

DX (デジタルトランスフォーメーション) の推進によってデータ活用が進み、多くの企業が機械学習によるデータ分析によって得た知見を元にビジネス上の意思決定を行うようになりました。一方で機械学習の専門家の不足によってデータ活用が進まないという問題も起き、それを打開する技術として、機械学習の専門家の作業を自動化するAutoML ( Automated Machine Learning ) が生まれました。2012年にHarvard Business Review誌によって「21世紀で最もセクシーな仕事」とされたデータ分析は、AutoMLによって一部の専門家だけで行う仕事ではなくなり、2021年では「普通の仕事」となりつつあります。本稿では、AutoMLについて概要を述べつつ、AutoMLによるデータ分析の自動化について紹介します。
AutoMLとは
AutoMLの概要
AutoMLとは、Automated Machine Learningの略であり、「機械学習の自動化」と訳されます。機械学習のモデル開発作業を自動化する技術であり、データの前処理、モデリングといった機械学習の専門家が行っていた作業を自動化し、開発にかかるコスト削減や期間短縮を可能にします。
AutoMLによる自動化の範囲
データ分析において、AutoMLが自動化する範囲について説明します。
データ分析とは大量のデータを元に、人工知能 ( AI ) や統計学的手法を用いた分析により知識(知見・インサイト)を得るための一連の活動を指します。この活動は、CRISP-DM ( Cross-industry standard process for data mining )という一連のフェーズ(図 1)によって実施することが一般的です。
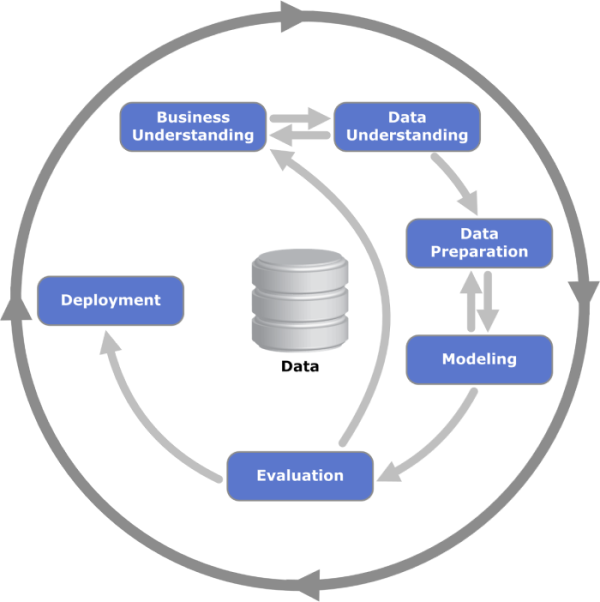
CRISP-DMにおける各フェーズについて説明します。
Business Understanding(ビジネス理解)
- ビジネス課題を理解して、データ分析の目的や目標を設定します。
Data Understanding(データ理解)
- 今あるデータが目標達成に十分な内容かどうかを吟味します。データ項目や量、品質を確認して、データ分析に利用できるかどうかを判断します。
Data Preparation(データ準備)
- データを分析に適したデータに整形します。
Modeling(モデリング)
- 予測モデルを作成します。
