
Kubernetesの運用コストを下げる手段の1つとして、利用時のみコンテナを起動するサーバレスアーキテクチャの活用について検証します。
1. はじめに
Kubernetesを運用していく上で出てくる課題の1つとしてコストの話があります。コンテナは基本的には最低1つは起動しておくもののため、マイクロサービスのように小さなサービスごとにアプリケーションを切り出した場合にどうしてもコンテナ数が増えコスト増につながってきます。もちろんすべてのコンテナが常時一定の処理を行っているならコストパフォーマンスが悪いという話にはなりませんが、特定時間しか処理が行われないコンテナが増えてきた場合や、開発・ステージング環境など常時使わない環境などでは、利用率に対してコストが高いように感じることがあると思います。今回はそのようなケースへの対応としてサーバレスアーキテクチャを活用したPodの効率的な運用について見ていきたいと思います。
2. Podの標準的な運用方法
まず最初にKubernetes標準機能でPodがどのように運用できるか簡単に見直しておきます。
2.1 Pod
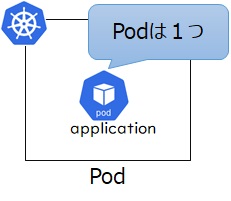
Podマニフェストをデプロイするケースです。クラスタの中にはPodが1つデプロイされるだけなので、冗長構成による可用性の向上や高負荷時のスケール等は見込めません。ただし、ノード障害などでPodが停止した際は別ノードで稼働を維持することはできます。(Podが再起動するまでの停止は伴います)
2.2 Deployment(ReplicaSet)
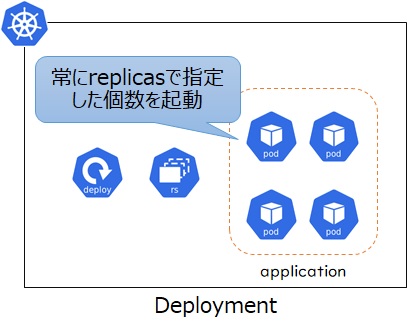
次にDeploymentでレプリカ数を指定するケースです。こちらは複数Podのレプリカ構成となるため可用性の向上や高負荷時の負荷分散が見込めます。ただしPodは常にレプリカ数に指定した数だけ起動しているため、アクセス数が少ないときなどでも一定のリソースを消費することになります。
2.3 HorizontalPodAutoscaler
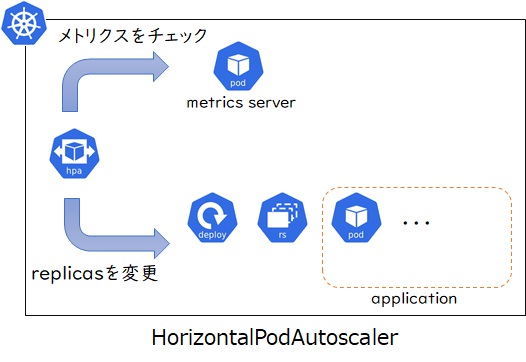
最後にHorizontalPodAutoscalerでレプリカ数を指定するケースです。こちらもDeploymentと同様に複数Podのレプリカ構成となるため可用性の向上や高負荷時の負荷分散が見込めます。また、最小・最大のPod数を指定し、動的にスケーリングする構成となるため、アクセス数に応じた効率的なリソース活用が可能になります。ただしこちらの場合もPodの最小値は1以上となるため、全く利用していない状態でも最低1つのPod分はリソースを消費します。
3. さらに効率よくPodを運用するには
ここまで見てきた通り、Kubernetesの標準機能ではほとんど利用しないようなPodでも最低1つは起動しておく必要があります。そのためアプリケーション数が増えてくると、最低限起動しておくノード数も増えることになります。常時アクセスのあるPodが大半でリソースが有効に使えていれば問題ないですが、開発環境やステージング環境のような利用頻度が低い環境や、利用数の少ないアプリケーションが多い場合はコスト効率が悪くなります。
では、コスト効率をさらに上げるためにはどうすればいいでしょうか?
