

デジタルトランスフォーメーション(DX)の推進に伴って人工知能(AI)の活用が拡大しています。IT人材にとってAIに関する知識や理論は必須になりつつあります。本稿では、Teachable MachineというAIモデル開発のプラットフォームを利用して「前提知識不要」かつ「無料」で体験することで、AIに関する学習を効率的に進めるための方法を紹介します。
AI開発の概要
最初に、AI開発の流れと、開発に必要な前提知識について述べます。
AI開発の流れ
AIの開発は以下のように進めます。
企画:ビジネスに沿って開発するサービスの方向性を決め、サービスに必要なモデル(何かしらの評価や判定をするもの)を設計します。
データ収集:モデルの学習に必要なデータを収集します。
モデル開発:収集したデータを使って、モデルの学習を行います。
モデル検証:開発したモデルの精度を検証します。
公開:開発したモデルをアプリケーションへ組み込み、利用可能な状態にします。
この内、モデル開発ではディープラーニングの仕組みなど知っておくべき理論が多数あり、すべて理解するには多くの前提知識が必要となります。
モデル開発に必要な前提知識
筆者は『ゼロから作るDeep Learning』(斎藤康毅 著)という書籍(通称「カサゴ本」)でモデル開発の理論について学びました。わかりやすい説明に加えて実際にプログラムを書いて動かしてみることで、ディープラーニングの理論を深く学ぶことができました。本書の内容を理解するにはプログラミング( Python )や数学(微分、行列、統計、確率)といった前提知識が必要となりますが、モデル開発のためのプラットフォームを利用することで、これらの前提知識がなくてもディープラーニングを体験することができます。
クラウドを利用したAI開発
本稿ではGoogle社が提供するクラウドサービスであり、機械学習モデルの開発を簡単、短時間で一通り体験することができるTeachable Machine ( https://teachablemachine.withgoogle.com ) を紹介します。本稿執筆時点では、画像認識、音声認識、姿勢認識のいずれかを選択し、ディープラーニングによるモデルの開発を行うことができます。それでは早速、先に述べたAI開発の流れに沿って開発を行います。
企画
まずは企画です。今回はあまり深く考えず、「グー」と「パー」を識別するアプリケーションを開発します。手順を簡単にするため「チョキ」は割愛します。
尚、この「企画」というフェーズは、実際のAI開発においてはビジネスを理解して、仮説・モデルを立ち上げ、仮説を立証するためのデータを効率的に収集する計画を立て、顧客の受け入れ基準の合意を行う、といった重要なフェーズであることは忘れないでください。
データ収集