Evaluation(評価)
- 作成したモデルでビジネス目標を達成できるか評価します。
Deployment(展開)
- 作成したモデルを展開して利用可能な状態とします。データ分析の結果を元にビジネス課題の解決に向けたアクションを行います。
AutoMLは、 CRISP-DMのすべてのフェーズに寄与します。「データ準備」、「モデリング」、「評価」、「展開」で行うタスクの自動化によりデータアナリストの負担を減らして各種分析に集中できるようにすることで「ビジネス理解」と「データ理解」に貢献します。
AutoMLのツール
AutoMLによるデータ分析は、機械学習プラットフォームの利用、もしくはオープンソース ( OSS ) のライブラリの利用によって行います。機械学習プラットフォームは、直感的に操作ができるユーザインターフェースによって、だれでも容易にデータ分析を実施できます。代表的なプラットフォームを以下に列挙します。
DataRobot ( https://www.datarobot.com/jp/ )
Cloud AutoML ( https://cloud.google.com/automl?hl=ja )
Microsoft Azure Machine Learning ( https://azure.microsoft.com/ja-jp/services/machine-learning/automatedml/ )
これに対してAutoMLのOSSライブラリは、ローコードで容易に、かつ無償でデータ分析を実施できます。代表的なライブラリを以下に列挙します。
AutoKeras ( https://autokeras.com )
Auto-sklearn ( https://automl.github.io/auto-sklearn/master/ )
PyCaret ( https://pycaret.org )
PyCaretによるデータ分析
本稿では、AutoMLのOSSライブラリであるPyCaretを使ったデータ分析の自動化について紹介します。
PyCaretとは
PyCaretは、ローコードで機械学習を行うためのPythonのライブラリです。Jupyter Notebookなどのノートブック環境上で、データの準備から展開までを数分で実行することができます。PyCaretのインストール方法については、公式ページ ( https://pycaret.org/install/ ) を参照してください。Google ColaboratoryやKaggleのノートブック環境でも利用可能です。