クラウドを活用してシステムを構築する場合、コンテナのほかにサーバレスアーキテクチャを活用したシステムが思いつきます。このサーバレスアーキテクチャはクラウドプロバイダーがアプリケーションの実行に必要なリソースの管理を自動で行い、コストも利用分のみ支払う仕組みを提供するため、利用頻度の低い環境やアクセス数に波があるようなシステムではコスト効率よく運用できます。クラウドサービスではAWS Lambda(FaaS)が有名ですが、最近ではGoogleCloudのCloudRunやAzureのAzure Container Appsのようにコンテナベースのマネージドサービスも出てきています。
そこで、今回はEKSで構築しているKubernetes上でも同様にサーバレスアーキテクチャを適用していく手法を検討していきます。
4. Kubernetesにおけるサーバレスアーキテクチャの選択肢
Kubernetesでサーバレスアーキテクチャを実現するプロダクトとして、CNCFがホストしているものではKnativeとKEDAがあります。どちらも現在IncubatingProjectとなっており、活発に開発や利用が進められています。CNCF landscapeで確認するとServerlessのInstallablePlatformに属しています。
Knative
Knativeは2018年にGoogleが発表したオープンソースソフトウェアです。Kubernetesの上にサーバレスコンピューティングの基盤を構築することができ、リクエストやイベントをトリガーにしてコンテナを実行し、負荷に応じてコンテナの実行数をゼロから任意の数にまで自由に増減させるスケーラビリティを備えています。スケールだけでなく、クラスタ内でのビルド(現在はTektonプロジェクトに分離)やデプロイ戦略に応じたリリースなど、サーバレスの運用に必要な機能が揃っています。
GoogleCloudのマネージドコンテナサービスCloudRunはKnativeが基盤になっています。
KEDA
KEDAはマイクロソフトとRedhatが主導して開発を進めているイベント駆動型のオートスケーラです。 KEDAではキュー等へ登録されたリクエスト数を監視して、リクエスト数に応じてPodをスケールさせます。機能的にはオートスケールだけに特化しており、なおかつイベント駆動型限定のためKEDA単独では機能が限られており、必要に応じて他のプロダクトと組み合わせての利用も検討する必要があります。
AzureのマネージドコンテナサービスAzure Container AppsはKEDAが基盤になっています。
KnativeとKEDAの比較