Teachable Machineではデータ収集からモデル検証までを簡単に実施できます。今回のテーマであれば、およそ10分で実施できます。
プロジェクト作成
まずは画像認識モデル開発のプロジェクトを作成します。図 1はTeachable Machineのトップページの抜粋です。「画像プロジェクト」を選択して、画像認識モデルの開発画面を起動します。
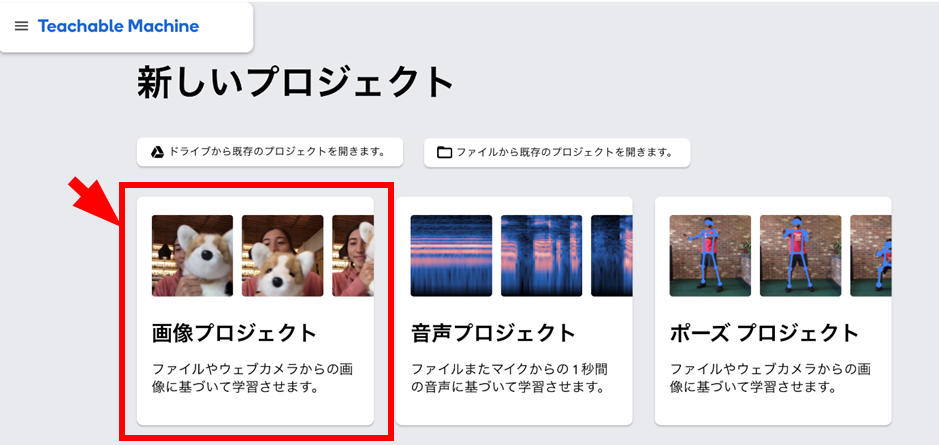
図 2は画像認識モデルの開発画面です。①データ収集、②モデル開発(トレーニング)、③モデル検証(プレビュー)という流れで画面が構成されており、この流れに沿って開発します。
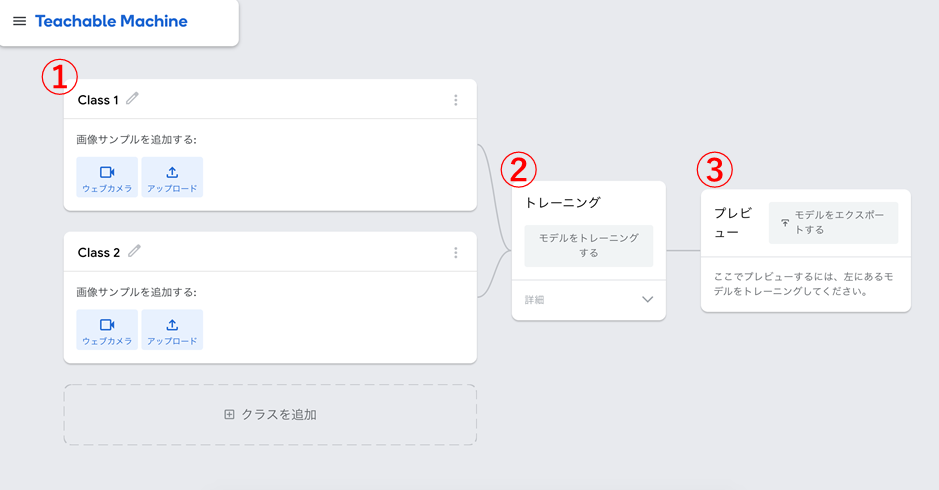
まずはグーとパーを識別するための学習用データを収集します。
PC内蔵カメラを利用したデータ収集
Teachable Machineでは、PC内蔵カメラを使って、学習用データの収集を簡単に行うことができます。「ウェブカメラ」ボタンを押すと、図 3のようにPC内蔵カメラが起動して撮影が始まります。手の向きを変えたり角度をつけたりして撮影します。
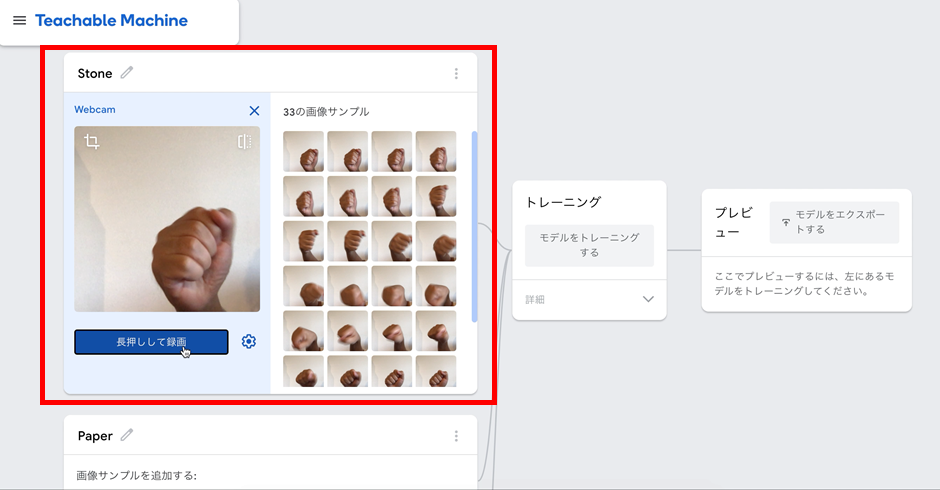
同様に、パーの画像も撮影しましょう。また、今回は グーもパーも写っていない状態の画像も撮影しています。
