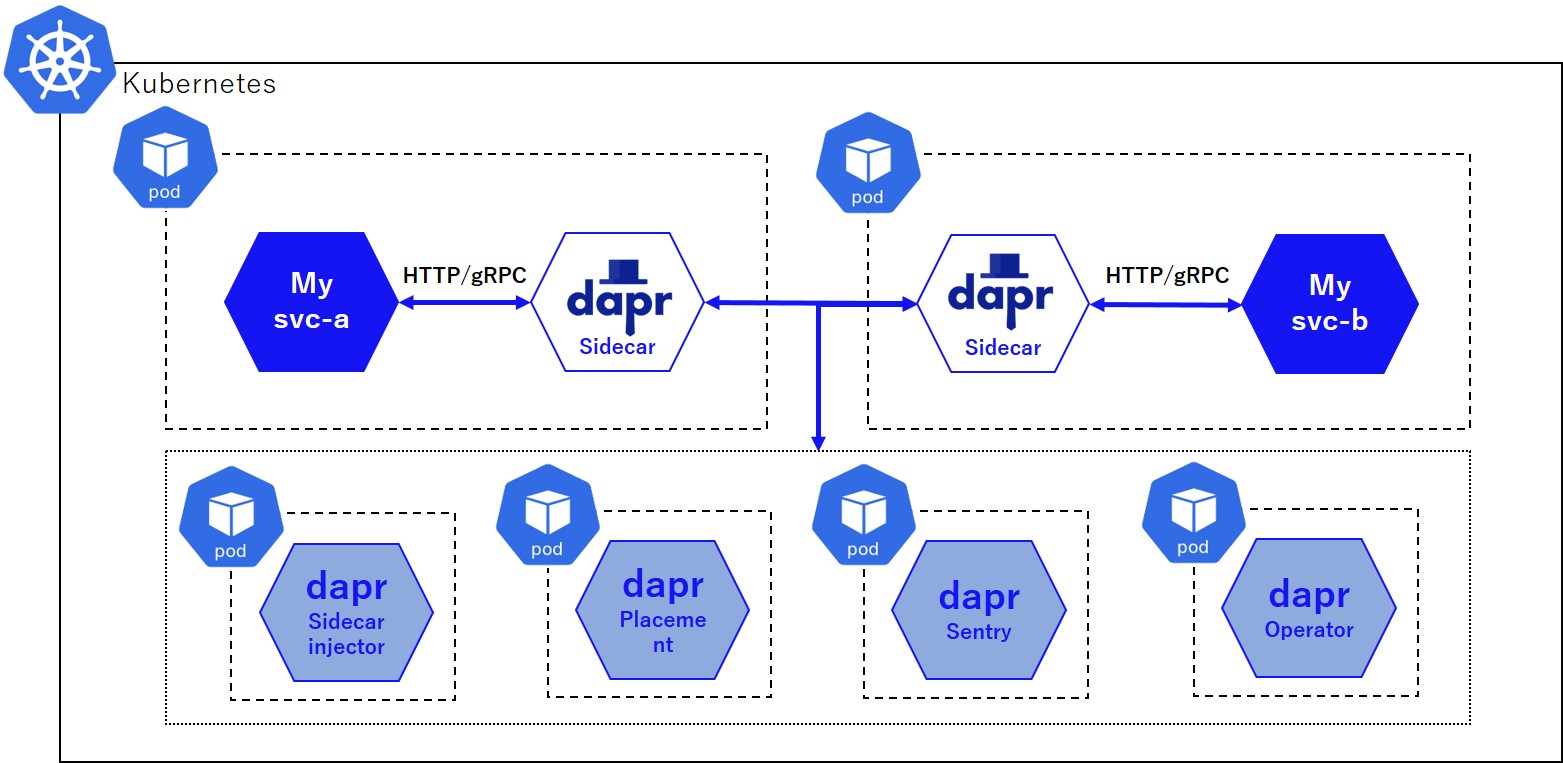
なお、DaprはMicrosoft社がリードして開発を進めている分散アプリケーション向けランタイムです。サービス間通信(同期/非同期)やステート管理のような外部アクセス機能やマイクロサービスのオブザーバビリティなどを提供しています。Kubernetes環境での基本的なアーキテクチャは下図のようになっています。
Daprは便利 でも気になるところも
山中:続いてDaprの話題に入りましょうか。
まずDaprを使ってみた印象ですが、コンテナのポータビリティを上げるのにかなり有効な選択肢だと感じています。Daprを利用することで本当にインフラに依存しないコードになりますね。私はデモアプリケーションのほかにKongAPIGatewayのカスタムプラグイン開発でも利用しましたが、キューにアクセスする機能をDaprを利用することでキューの実装に依存しないコードにできたので、ローカルだとRabbitMQ、AWSだとSQSのような切り替えが簡単にできました。
齋藤:私もすべてのインターフェースをHTTP/gRPCインターフェースに統一するってコンセプトはすごくいいと思います。エコシステムのように機能提供するようなものは動作環境が毎回異なるので、Daprでポータビリティがある仕組みにできるのもいいですね。
ただ、最近DaprのPubSub関連で何度かバグを踏むことがあって、GAしているけど結構バグがあったり大きくコードが改変されたり安定しない気がして不安な面もあるんですよね。
山中:Daprって本体がGAになっていても接続するコンポーネントごとに開発状況って異なりますよね。PubSubとかはAzureのServiceBusや一部OSSはGAしてますが、それ以外はベータやアルファが多いのでまだ変更点が多い印象ですね。
齋藤:たしかにDaprってそのあたりの仕組みがちょっと特殊ですよね。ベータやGAみたいな開発状況はプロダクトで1つが一般的ですが、Daprは内部でコンポーネントごとに別でまた開発状況がありますもんね。コンセプトは本当にいいので、自分たちが良く使うコンポーネントの開発が安定していれば非常にいい選択肢になりますね。
山中:あとDaprを最初使い始めたときにちょっと悩むのが、DaprってクライアントにHTTPクライアントかSDKか選べるじゃないですか。これ違いがあんまり明確じゃないなと感じています。齋藤さんは使い分けわかります?