KnativeとKEDAを比較するとKnativeのほうは多機能でサーバレスの機能をフルスタックで導入できるところが長所となりますが、その分必要とするリソースも大きくなります。一方KEDAは機能をイベント駆動かつオートスケールに限定していますが、そのオートスケールもKubernetes標準のHorizontalPodAutoscalerを利用しつつ不足分を補うような設計になっているため、KEDAを導入する際に必要となるリソースはかなり少ないことが長所になります。同じサーバレスアーキテクチャを実現するプロダクトでも方向性はかなり違うため、要件に応じて選定していく必要があります。
5 KEDAを活用したサーバレスアーキテクチャの導入
前章ではKnativeとKEDAの特徴を簡単に比較してみました。どちらを利用するかはクラスタの規模や運用方法、必要な機能などを検討の上で決めていくことになりますが、本記事では軽量なKEDAを活用したサーバレスアーキテクチャの導入を検証していきたいと思います。
KEDAはKubernetes上での利用を前提とするイベント駆動型のオートスケーラです。キューやデータベースなどへのリクエスト登録をトリガーにアプリケーションの起動やスケールをすることができます。対応しているイベントソースは公式ドキュメントの対応イベントソースを確認してください。
なお、対応イベントソースを見るとCPUやメモリ使用量によるスケールも可能となっていますが、これらはPod数を0にすることはできません。(CPUやメモリによるスケール設定もKEDAのマニフェストで運用を統一するために用意されているくらいに認識しておけばいいと思います。)
5.1 KEDAのアーキテクチャ
KEDAはKubernetes標準機能であるHorizontalPodAutoscalerを活用しながら、0<->1スケールの機能を独自に追加したものになります。
カスタムリソースScaledObjectにターゲットやトリガーの指定、スケールの設定値などを記載してKEDAに登録します。KEDAは指定されたトリガーを定期的にチェックし、データが見つかればターゲットの起動およびHorizontalPodAutoscalerの作成を行うような動きになります。
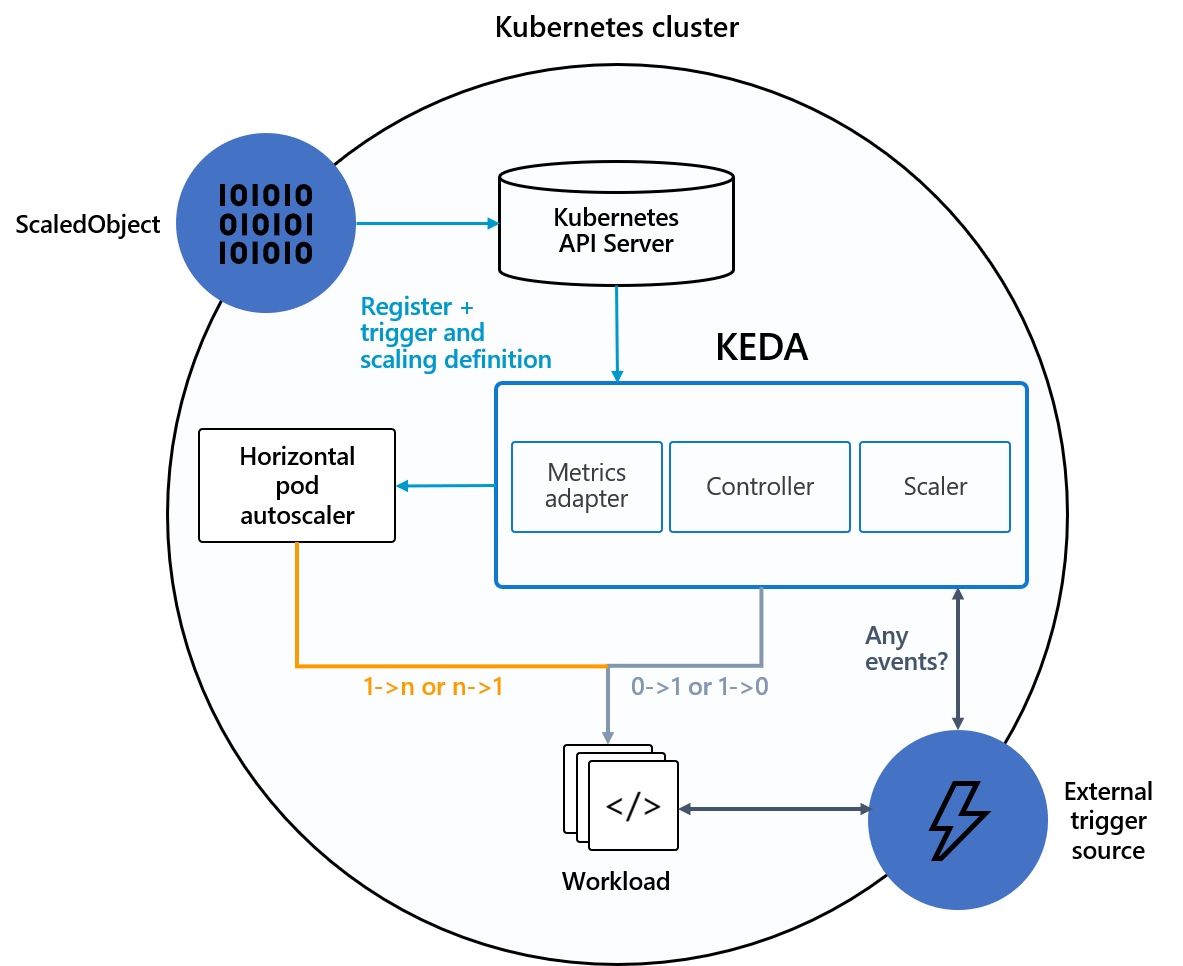
出典)https://keda.sh/docs/2.7/concepts/
5.2 KEDAを利用した非同期処理の構成
それでは、このKEDAをEKSにデプロイしてオートスケールの検証をしてみます。
今回作成するサンプルの構成は下記のようになります。
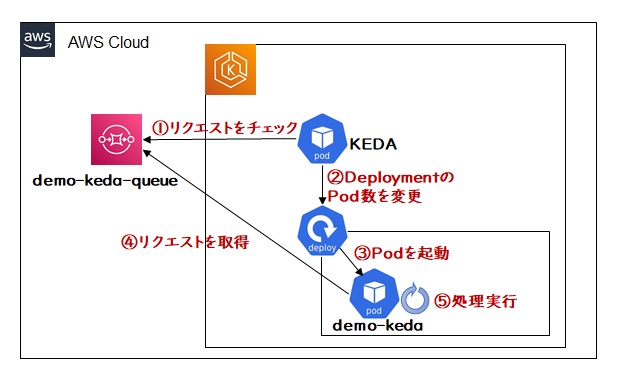
5.3 KEDAの導入