モデル開発
Teachable Machineでは、モデルの学習はワンクリックで完了します。図 4に示すように、「モデルをトレーニングする」ボタンを押すとディープラーニングによる学習(トレーニング)を開始します。学習は、データ数にもよりますが、1、2分で完了します。
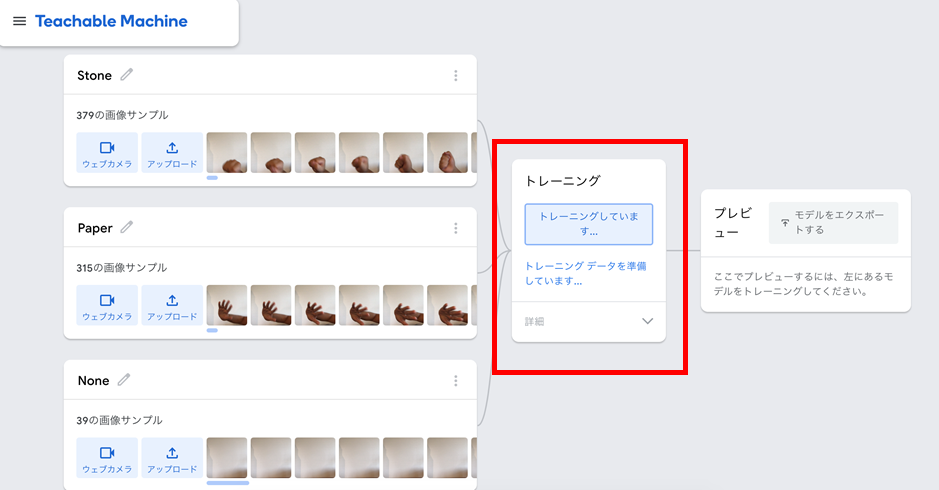
次は開発したモデルの検証を行います。
モデル検証
Teachable MachineではPC内蔵カメラを利用して検証を簡単に行うことができます。図 5のように、画面右側にカメラの映像が表示され、リアルタイムに画像認識を行い、その結果(類似度)が表示されます。
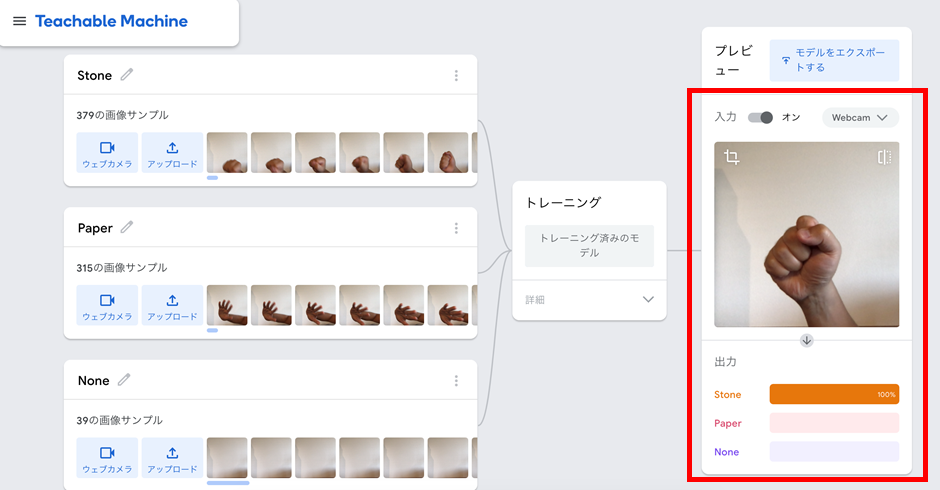
図 6のように、手の形を変えてリアルタイムにモデルの検証を行うことができます。グーとパーそれぞれの類似度は100%と表示されており、しっかり識別できています。
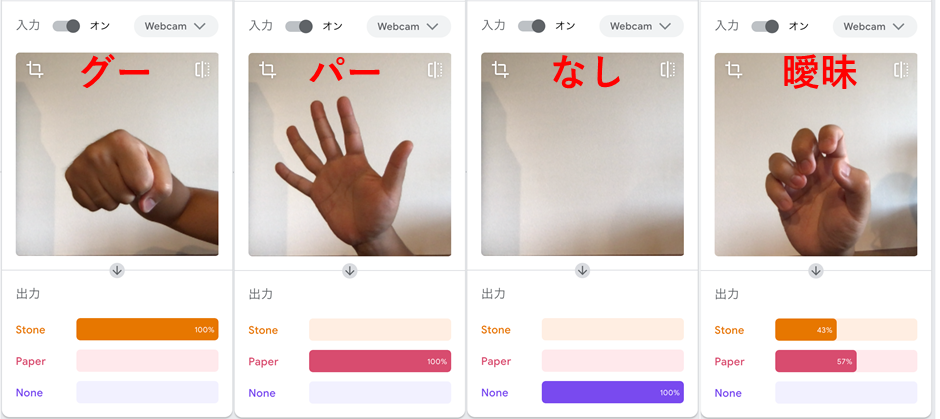
このように、Teachable Machineではプログラミングや数学といった前提知識がなくてもモデルを簡単に開発することができます。
次は、開発したモデルをアプリケーションへ組み込んで公開し、利用します。
公開
