
本連載ではKubernetesやマイクロサービスを活用するにあたりどんな準備を進めておけばいいか整理します。第5回はPrometheus・Grafanaを活用してモニタリング、ロギングする方法を紹介します。
1. はじめに
前回Kubernetes上にDaprを活用したマイクロサービスアプリケーションの導入まで実施しました。アプリケーションが稼働するところまでは出来ましたので、今回はKubernetesやその上で動作するアプリケーションのモニタリングやログの可視化を行います。ここまでで本連載としては一区切りになります。
また、今回は検証パターンとして、Kubernetes内ですべてリソースを用意するケースと、一部AWSのマネージドサービスを利用する例を紹介します。
2. モニタリング
モニタリングではリソース(CPU、メモリ、ディスクなど)の使用量やパフォーマンス、アプリケーションの死活監視などを行います。モニタリングにはPrometheusを使用しますが、Prometheus本体だけではモニタリングに必要な機能を満たせませんので、周辺ツールも含むprometheus-operator※を利用して導入します。
※ Operatorとはカスタムリソースを定義することでKubernetesの機能を拡張し、複雑なアプリケーションの導入や運用などを自動化する仕組みになります。
2.1 アーキテクチャ
prometheus-operatorを利用して環境を構築した場合、下記のようなアーキテクチャになります。ServiceMonitorリソースでターゲットとなるServiceを指定し、PrometheusはServiceMonitorで定義されているサービスからメトリクスを収集します。(Serviceを定義していないPod用にPodMonitorもあります)
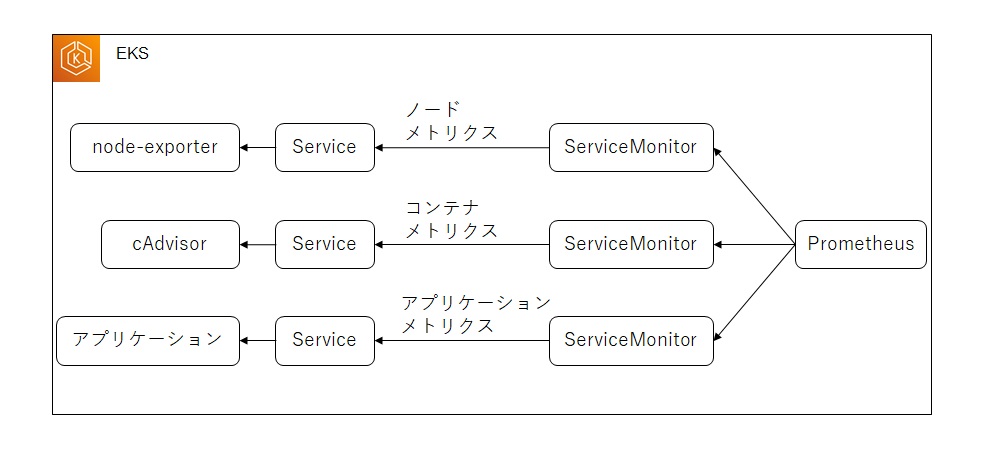
メトリクスの収集はPrometheus側からPullする仕組みのため、矢印はPrometheusから収集先に向かっています
ノードに関するメトリクスはnode-exporterから、コンテナに関するメトリクスはcAdvisorから収集します。prometheus-operatorを導入するとこれらのメトリクスを収集するためのServiceMonitorが標準で導入されます。アプリケーションが出力するメトリクスの監視は個別にServiceMonitorを導入して監視します。
2.2 Prometheusの導入
それではprometheus-operatorを使用してPrometheusを導入します。
導入コンポーネントの一覧は公式サイトにある通り以下のものになります。
- The Prometheus Operator
- Highly available Prometheus
- Highly available Alertmanager
- Prometheus node-exporter
- Prometheus Adapter for Kubernetes Metrics APIs
- kube-state-metrics
- Grafana
また、上記には直接記載はありませんが、導入するPrometheusやGrafana等を監視するためのServiceMonitorやAlertRuleなども導入されます。
今回は第1回で構築したEKSおよびArgoCDの環境への導入を前提としますので、ArgoCDのアプリケーションリソースを用意して導入します。(Kubernetesのバージョンは1.21とします)
(1) kube-prometheusをclone
prometheus-operatorにはオペレータ本体の開発に使われているリポジトリ(prometheus-operator)と、開発したprometheus-operatorを導入するリポジトリ(kube-prometheus )があります。そのため、導入の際はkube-prometheusリポジトリをcloneします。kube-promehtuesはバージョンごとにサポートする(テスト済み)Kubernetesのバージョンが異なります。 サポートするバージョンのマトリクス表が公式のドキュメントにありますので参考にしてください。