それでは前述したCRISP-DMの一連のフェーズに沿って、Jupyter Notebook上でPyCaretによるデータ分析を実践します。
フェーズ1:ビジネス理解
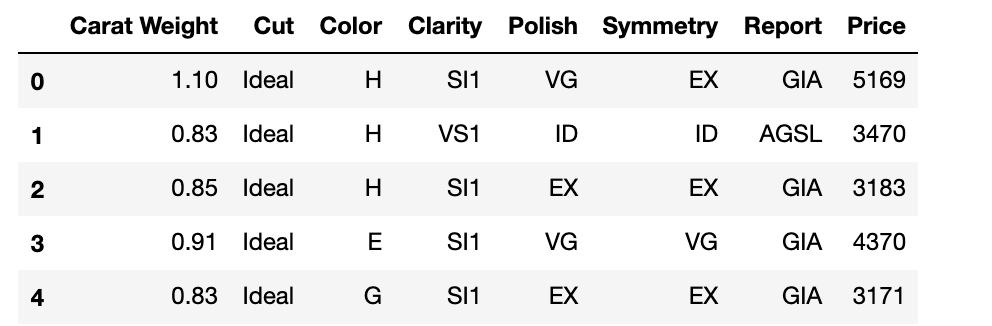
本稿では、"Sarah Gets a Diamond"と呼ばれるケーススタディでデータ分析を実践します。PyCaretにはチュートリアル用にデータセットがいくつか用意されており、本ケーススタディもその1つです。6000件のデータを元に、ダイアモンド価格の推定を行う回帰問題です。データセットにおける各変数の説明を以下に記載します。カッコ内の値は区分値を示しており、Reportを除いて一番左の記載が最も望ましい状態です。
Carat Weight: ダイアモンドの重量です。1カラットは0.2グラムに相当します。
Cut: ダイアモンドのカットの状態を示す値です。 (Signature-Ideal, Ideal, Very Good, Good, Fair)
Color: ダイアモンドの色です。 (D, E, F - Colorless, G, H, I - Near colorless)
Clarity: ダイアモンドの透明度です。 (F - Flawless, IF - Internally Flawless, VVS1 or VVS2 - Very, Very Slightly Included, or VS1 or VS2 - Very Slightly Included, SI1 - Slightly Included)
Polish: ダイアモンドのポリッシュ(研磨仕上がり状態の評価基準)です。(ID - Ideal, EX - Excellent, VG - Very Good, G - Good)
Symmetry: ダイアモンドのシンメトリー(対称性の評価基準)です。(ID - Ideal, EX - Excellent, VG - Very Good, G - Good)
Report: ダイアモンドの品質保証をした鑑定機関です。(AGSL - American Gem Society Laboratories, GIA - Gemological Institute of America)