KEDAは公式のHELMチャートやOperatorHub、もしくは通常のYAMLファイルから導入することができます。今回はHELMチャートから導入します。(導入手順の詳細は公式ドキュメント参照)
helm repo add kedacore https://kedacore.github.io/charts helm repo update kubectl create namespace keda helm install keda kedacore/keda --namespace keda
5.4 サンプルアプリケーションの導入
サンプルアプリケーションの導入および動作確認手順についてはサンプルコードを参照してください。ここではサンプルコードの内容ついて簡単に補足します。
(1) サンプルアプリケーションのコード
マニフェスト(deployment.yaml)に定義された環境変数を元にSQSへ接続します。
func main() {
accountId = os.Getenv("ACCOUNT_ID")
region = os.Getenv("REGION")
sqsUrl = fmt.Sprintf("https://sqs.%s.amazonaws.com/%s/demo-keda", region, accountId)
sess, err := session.NewSession(&aws.Config{
Region: aws.String(region)},
)
if err != nil {
panic(err)
}
sqsSvc = sqs.New(sess)
SQSを定期的にチェックしてメッセージがあればチャネルに渡します。
func receiveMessages(chn chan<- *sqs.Message) {
for {
output, err := sqsSvc.ReceiveMessage(&sqs.ReceiveMessageInput{
QueueUrl: aws.String(sqsUrl),
MaxNumberOfMessages: aws.Int64(1),
WaitTimeSeconds: aws.Int64(10),
})
if err != nil {
panic(err)
}
for _, message := range output.Messages {
chn <- message
}
}
}
receiveMessagesを別ゴルーチンで起動し、メッセージが渡されてきたらプリントします。
messages := make(chan *sqs.Message, 1)
go receiveMessages(messages)
for message := range messages {
fmt.Println("receive message ...")