今回は、kubernetes1.21に導入するため、release-0.9をcloneします。
git clone https://github.com/prometheus-operator/kube-prometheus.git --branch release-0.9
cloneしてきたら、manifestsディレクトリ配下をArgoCDから参照できるように自身のリポジトリに配置します。
ディレクトリ構成
リポジトリルート └manifests └setup
setupディレクトリにはprometheus-operatorを使用するためのカスタムリソースが定義されています。manifests直下にはprometheus-operatorを導入するためのマニフェストが定義されています。
(2) kube-prometheusの導入
ArgoCDのアプリケーションとしてkube-prometheusを導入します。
注意点として、2022年3月現在prometheus-operatorはkubectl applyコマンドでのカスタムリソース導入でエラー(カスタムリソースのサイズが大きすぎるため)が発生します。ArgoCDでデプロイする際も通常内部ではkubectl applyでのデプロイを行うため同様にエラーが発生します。 ArgoCDの公式にapplyが失敗するときの対応手順として、Replace=trueをつけることでkubectl replace or kubectl createでデプロイされると記載がありますので、その方式を利用してデプロイします。
カスタムリソースの導入(application_crd.yaml)
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: prometheus-operator-crd
namespace: argocd
spec:
destination:
namespace: observation
server: https://kubernetes.default.svc
project: default
source:
path: 'manifests/setup'
repoURL: https://github.com/<ユーザー>/<リポジトリ>
targetRevision: HEAD
syncPolicy:
automated:
prune: true
syncOptions:
- CreateNamespace=true
- Replace=true
kube-prometheus本体の導入(application.yaml)
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: prometheus-operator
namespace: argocd
spec:
destination:
namespace: observation
server: https://kubernetes.default.svc
project: default
source:
path: 'manifests/'
repoURL: https://github.com/<ユーザー>/<リポジトリ>
targetRevision: HEAD
syncPolicy:
automated:
prune: true
syncOptions:
- CreateNamespace=true
2.3 Prometheus、Grafanaの動作確認
リソースの作成が完了したら、ブラウザで起動していることを確認します。
(1) 導入サービスの一覧を確認