Teachable Machineで開発したモデルは、以下のいずれかの方法で利用できます。
開発したモデルをクラウド上にアップロードし、アプリケーションから呼び出して利用する
モデルをダウンロードし、アプリケーションに組み込んで利用する。
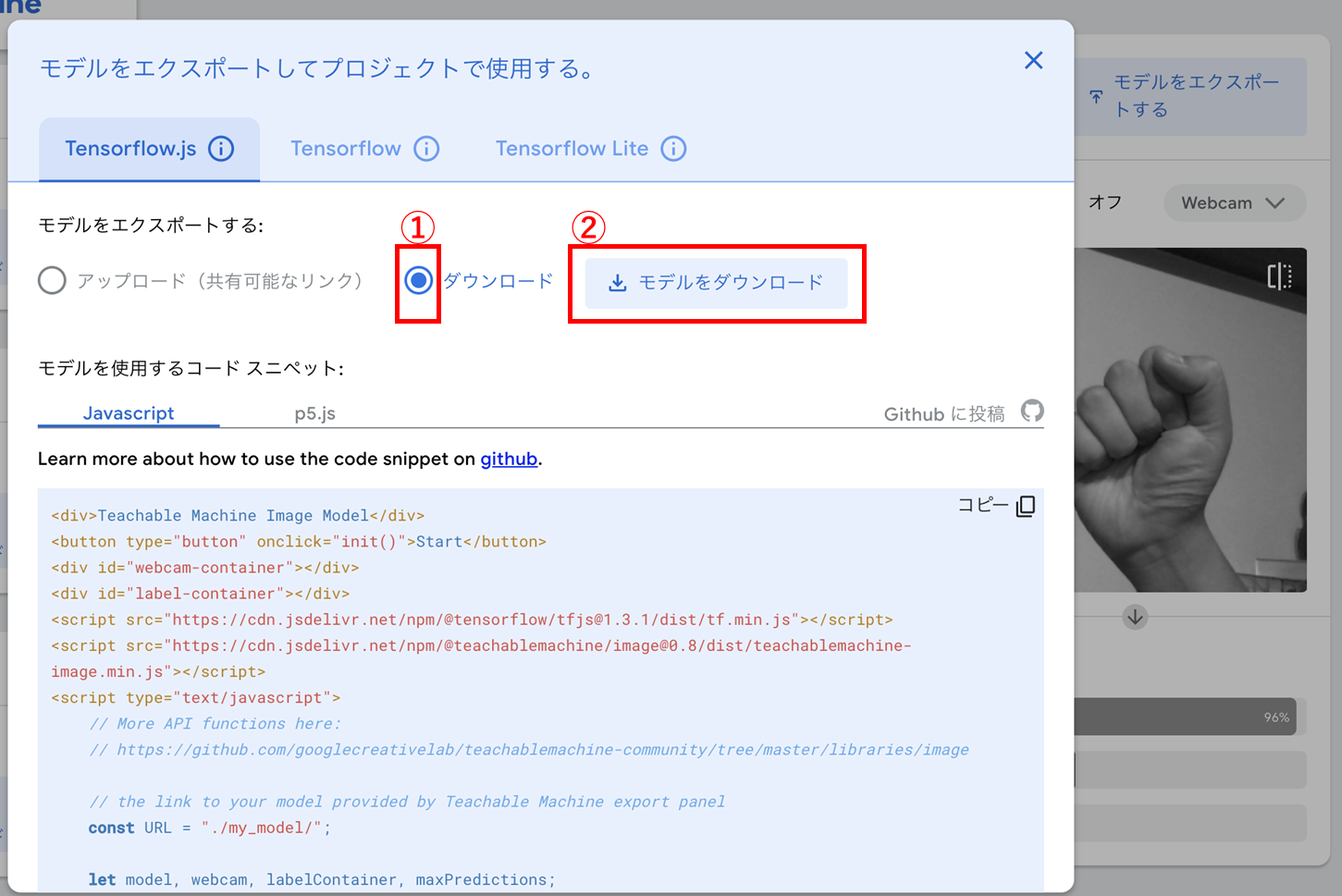
今回は、モデルをダウンロードしてアプリケーションに組み込みます。Teachable Machineでモデル学習の完了後、「モデルをエクスポートする」ボタンを押すと、図 7のような画面が表示されます。①「ダウンロード」を選択して②「モデルをダウンロード」ボタンを押し、定義ファイルをダウンロードします。定義ファイルは「metadata.json」「model.json」「weights.bin」の3つです。
また、エクスポート画面には、htmlとJavascriptのコードスニペットが表示されており、これをhtmlのbodyタグ内にはりつけるだけで画像認識アプリケーションが作成できます。今回は、index.htmlにコードスニペットをはりつけ、前段でダウンロードした定義ファイルと合わせて以下のような構成にします。定義ファイルを格納するフォルダ名は、コードスニペットの定義に合わせて「my_model」としています。
/sampleApp ├── index.html └── /my_model ├── metadata.json ├── model.json └── weights.bin