fmt.Println(*message.Body)
sqsSvc.DeleteMessage(&sqs.DeleteMessageInput{
QueueUrl: aws.String(sqsUrl),
ReceiptHandle: message.ReceiptHandle,
})
}
}
(2) ScaledObject
KEDAを利用してアプリケーションのオートスケールを行うにはScaledObjectリソースの作成が必要になります。
ScaledObjectでは主に以下の定義を行います。
- ターゲットアプリケーション
- スケーリングの基準値
- トリガー
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
idleReplicaCount: 0 # Optional. Default: ignored, must be less than minReplicaCount: 1 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
fallback: # Optional. Section to specify fallback options
failureThreshold: 3 # Mandatory if fallback section is included
replicas: 6 # Mandatory if fallback section is included
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
name: {name-of-hpa-resource} # Optional. Default: keda-hpa-{scaled-object-name}
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
出典)https://keda.sh/docs/2.7/concepts/scaling-deployments/#overview
triggersに関しては、利用するリソースごとに設定内容が異なります。こちらからリソースを選択してドキュメントを参照してください。
サンプルコードではAWSのSQS(キュー名:demo-queue)を利用して「demo」アプリケーションのオートスケールをKEDAでコントロールしています。
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: demo-scaledobject
namespace: default
spec:
scaleTargetRef:
name: demo-keda
pollingInterval: 3
cooldownPeriod: 60
minReplicaCount: 0
maxReplicaCount: 10
triggers:
- type: aws-sqs-queue
metadata:
queueURL: demo-keda
queueLength: "10"
awsRegion: "ap-northeast-1"
identityOwner: operator
なお、queueLengthは1つのアプリケーションで捌ける上限値の設定になります。(上記例だとキューに10個リクエストが溜まるごとにスケールされる)
【補足】
queueURLについては、ドキュメント上はURL指定となっていますが、Github上のコードを見ると名前だけでも処理できるようになっていました。そのため、EKSとSQSが同一リージョンにあればキュー名だけを指定することも可能です。
keda/pkg/scalers/aws_sqs_queue_scaler.go
queueURL, err := url.ParseRequestURI(meta.queueURL)
if err != nil {
// queueURL is not a valid URL, using it as queueName
meta.queueName = meta.queueURL
} else {
queueURLPath := queueURL.Path
queueURLPathParts := strings.Split(queueURLPath, "/")
if len(queueURLPathParts) != 3 || len(queueURLPathParts[2]) == 0 {
return nil, fmt.Errorf("cannot get queueName from queueURL")
}
meta.queueName = queueURLPathParts[2]
}
6. 同期通信への拡張