kubectl get svc -n monitoring NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE alertmanager-main ClusterIP 10.100.61.139 <none> 9093/TCP,8080/TCP 7d22h alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 7d22h blackbox-exporter ClusterIP 10.100.254.165 <none> 9115/TCP,19115/TCP 7d22h grafana ClusterIP 10.100.142.192 <none> 3000/TCP 7d22h kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 7d22h node-exporter ClusterIP None <none> 9100/TCP 7d22h prometheus-adapter ClusterIP 10.100.124.16 <none> 443/TCP 7d22h prometheus-k8s ClusterIP 10.100.23.165 <none> 9090/TCP,8080/TCP 7d22h prometheus-operated ClusterIP None <none> 9090/TCP 7d22h prometheus-operator ClusterIP None <none> 8443/TCP 7d22h
(2) ポートフォワードしてローカルのブラウザで確認
Prometheus
kubectl port-forward svc/prometheus-k8s -n monitoring 9090:9090
動作確認URL
http://localhost:9090
Grafana
kubectl port-forward svc/grafana -n monitoring 3000:3000
動作確認URL
http://localhost:3000
AlertManager
kubectl port-forward svc/alertmanager-main -n monitoring 9093:9093
動作確認URL
http://localhost:9093
Grafanaのみログインが必要になるので、ID:admin PW:adminで初回ログインします。
3. モニタリング設定
導入時点でノードやコンテナのモニタリングはできるようになっているので、実際にPrometheusから確認してみます。Prometheusの画面にアクセスしてGraphタブから確認します。(Grafanaで確認することも可能です)
なお、Prometheusでのデータ取得にはPromQLを使用します。クエリの文法等はPrometheusのサイトを参照してください。
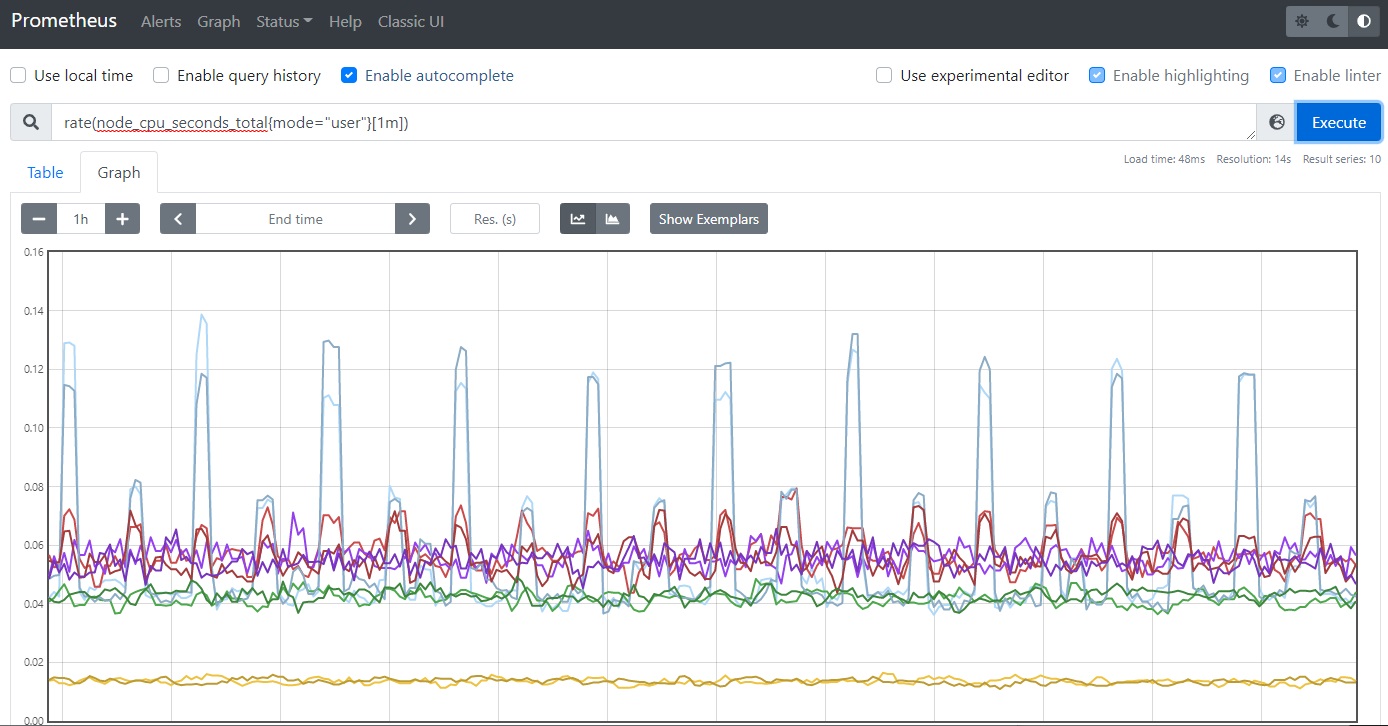
3.1 ノードのモニタリング
各ノードでnode-exporterのDaemonSetが起動しているので、Prometheusの画面でノードの状態が確認できます。
例)CPU(user)の使用率
rate(node_cpu_seconds_total{mode="user"}[1m])
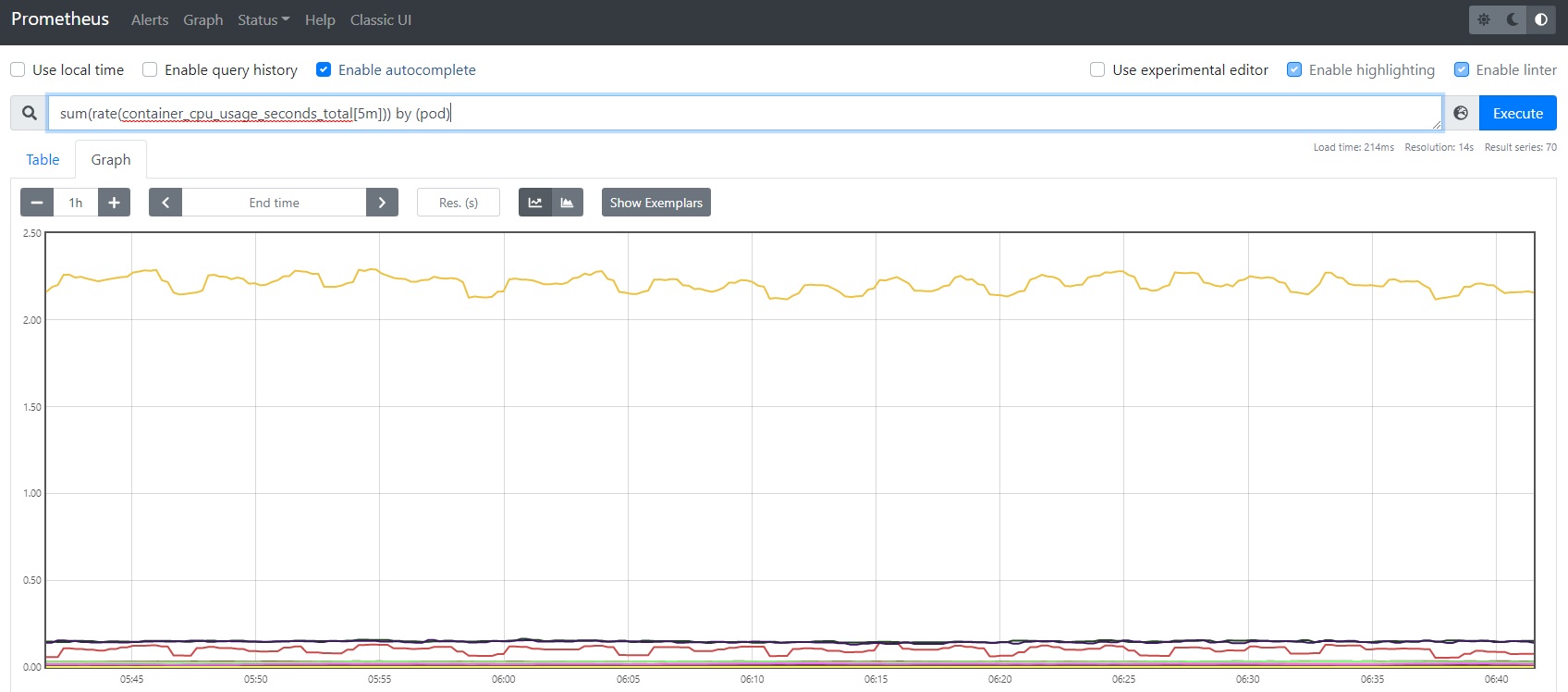
3.2 コンテナのモニタリング
コンテナのモニタリングもkubeletのServiceでメトリクスが公開されているため、確認することができます。
例)PodごとのCPU使用時間
sum(rate(container_cpu_usage_seconds_total[5m])) by (pod)
3.3 アプリケーションのモニタリング
次にアプリケーションが出力したメトリクスをPrometheusで可視化してみます。サンプルとしてリクエスト数をmetricsとして出力するアプリケーションを用意して、その値をPrometheusで確認してみます。
(1) サンプルアプリケーションの準備
サンプルのGoアプリケーションを用意します。サンプルアプリケーションで実装する内容は下記になります。
リクエストのエンドポイント
サンプルでは以下2つのエンドポイントを用意します。
- “/”
- リクエストを受信するとPrometheusのCounterコレクタを使用して受信回数をインクリメントします。このエンドポイントはテストのために実際にブラウザなどからアクセスするものになります。