次は作成したアプリケーション一式をWebサーバに配置します。Webブラウザからindex.htmlを開き、画面に表示されているStartボタンを押すと、図 8のようにPC内蔵のカメラを利用して画像認識を行うことができます。Webサーバの構築については割愛しますが、Windowsの場合はIIS (Internet Information Services) を利用する、またはDockerを使ってローカル環境上にWebサーバを構築する、といった方法が簡単です。

以上でAI開発を一通り体験することができました。
クラウドとオープンデータを利用したAI開発
これまで述べたように、Teachable Machineでは、PC内蔵カメラを利用することでデータの収集をすぐに行うことができ、モデル開発からモデル検証までを簡単に実施することができます。しかし、実際はPC内蔵カメラだけでデータを収集するのは困難です。そんなときは、オープンデータを利用することもできます。
オープンデータとは
オープンデータとは、機械判読に適したデータ形式で、営利目的も含めて無償で二次利用が許諾され公開されているデータです。様々な企業や機関がデータを公開しており、無償で利用できます。
試しに、オックスフォード大学が公開している犬や猫の画像のオープンデータ( https://www.robots.ox.ac.uk/~vgg/data/pets/ ) を利用して、犬と猫を識別する画像認識モデルを開発します。
オープンデータを利用したモデル学習
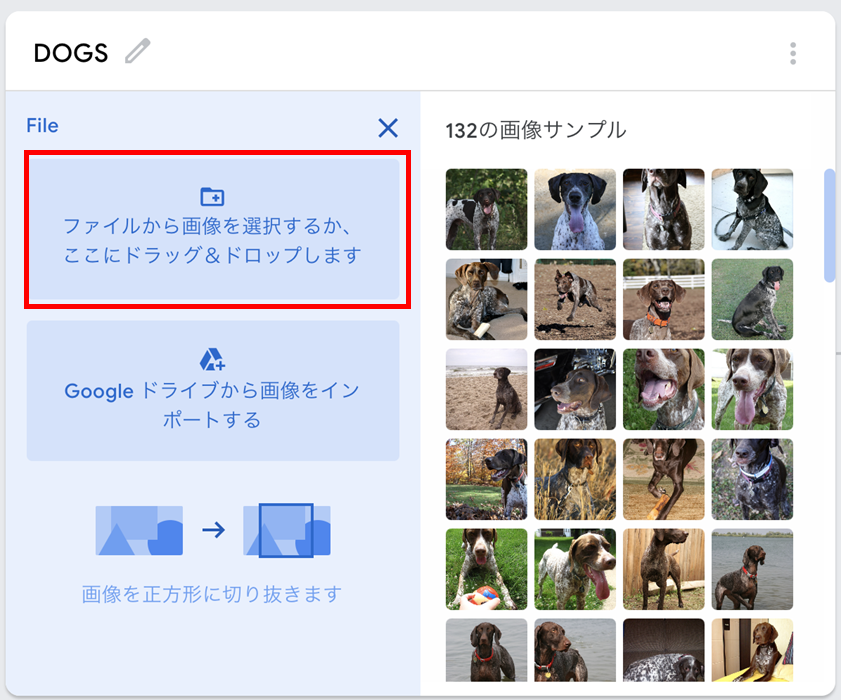
オックスフォード大学のオープンデータでは、様々な種類の犬、猫が、品種毎に分類されています。今回は犬と猫で4種類、合計300〜400枚ずつの学習用データを準備しました。Teachable Machineの開発画面で「アップロード」ボタンを押すと、図 9のような画面が表示されるので、画像を選択して準備した画像データをアップロードします。犬、猫の画像がアップロード完了したら、「モデルのトレーニング」ボタンを押して学習を開始します。
オープンデータを利用したモデル検証
モデル開発と同様、画像データをアップロードしてモデルを検証することができます。モデルの学習が完了した後、図 10のように①「File」を選択して、②検証データをアップロードすると、③検証結果が表示されます。
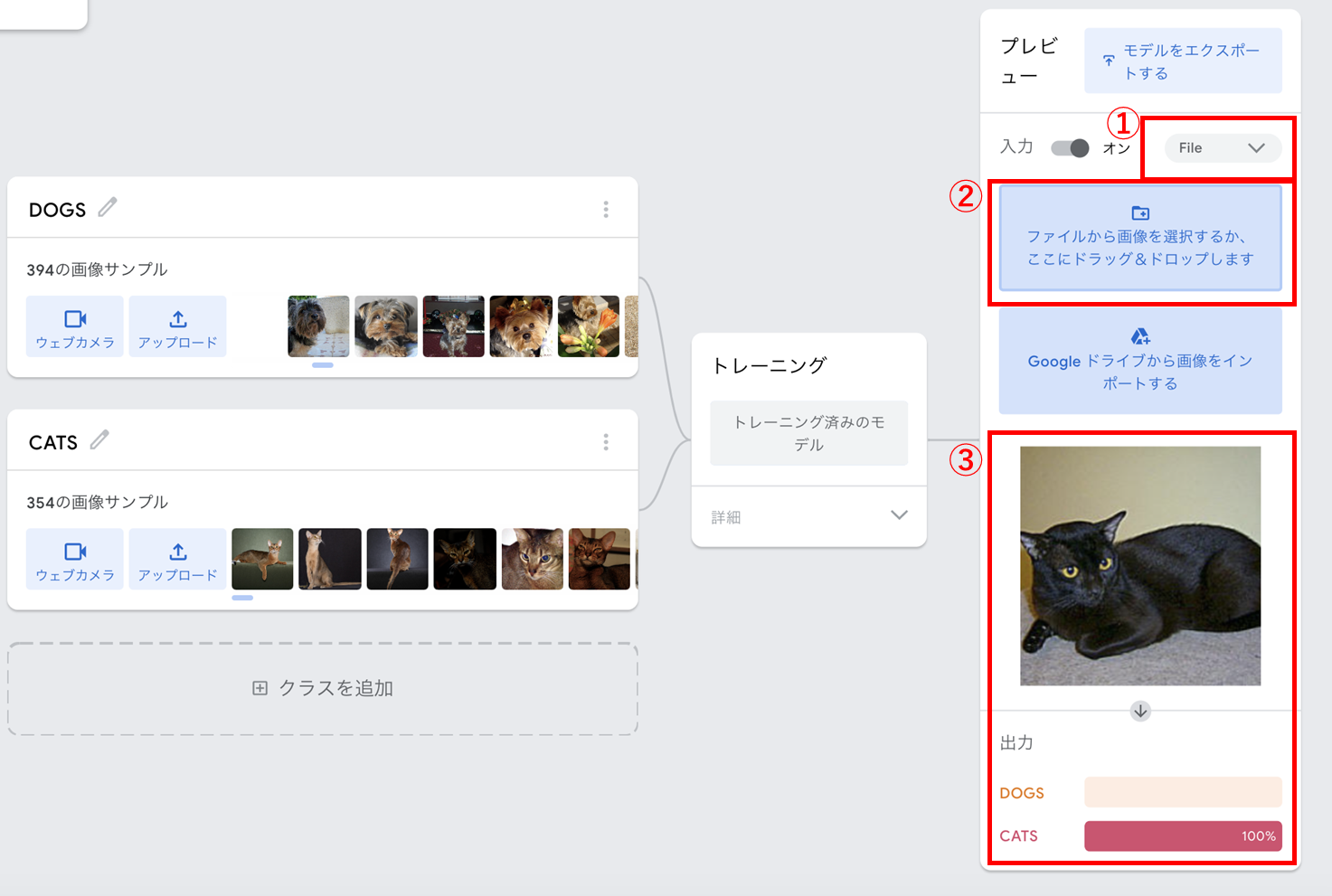
図 11のように、様々な検証データをアップロードして、開発したモデルの精度を確認します。
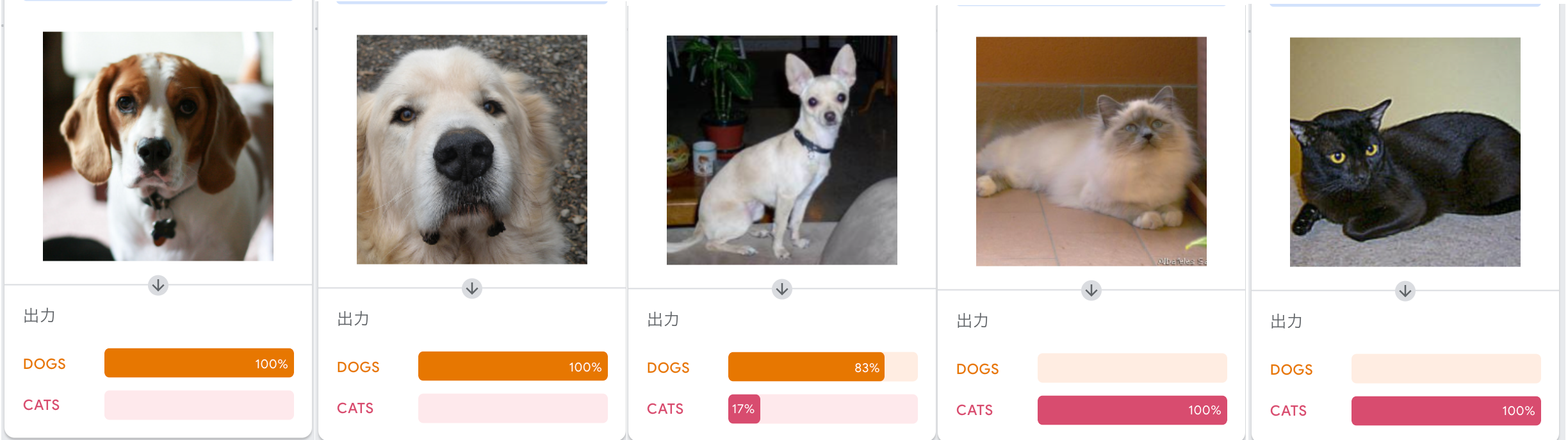