イベント駆動型(非同期型)アプリケーションについては、KEDAを単独で利用するだけで使用しないときは(サーバレスのように)Pod数を0にすることが簡単に実現できます。しかし現状まだまだクライアントからHTTP(S)リクエストを受けてレスポンスを返す同期型のシステムが多いのではないでしょうか。
KEDAはリクエストがキューに溜まっている間にアプリケーションを起動し、アプリケーションがキューにリクエストを取りに行くモデルになりますので、下図のようにキューの保留場所がなく直接リクエストを送信されるような仕組みではPod数を0にすることができません。
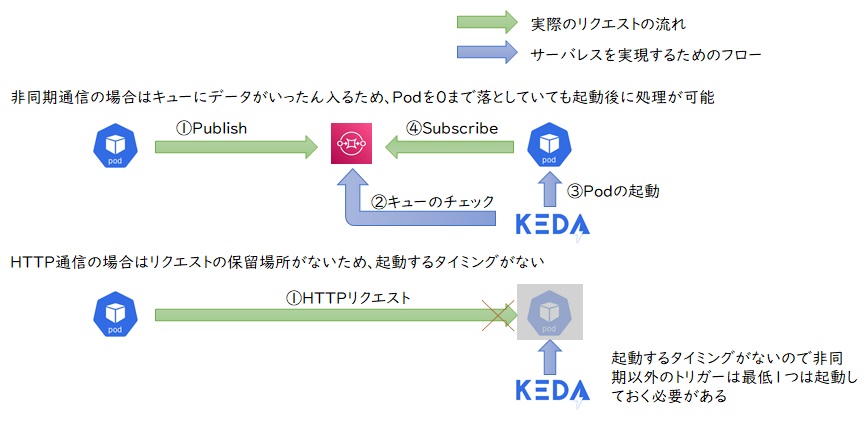
そのため、同期通信に対応しようと考えた場合、アプリケーションの手前でリクエストをいったん保留し、KEDAがアプリケーションを起動した後にリクエストを流す仕組みが必要になります。今回はその仕組みをKong Gatewayを使って実現してみたいと思います。
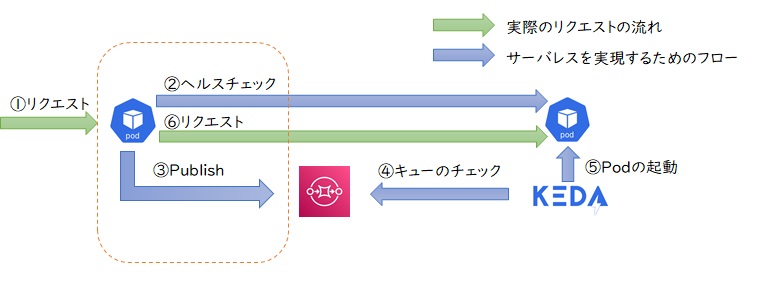
6.1 Kong Gateway
Kong GatewayはOSSで開発されている代表的なAPIゲートウェイの1つです。Nginxベースの高パフォーマンスやオンプレ・クラウドどちらでも導入できる特長があります。 また、Kongにはプラグイン機構があり、リクエストを受け取った際やレスポンスを返す際など、いくつかのタイミングで処理をフックして独自機能を追加することが可能です。以前はLuaによる実装が必要でしたが、バージョン2以降ではGoなどでも開発可能になったため各段開発しやすくなりました。今回、このプラグイン機構を活用してリクエストを受けた際にバックエンドのヘルスチェックやキューへのデータ登録を実現してみたいと思います。
全体のアーキテクチャは下記のようになります。
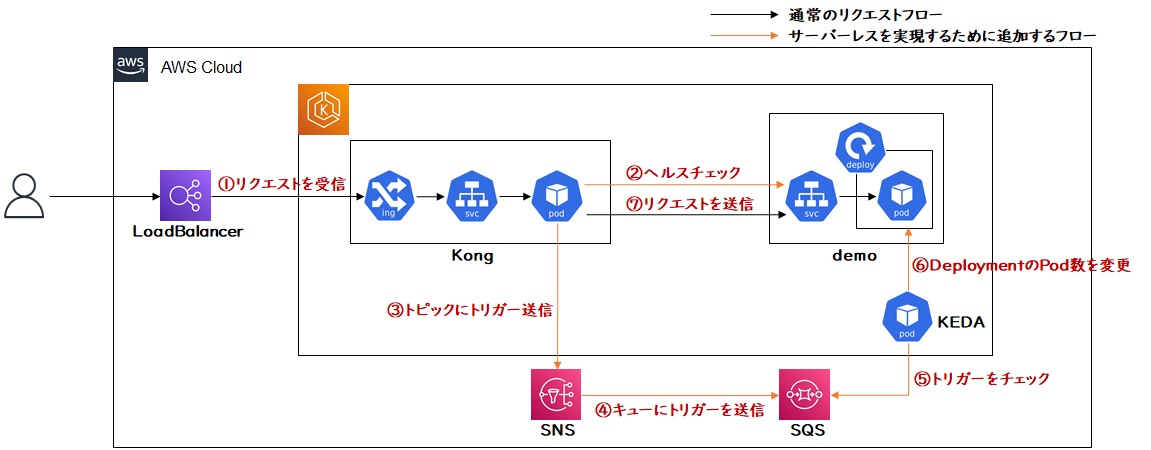
6.2 カスタムプラグインの開発
カスタムプラグインは主に以下の4つの手順で開発します。
- APIGateway上の特定のタイミングをフックして呼び出すメソッドの実装
- カスタムプラグインに渡す設定をKongPluginマニフェストに定義
- 標準のKong Gatewayにカスタムプラグインのバイナリを追加したDockerイメージを作成
- カスタムプラグインを追加したコンテナをデプロイするようにDeploymentを変更
それぞれの内容を順番に見ていきますが、実装コードおよびサンプルアプリケーションの動作確認手順の全体についてはnautible-kong-serverlessリポジトリを参照してください。ここでは開発時のポイントとなるコードについて簡単に補足します。
(1) APIGateway上の特定のタイミングをフックして呼び出すメソッドの実装
Goによるカスタムプラグインはgo-pdkをimportして開発します。フックするポイントごとのメソッドがあらかじめ用意されており、バックエンド送信前に処理を行う場合はAccessメソッドを定義して実装します。
package main
import (
"github.com/Kong/go-pdk"
"github.com/Kong/go-pdk/server"
)
func (conf Config) Access(kong *pdk.PDK) {
// リクエスト情報などは引数のPDKから取得できる
check, err := kong.Request.GetQueryArg("check")
// その他実装をここに追記していく
}
引数として受け取るPDKの構造体は以下のようになっています。詳細な仕様は公式のAPIドキュメントを参照してください。
type PDK struct {
Client client.Client
Ctx ctx.Ctx
Log log.Log
Nginx nginx.Nginx
Request request.Request
Response response.Response
Router router.Router
IP ip.Ip
Node node.Node
Service service.Service
ServiceRequest service_request.Request
ServiceResponse service_response.Response
}
なお、定義されているフックポイントは下記のとおりです。(バージョン2.8時点)
| メソッド | タイミング |
|---|---|
| Certificate | 証明書提供フェーズで実行。 |
| Rewrite | リクエスト受信時に実行。 |
| Access | バックエンドへ送信前に実行。 |
| Preread | 接続ごとに1回実行。 |
| Response | レスポンス送信前に実行。 |
| Log | ログ出力。接続終了時に1回実行。 |