- “/metrics”
- “/"エンドポイントアクセス時にインクリメントしているカウンタ値をメトリクスとして応答します。このエンドポイントはPrometheusから参照するものになります。
コードの抜粋
import (
...
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
httpReqs = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "http_request_total",
Help: "Number of HTTP Request.",
},
[]string{"path"},
)
)
func init() {
prometheus.MustRegister(httpReqs)
}
func metrics(w http.ResponseWriter, r *http.Request) {
promhttp.Handler().ServeHTTP(w, r)
}
func handler(w http.ResponseWriter, r *http.Request) {
m := httpReqs.WithLabelValues("/")
m.Inc()
fmt.Fprint(w, string("hello world"))
}
func main() {
http.HandleFunc("/metrics", metrics)
http.HandleFunc("/", handler)
http.ListenAndServe(":18080", nil)
}
作成したアプリケーションは「app: demo-service」ラベルを持つアプリケーションとしてEKSへデプロイします。
(2) ServiceMonitor
アプリケーションのServiceをターゲットとするServiceMonitorリソースを作成します。この例では、defaultネームスペースにある「app: demo-service」ラベルを持つサービスをターゲットに「spec.ports.name: http」のポートからメトリクスを収集するServiceMonitorが作成されます。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: servicemonitor-demo-service
namespace: monitoring
labels:
serviceapp: demo-service
release: prometheus-operator
spec:
selector:
matchLabels:
app: demo-service
endpoints:
- port: http
interval: 30s
namespaceSelector:
matchNames:
- default
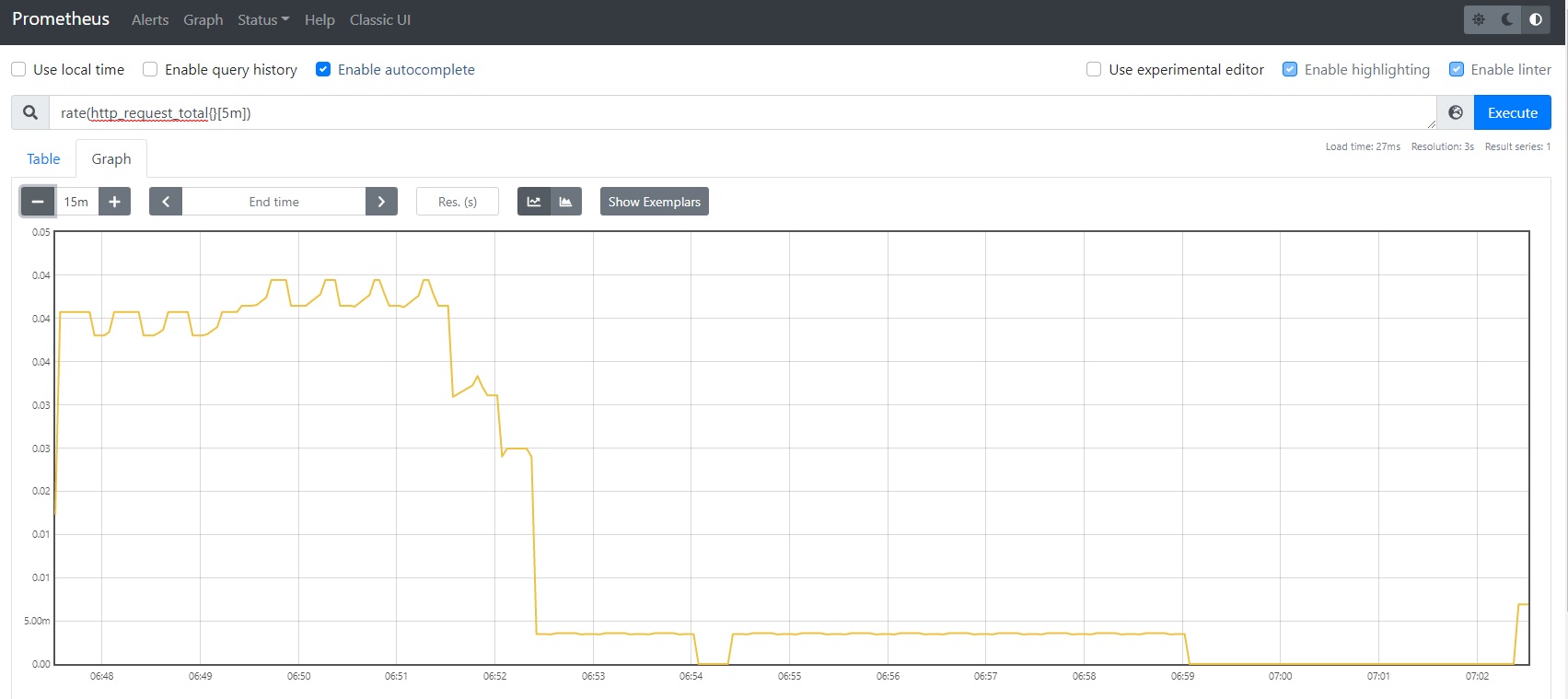
(3) Prometheus(Grafana)で確認
サンプルアプリケーションに何度かアクセスした後、5分間のリクエストレートを出力してみます。
rate(http_request_total{}[5m])
4. ロギング
次はアプリケーションログを収集します。今回はGrafanaLokiとPromtailを利用した構成で構築します。
4.1 アーキテクチャ
PromtailとGrafanaLokiを利用したログ収集の仕組みは下記のようになります。各ノードにDaemonsetとしてデプロイしたPromtailが標準出力ログを収集し、GrafanaLokiでログを永続化します。Grafanaでは永続化したログを可視化します。
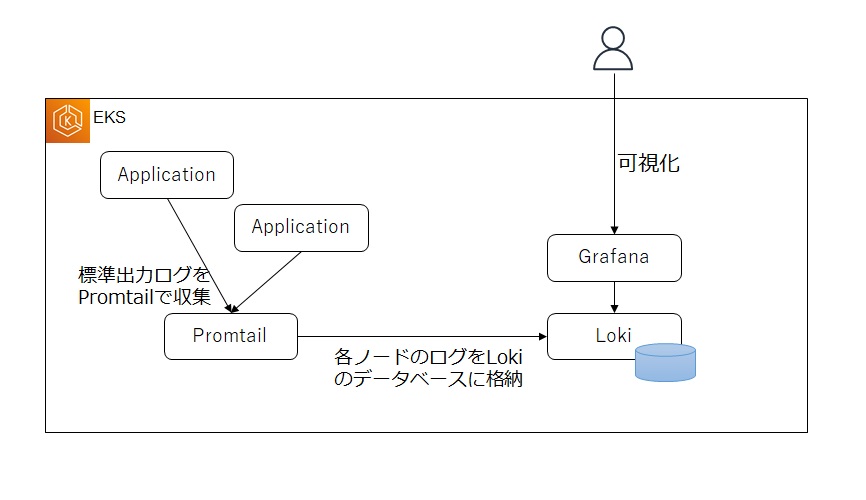
4.2 GrafanaLoki・Promtailの導入
導入はこちらもArgoCDのアプリケーションとして導入していきます。
(1) GrafanaLoki
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: loki