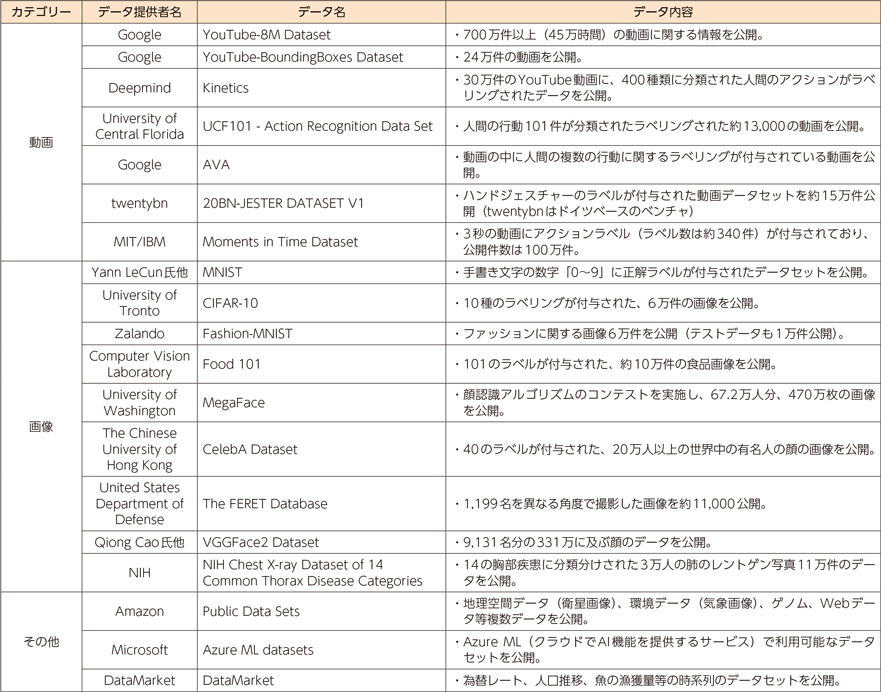
このように、オープンデータを利用すると、モデルの開発に必要なデータの収集を短時間かつ無料で実施することができます。参考まで、図 12に総務省が取りまとめたオープンデータの一覧を掲載します。
まとめ
本稿ではTeachable Machineを利用してAI開発を無料で体験できる方法を紹介しました。この方法はモデルの開発から検証までのサイクルが短く、思いついたアイディアをすぐに実装できるので、いろいろ試しながら繰り返し開発するうちに、自然とモデル開発の全体像を理解することができます。AIモデルの開発についてもっと深く知りたくなったら、書籍『ゼロから作るDeep Learning』で理論や仕組みについて学習してみてください。
出典リンク
斎藤康毅(2016).『ゼロから作るDeep Learning』 オライリージャパン
総務省|令和元年版 情報通信白書|2020年9月10日閲覧 https://www.soumu.go.jp/johotsusintokei/whitepaper/r01.html
Google社|Teachable Machine|2020年9月10日閲覧 https://teachablemachine.withgoogle.com
変更履歴:本文を一部修正しました(2021.07.15)