Price: ダイアモンドの価格(米ドル)です。
以下のコマンドで、データを取得できます。実行結果を図 2に示します。
from pycaret.datasets import get_data
dataset = get_data('diamond')
フェーズ2:データ理解
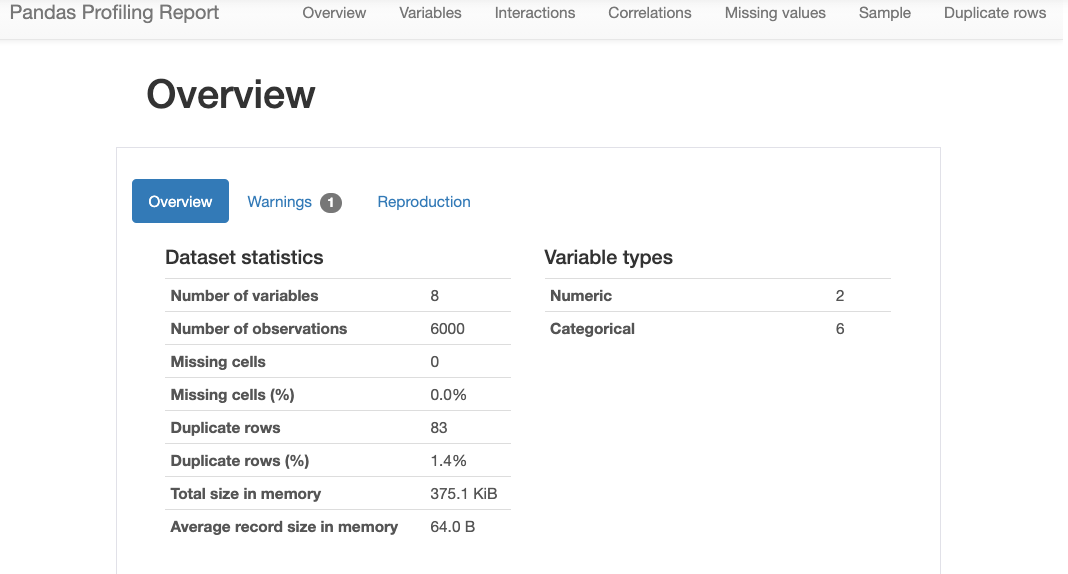
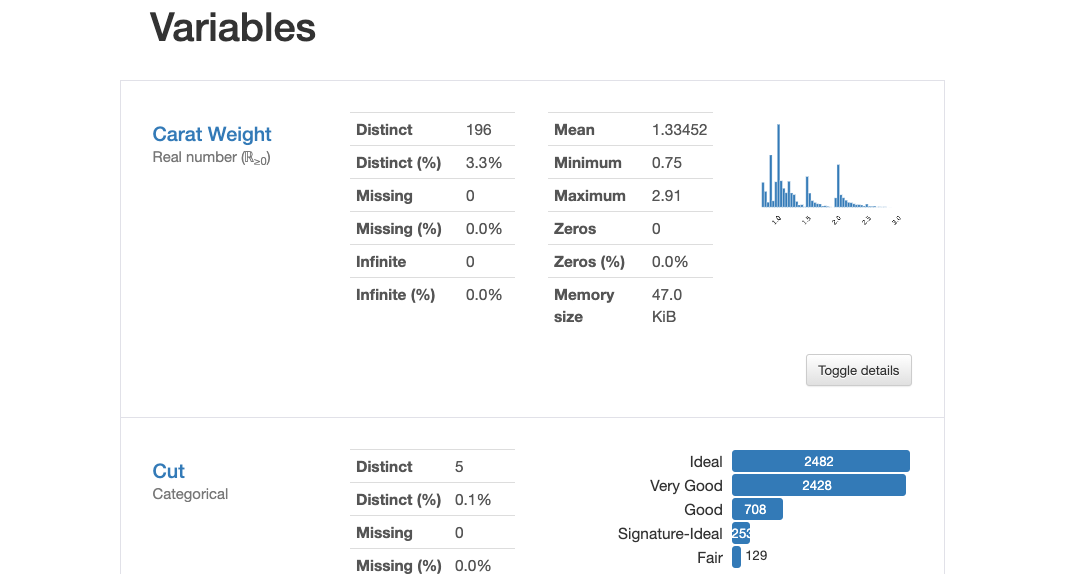
データの中身を理解するには、pandasのprofile_report()が便利です。変数の数 ( Number of variables ) やレコード数 ( Number of observations )、欠損値の有無 ( Missing cells ) や変数の型( Variable types )といったデータの概要や、変数毎の最大値 ( Maximum ) や最小値 ( Minimum ) 、平均値 ( Mean )といった情報を確認できます。
以下のコードでデータの各種情報を確認できます。実行結果を一部抜粋し、図 3、図 4に示します。
import pandas_profiling dataset.profile_report()
フェーズ3:データ準備
ホールドアウト
本稿では、取得したデータのうち1割のデータをホールドアウトとして残し、学習が完了した予測モデルのパフォーマンス検証に利用します。以下のコードにより、取得したデータを分割して学習・検定に利用する5400件のデータと600件のホールドアウトデータに分割します。
data = dataset.sample(frac=0.9, random_state=786).reset_index(drop=True) data_unseen = dataset.drop(data.index).reset_index(drop=True)
データの前処理
次に学習・検定用データの前処理を行います。データの前処理とは、機械学習アルゴリズムによる学習を可能とするために、用意したデータに対してデータの欠損値の処理や、OneHot Encodingなどのカテゴリ変数エンコーディングといった処理を行います。この前処理からPyCaretが活躍します。
以下のコードで、データの前処理を実行できます。回帰 ( regression ) 問題なので、pycaret.regressionモジュールを参照します。setup()の引数には、学習用データと目的変数であるPriceを指定します。コードの実行結果を、図 5に示します。