namespace: argocd
finalizers:
- resources-finalizer.argocd.argoproj.io
spec:
destination:
namespace: monitoring
server: 'https://kubernetes.default.svc'
source:
chart: 'loki'
repoURL: 'https://grafana.github.io/helm-charts'
targetRevision: 2.9.1
helm:
version: v3
releaseName: loki
values: |
replicas: 1
persistence:
enabled: true
project: default
syncPolicy:
automated:
prune: true
selfHeal: false
syncOptions:
- CreateNamespace=true
(2) Promtail
Promtailは導入時にHelmのValuesに収集条件を設定します。下記例では「app: demo-***」ラベルを持つアプリケーションを対象に、JSON形式のログを収集しています。その際level、id、url、methodでラベル付けをしてGrafanaで検索できるようにしています。また、metrics条件ではエラー件数をPrometheusで検出できるように設定しています。(ここについては後程利用します)
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: promtail
namespace: argocd
finalizers:
- resources-finalizer.argocd.argoproj.io
spec:
destination:
namespace: monitoring
server: 'https://kubernetes.default.svc'
source:
chart: 'promtail'
repoURL: 'https://grafana.github.io/helm-charts'
targetRevision: 3.11.0
helm:
version: v3
releaseName: promtail
values: |
serviceMonitor:
enabled: true
config:
lokiAddress: http://loki:3100/loki/api/v1/push
snippets:
pipelineStages:
- docker:
- match:
selector: '{app=~"demo-.*"}'
stages:
- json:
expressions:
level: level
id: id
url: url
method: method
- labels:
level:
dt:
url:
method:
- metrics:
log_error_total:
type: Counter
description: error number
prefix: promtail_custom_
source: level
config:
value: ERROR
action: inc
project: default
syncPolicy:
automated:
prune: true
selfHeal: false
syncOptions:
- CreateNamespace=true
4.3 Grafanaでログを確認
(1) Grafanaの設定
GrafanaでLokiが格納したログデータを参照できるように設定します。
Lokiのサービスを確認
kubectl get svc -n monitoring NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ... loki ClusterIP 10.100.108.199 <none> 3100/TCP 6m18s loki-headless ClusterIP None <none> 3100/TCP 6m18s ...