齋藤:SDKはせっかくDapr使ってアプリケーションから依存関係減らしてるのにDaprに依存してしまうのであんまり使いたいと思わないですね。HTTPクライアントでいいと思ってます。
山中:私もそう思ってて、いつもHTTPクライアントで実装しているのですが、ただそれがどんなケースでもいいかどうかがわからなくて。こういうケースだとSDK使ったほうがいいよとか明確になってるとありがたいんですが。
齋藤:ユースケースがあるといいってことですね。複数パターンの使用方法がある場合、機能差があって使い分ける必要があるケースと、とりあえず複数パターン用意していて同じことが実現できるから好きなの選んでっていうのとあると思うんですが、Daprの場合は後者なんじゃないですかね。だからユースケースなども明示されてないんじゃないかなと思ってます。
これができればもっと便利になる?
齋藤:Daprに横断的に機能を差し込むようなことができると便利じゃないかなとよく思います。フレームワークとかだとよくある機能ですが。それがあると現行機能で何かが満たせなくても、自分で何とかすることができる。DaprにもMiddlewareという機能があって横断処理を追加することはできるのですが、現状作成したらコントリビュートする必要があるのでちょっと試したいことを気軽にできるようなものではないんですよ。
山中:独自に追加したいというよりは、みんなが使えるような横断機能があれば追加する仕組みがあるよって感じですね。
横断処理の話だと、とりあえず通信ログが欲しいっていつも思います。Daprって通信ログが出ないので、最初通信がうまくいかないときは通信できるまでのデバッグで苦労してて。送信元の問題か送信先の問題かの切り分けが難しい。
齋藤:デバッグは苦労しますね。デバッグモードにしてもほとんどログ出ないし、結局いつもコードを見て調べることになってます。ほんとにログの情報は欲しいですね。
山中:コード見るにしてもトレースログもないとポイントを絞り込むのも難しいし苦労しますね。
v1.7よりAPIログ出力機能(プレビュー版)が提供されました。(v1.7.1以前は不具合があるため、v1.7.2以降での利用を推奨)
利用方法は公式ドキュメントを参照してください。
山中:あと、実際に開発していて感じていたこととして、PubSubで受ける時はapplication/cloudevents+jsonじゃなく、application/jsonのほうがいいなと思いました。フレームワークによってはapplication/cloudevents+jsonだと対応してないことがあるんですよね。
齋藤:Dapr間の通信はCloudEventsでいいと思いますが、PubSubからデータ取り出すのはDaprなので、Daprから先はもう少し自由度があってもいいと思いますね。以前CloudEventsにトレースIDとか付与できるか試したことあるんですが、少なくとも当時は出来なかった記憶があります。クライアント側のヘッダ情報とかがCloudEventsの拡張項目にセットされるとかがあればいいんですが、その辺の機能がないならあんまりありがたみはないんですよね。
山中:そうそう、現状だとcloudeventsの情報って正直あんまり使うことないし、せめて選択できてもいいんじゃないかって思いながらいつもコード書いてました。
齋藤:選択できて、第一候補がapplication/jsonがいいですね。
気になるDaprとIstioの関係
齋藤:Sidecarの仕組みってどう思います?別サービスにするって選択肢もあったと思うんですが。単独での利用はいいのですが、Istioを導入している環境とかだとObservabilityとか重複する機能もあって複数Sidecar使うことに不安もあるんですよね。
山中:localhost接続によるアプリケーションコンテナのポータビリティとかを考えるとSidecarが良かったんじゃないかなと思います。パフォーマンスや遅延を考えてもSidecarのほうが有利ですしね。
Istioなどサービスメッシュとの併用については、最近はサービスメッシュの実装としてSidecarだけでなくeBPFという選択肢も出てきているので、今後eBPFも含めてサービスメッシュがどのように進化するかですね。ここは今年の要注目ポイントの1つかなと思っています。
Daprって実際の案件で導入を推進していける?
齋藤:色々話しましたけど、山中さんはDaprを実際の案件でも使っていこうと考えてますか?
山中:Kubernetes上でマイクロサービスを構築するなら使っていきたいです。やっぱりDaprのポータビリティは秀逸だと思っていて、ローカル用の環境とクラウドのマネージドサービスが同一アプリケーションコードのまま差し替えれるのは開発効率を上げるのにかなり有効ですからね。また、DaprはHTTP通信の技術だけで使えるので、導入する際に開発チームが新しいことを覚える必要がほとんどないところがいいです。
もちろんこれまで話してきたような注意点はあるので、トラブル時にコード調べたり、最悪機能が満たせないケースが発生したらDaprを外して独自のSidecarに差し替えるような判断ができるアーキテクトが必要だと思います。現状まだ発展途上で成熟していない部分も多いので、それを理解した上で採用を検討したいと考えています。
5. まとめ
振り返ってみるとどの技術も重要でKubernetesを活用する上で必要な技術要素ですが、メリットばかりでもないのでよく考えて活用していくことが重要だなと改めて感じました。 また、以前の記事執筆時点では足りなかったものも現在では解決されているケースもあります。クラウド関連の技術は日進月歩で変化しているので、これからも継続的にキャッチアップを続けながら引き続きオブジェクトの広場でお伝えしていきたいと思います。