(2) カスタムプラグインに渡す設定をKongPluginマニフェストに定義
Kong GatewayのカスタムプラグインはKongPluginマニフェストに定義したconfig項目を読み込むことが可能です。環境ごとに異なる設定値などはこのKongPluginマニフェストからコンテナにパラメータを渡します。
今回は以下のようなマニフェストを用意します。
apiVersion: configuration.konghq.com/v1
kind: KongPlugin
metadata:
name: serverless
config:
count: 300 # ヘルスチェック回数
interval: 100 #ヘルスチェック間隔
backend: # バックエンドごとの設定
- target: /kong/consumer #ターゲットへのルーティング設定
health: /healthz # ヘルスチェックパス
pubsub: kong-serverless-plugin # Pub/Sub名(後述するDaprのマニフェストで定義)
topic: kong-root-request # トピック名
plugin: serverless
このconfig定義をマッピングした構造体を用意することでGoの実装側で利用することができます。
type Config struct {
Backend []struct {
Target string
Health string
Pubsub string
Topic string
}
Count int
Interval int
}
func (conf Config) Access(kong *pdk.PDK) {
count := conf.Count
interval := conf.Interval
for _, backend := range conf.Backend {
target := backend.Target
health := backend.Health
pubsub := backend.Pubsub
topic := backend.Topic
}
...
}
(3) 標準のKong Gatewayにカスタムプラグインのバイナリを追加したDockerイメージを作成
カスタムプラグインを導入したイメージを作成するため、go-plugin-toolイメージでプラグインのビルドを行い、作成したバイナリをkongイメージに追加します。
FROM kong/go-plugin-tool:latest-alpine-latest as builder
ENV GO111MODULE=on
RUN mkdir /go-plugins
COPY ./cmd/ /go-plugins/cmd/
COPY ./pkg/ /go-plugins/pkg/
COPY ./go.mod /go-plugins/
COPY ./go.sum /go-plugins/
RUN cd /go-plugins && \
go build -o /go-plugins/bin/serverless cmd/main.go
FROM kong:2.8.1
COPY --from=builder /go-plugins/bin/serverless /usr/local/bin/serverless
イメージを作成して、AWSのECR(下記例はパブリックリポジトリ)にプッシュします。
docker build -t <イメージ名>:<バージョン> -f ./package/Dockerfile . aws ecr-public get-login-password --region us-east-1 | docker login --username AWS --password-stdin public.ecr.aws/<リポジトリ名> docker tag <イメージ名>:<バージョン> public.ecr.aws/<リポジトリ名>/<イメージ名>:<バージョン> docker push public.ecr.aws/<リポジトリ名>/<イメージ名>:<バージョン>
(4) カスタムプラグインを追加したコンテナをデプロイするようにDeploymentを変更
カスタムプラグインを導入したイメージを利用するため、Kongのマニフェストを編集します。
Deployment: spec.template.spec.containers.env
- name: KONG_PLUGINS
value: bundled, serverless
- name: KONG_PLUGINSERVER_NAMES
value: serverless
- name: KONG_PLUGINSERVER_SERVERLESS_QUERY_CMD
value: /usr/local/bin/serverless -dump