Lokiはサービス名loki、ポート3100で待ち受けしているのがわかりますので、GrafanaのURLに指定します。
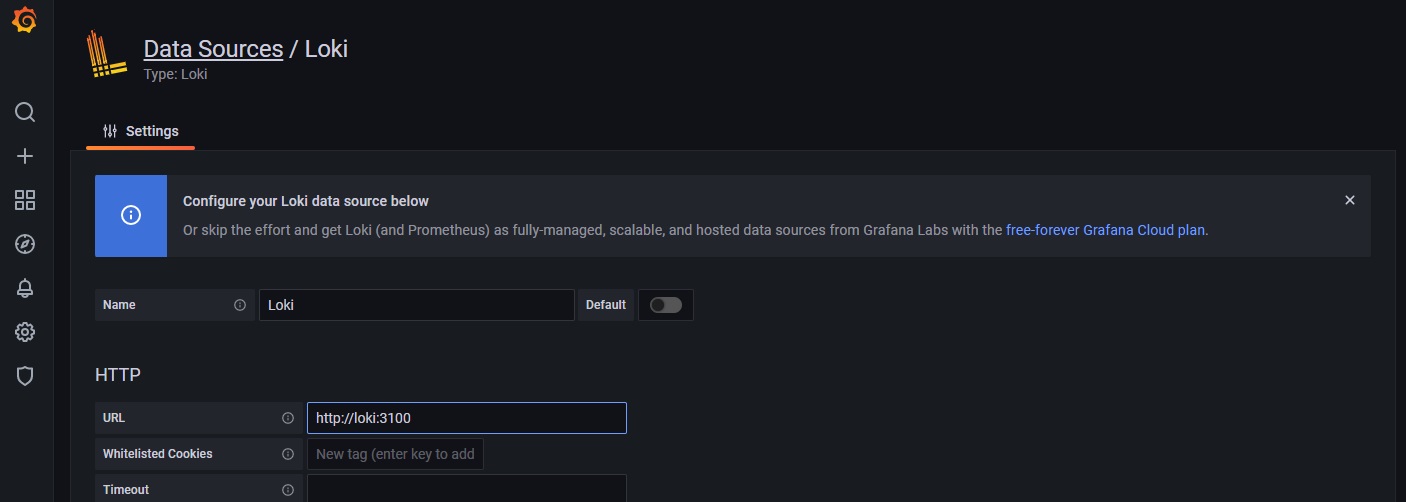
(2) アプリケーションでログを出力
3.3で用意したアプリケーションにログ出力を追加します。
ログ出力処理の追加部分を抜粋
type logJson struct {
Level string `json:"level"`
Dt string `json:"dt"`
Id string `json:"id"`
Url string `json:"url"`
Method string `json:"method"`
Message string `json:"message"`
}
func handler(w http.ResponseWriter, r *http.Request) {
fmt.Println(logStr(&logJson{Level: "INFO", Id: "1234-56789", Dt: fmt.Sprint(time.Now()), Url: "http://localhost:18080/", Method: "handler", Message: "start handler"}))
m := httpReqs.WithLabelValues("200", "GET")
m.Inc()
fmt.Fprint(w, string("hello world"))
fmt.Println(logStr(&logJson{Level: "INFO", Id: "1234-56789", Dt: fmt.Sprint(time.Now()), Url: "http://localhost:18080/", Method: "handler", Message: "start handler"}))
}
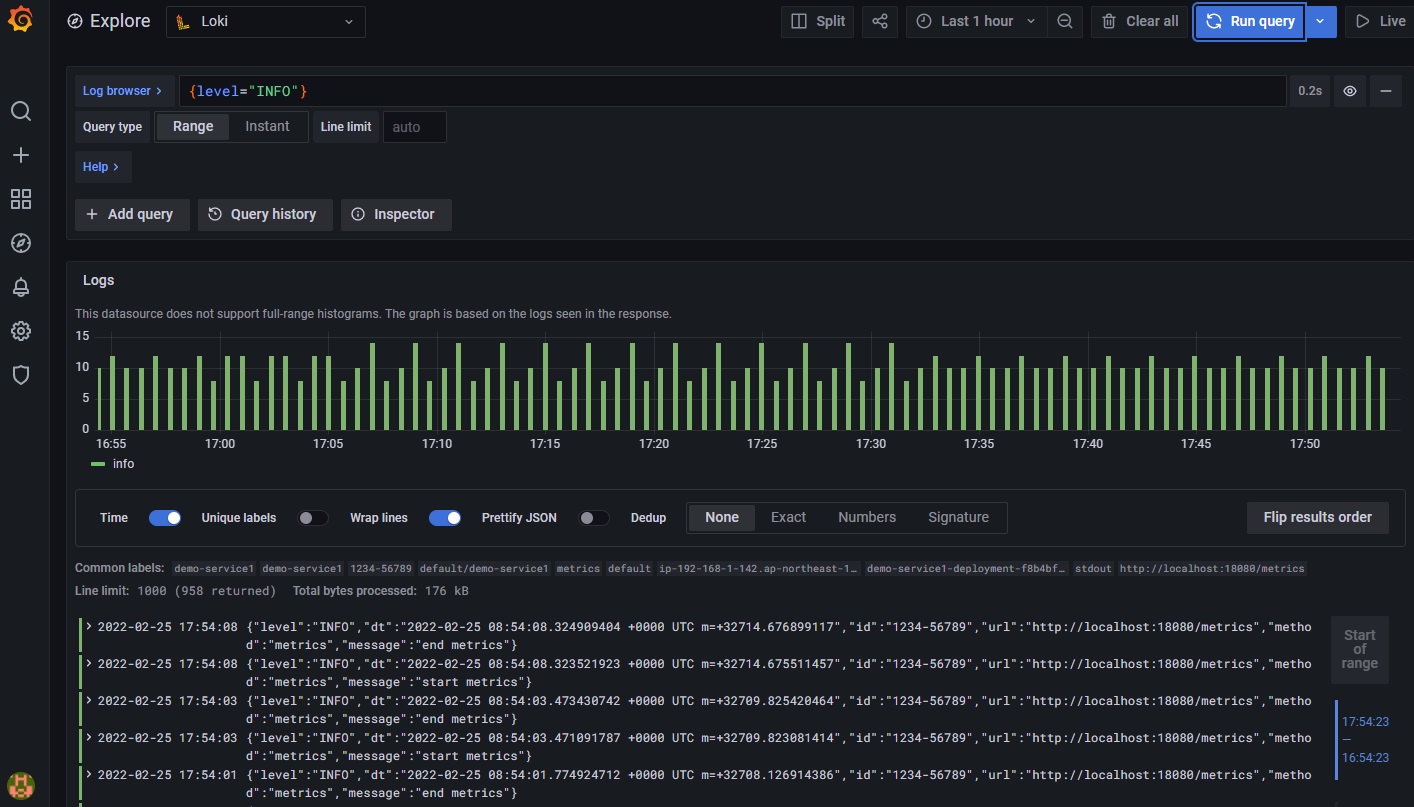
(3) Grafanaで確認
4.2のPromtail導入時にlevel、dt、url、methodのラベルを定義しているのでラベル指定でログ出力してみます。
例)levelがINFOとなっているログを表示
{level="INFO"}
5. アラート
最後にモニタリング結果やログの内容からアラートを生成します。CPUを使いすぎたり、エラーログを出力した際に検知することが目的になります。
5.1 アーキテクチャ
Prometheusで収集したメトリクスをアラートルールに基づいてAlertManagerへ連携します。AlertManagerから各ツール(Slack、メール等)に連携する仕組みになります。AlertManagerはアラートの一覧確認や一時的な抑制などを行うためのツールになります。
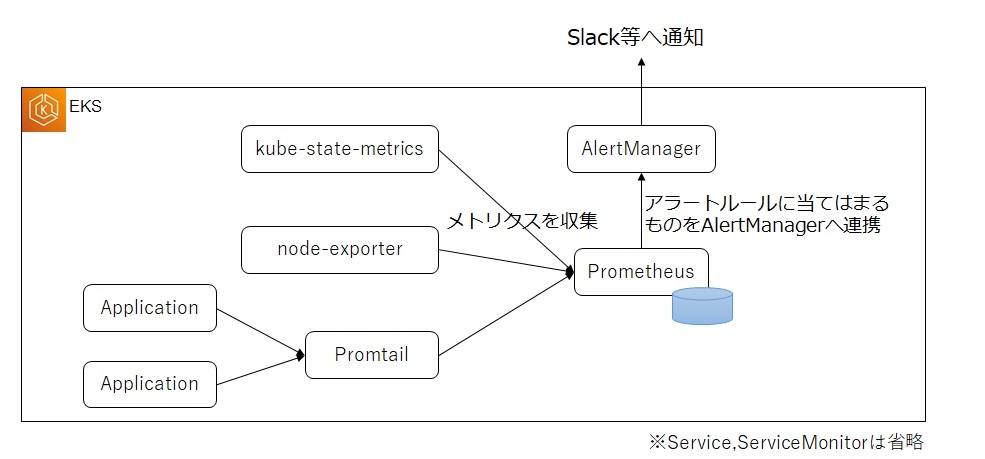
5.2 アラート対象のモニタリング
アラート対象として、エラーログが出力された際にSlackへ通知する例を作成します。エラーログのモニタリング例は4.2のPromtail導入時に設定したHelmの下記設定値部分になります。 この記述ではlevel=ERRORのログが出力された際にカウントを取り、それをPrometheusへメトリクスとして出力しています。(メトリクスはprefixとメトリクス名をつなげた名前で出力されるため、この例ではpromtail_custom_log_error_totalとなります)
- metrics:
log_error_total:
type: Counter
description: error number
prefix: promtail_custom_
source: level
config:
value: ERROR
action: inc
次に上記メトリクス結果をアラートとして認識するようにアラートルールを設定します。この例では1分間にエラーが1つ以上出力されたら「severity: critical」ラベルを付与したアラートを作成します。
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: demo-alert-rules
namespace: monitoring
labels:
app: kube-prometheus-stack
release: prometheus-operator
spec:
groups:
- name: rules-demo-alert
rules:
- alert: ApplicationError
expr: >-
count (promtail_custom_log_error_total) > 0
for: 1m
labels:
severity: critical
annotations:
message: >-
{{ $labels.job }}/{{ $labels.service }} targets in {{ $labels.namespace }} namespace are application error.