image: <リポジトリ名>/<イメージ名>:<バージョン>
6.3 Daprを活用した環境依存の排除
前章の実装を進めることでカスタムプラグインを用意することは可能ですが、今回はもう1つ工夫を加えたいと思います。
カスタムプラグインからトリガーとなるキューにデータを登録する際に、通常の実装であればトリガーの種類ごとに実装が必要になってきます。KEDAは各クラウドプロバイダーのマネージドサービスや各種OSSのキューに対応していますが、それに合わせてカスタムプラグインを実装するのは少し手間がかかります。対応するトリガーを限定してもよいのですが、今回はトリガーへの登録を直接行わずDaprを介することで環境依存を排除した実装にします。
なおDaprは第4回 分散アプリケーション開発編 Daprを活用して分散アプリケーションを構築してみようを参照の上、事前にクラスタへ導入してください。
(1) Kong GatewayへDaprサイドカーを導入
Kong GatewayのPodにDaprサイドカーを導入するには、DeploymentのannotationsにDaprを有効化するための定義を追加します。
spec:
replicas: 1
selector:
matchLabels:
app: ingress-kong
template:
metadata:
annotations:
kuma.io/gateway: enabled
traffic.sidecar.istio.io/includeInboundPorts: ""
dapr.io/enabled: "true" #daprのサイドカーを有効化
dapr.io/app-id: "serverless" #アプリケーションIDをserverlessで定義
dapr.io/app-port: "8000" #アプリケーションのリッスンポート8000を定義
labels:
app: ingress-kong
(2) Pub/Subコンポーネントの導入
DaprからPub/Subへアクセスするため、Daprで定義されているカスタムリソースのComponentを導入します。
apiVersion: dapr.io/v1alpha1
kind: Component
metadata:
name: kong-serverless-plugin
namespace: kong
labels:
app.kubernetes.io/name: kong-serverless-plugin
app.kubernetes.io/instance: kong-serverless-plugin
app.kubernetes.io/version: 1.0.0
app.kubernetes.io/component: pubsub
app.kubernetes.io/part-of: nautible
app.kubernetes.io/managed-by: manual
spec:
type: pubsub.snssqs
version: v1
metadata:
- name: region
value: ap-northeast-1
(3) アプリケーションからHTTP POST通信でDaprにアクセスする
Goの実装側ではDaprで定義されているPub/Sub用のエンドポイントにPOSTするだけでパブリッシュできますので、環境が変わってもKongPluginマニフェスト側で定義を変更するだけで異なるPub/Subへ対応することが可能になります。
urlTarget := fmt.Sprintf("http://localhost:3500/v1.0/publish/%s/%s", pubsub, topic)
res, err := http.Post(url_target, "application/json", bytes.NewBuffer(ping_json))
このようにすることで下記のようにDaprを介した通信となり、アプリケーション側ではトリガーの実装が何かを意識する必要がなくなります。

7. おわりに
今回はKEDAを活用したKubernetes上でのサーバレスアーキテクチャの構築を見てきました。イベント駆動に限定すればKEDAは簡単に利用を開始できますし、Kong Gatewayと組み合わせることでHTTP通信への対応も実現できます。 もちろん、最初からカスタマイズまでスコープに入れるならKnativeのほうが有力な選択肢になると思いますので、KEDAの使いどころとしては基本的には標準機能(イベント駆動)だけで十分なクラスタに対して導入してみて、カスタマイズは後々必要になった際に検討するような方針がいいと思います。
コンテナ運用もマネージドなサーバレス環境や、OSSの導入によるサーバレス環境の構築が可能になってきました。うまく活用すればコストを抑えることができますので検討してみてはいかがでしょうか。