5.3 AlertManager設定
AlertMangerでは主にreceivers句とroute句を設定します。receivers句ではアラートの送信先に関する設定を定義し、route句ではどの条件の場合にどのレシーバに流すかを定義します。
今回の例ではroute句で「severity: critical」ラベルのついた通知をslack_notificationsレシーバへ送信するように設定しているため、「severity: critical」ラベルのついたアラートはSlackへ通知されます。なお、Slackへの通知はSlack側にIncoming Webhookを導入しておく必要があります。
apiVersion: v1
kind: Secret
metadata:
labels:
alertmanager: main
app.kubernetes.io/component: alert-router
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.22.2
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
"global":
"resolve_timeout": "5m"
"slack_api_url": "<slack_webhook_url>"
"receivers":
- "name": "Default"
- "name": "slack_notifications"
"slack_configs":
- "channel": "#<チャンネル名>"
"send_resolved": true
"route":
"group_by":
- "namespace"
"group_interval": "5m"
"group_wait": "30s"
"receiver": "Default"
"repeat_interval": "12h"
"routes":
- "match":
"severity": "critical"
"receiver": "slack_notifications"
type: Opaque
これで、エラーログが出力されるとSlackへ通知が行われるようになります。
6. AWSマネージドサービスの利用
ここまでKubernetes内に必要なリソースをすべて作成してきましたが、一部マネージドサービスを利用してみたいと思います。永続データなどステートフルな情報をKubernetesではなくマネージドサービスで管理したい場合に利用できるアーキテクチャになります。
6.1 GrafanaLokiのデータ格納先をS3にする
GrafanaLokiのデータをS3で永続化するように設定を変更します。格納先をS3にすることで高可用性の担保ができるほか、バックアップやデータのライフサイクル等をマネージド管理にすることが可能になります。
それでは、4.2で導入したLokiのアプリケーションファイルを変更して、S3に格納するようにします。設定は公式サイトの例を参考にしています。
extraArgs:
target: all,table-manager
replicas: 1
persistence:
enabled: true
config:
schema_config:
configs:
- from: 2020-05-15
store: aws
object_store: s3
schema: v11
index:
prefix: loki_
storage_config:
aws:
s3: s3://ap-northeast-1/<バケット名>
dynamodb:
dynamodb_url: dynamodb://ap-northeast-1
EKS上のコンテナからS3やDynamoDBにアクセスする必要がありますので、適切な権限設定が必要になります。必要な権限は公式ドキュメントに記載があります。
なお、こちらのIssueに記載がありますが、ドキュメント通りの設定だけではDynamoDBのテーブルが作られず、公式ドキュメントの設定に加え下記追加の設定をしていますのでご注意ください。
extraArgs:
target: all,table-manager
6.2 その他マネージドサービスの利用
今回はGrafanaLokiのデータをS3で永続化しましたが、その他にもAWSではPrometheusやGrafanaのマネージドサービスもあります。これらもコスト見合いにはなるとは思いますが、インフラの可用性等でマネージドサービスの恩恵を受けるメリットがありますので、要件によっては利用してみてはいかがでしょうか。
7. おわりに
Kubernetes関連として、ここまで全5回でIaCによるインフラやCI/CD環境構築、開発用ツールの紹介、分散アプリケーション開発、運用監視と順を追って連載してきました。また、マイクロサービスのテスト技法についても連載していますので、テスト技法について知りたい方はご覧いただければと思います。
連載はこれで一区切りですが、これまで連載を通してKubernetesや周辺のエコシステムを検証していて、便利なところだけではなく、使いにくいと感じたことやこれからの成長に期待したいところなどもありました。次回はこれまでの内容を振り返り、実際に使ってみて良かった点や課題に感じている点などを記事にしてみたいと思います。