from pycaret.regression import * setup(data = data, target = 'Price')
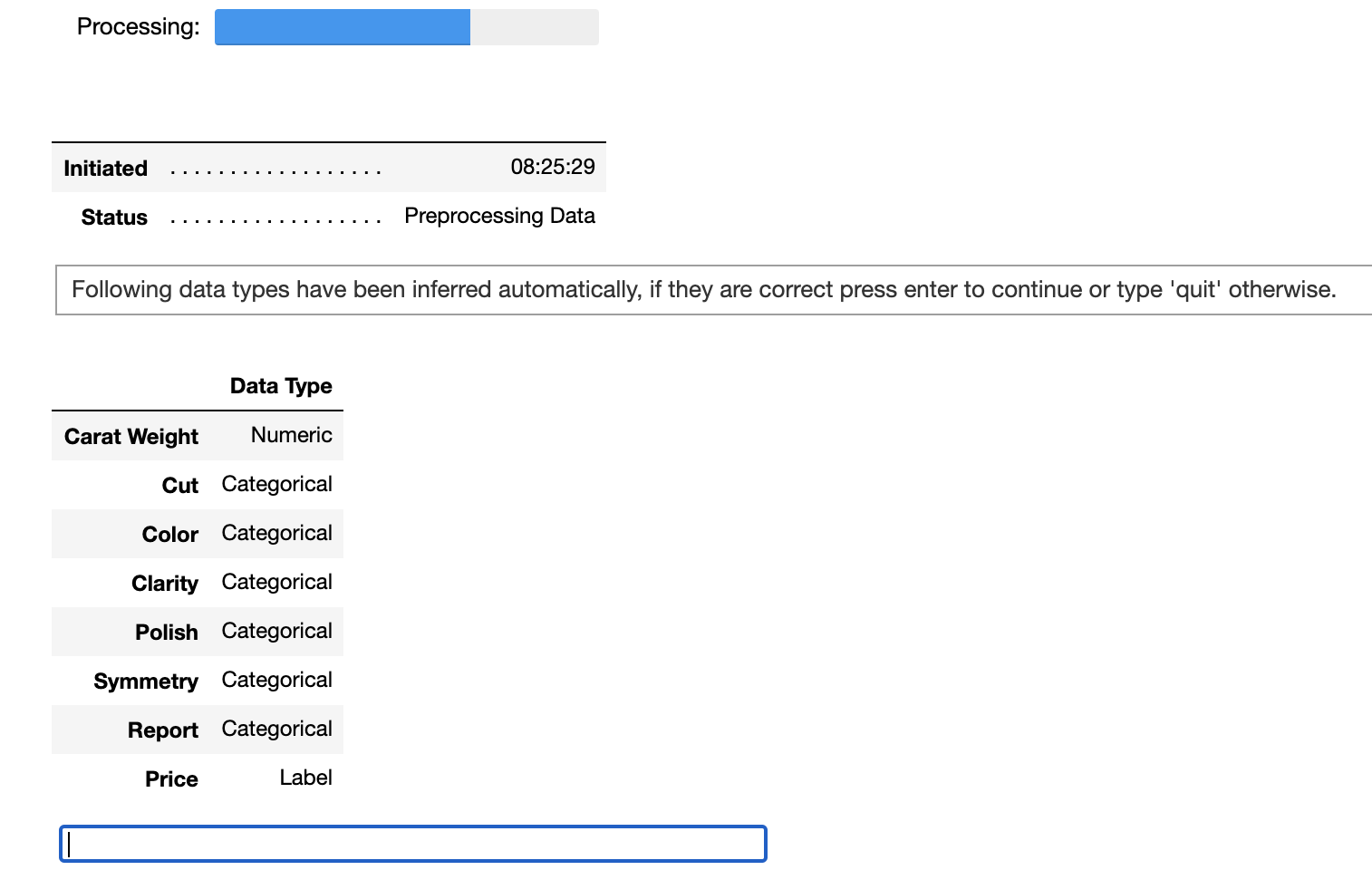
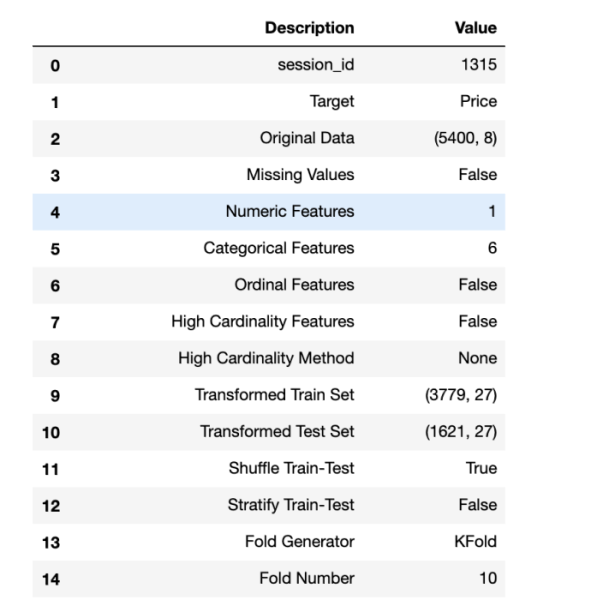
PyCaretはデータ内容から各項目の型を自動で推定し、妥当かどうかをユーザに確認します。推定された結果に問題がなければ、下部の青枠ボックス上でEnterキーを押下してください。前処理が続行します。図 6は前処理の実施結果です。欠損値の処理の有無 ( Missing Values )、5400件のデータをモデルの学習用と検定用に分割したデータのサイズ ( Transformed Train Set, Transformed Test Set )、予測モデルの妥当性確認をする際の交差検証の種類 ( Fold Generator ) やデータ分割数 ( Fold Number) といった情報が表示されます。項目数が多いため、一部のみ抜粋して掲載しています。
これで、データの準備が完了です。数行のコードを書いて実行するだけでデータの前処理が完了しました。
フェーズ4:モデリング
機械学習アルゴリズムの選定
次にダイアモンド価格の予測モデルを作成します。モデリングのための機械学習アルゴリズムは多数あり、ビジネス課題の内容や収集したデータの規模などの状態に応じて、優れたパフォーマンスを示すアルゴリズムを選定します。アルゴリズムの選定には、scikit-learnの機械学習アルゴリズム選択のチートシート(図 7)が役立ちます。
AutoMLでは、主要な機械学習アルゴリズムがライブラリとして用意されていて、複数のアルゴリズムを元に網羅的に予測モデルを作成してパフォーマンスを比較する、いわゆるスクリーニングのアプローチで課題に対して最も優れたパフォーマンスを示すアルゴリズムを選定します。以下のコードを実行すると、前処理済の訓練データ ( Transformed Train Set ) によるk分割交差検証( k=10 ) により、PyCaretに用意されているすべての機械学習アルゴリズムのパフォーマンスを算出して比較できます。実行結果を図 8に示します。
compare_models()
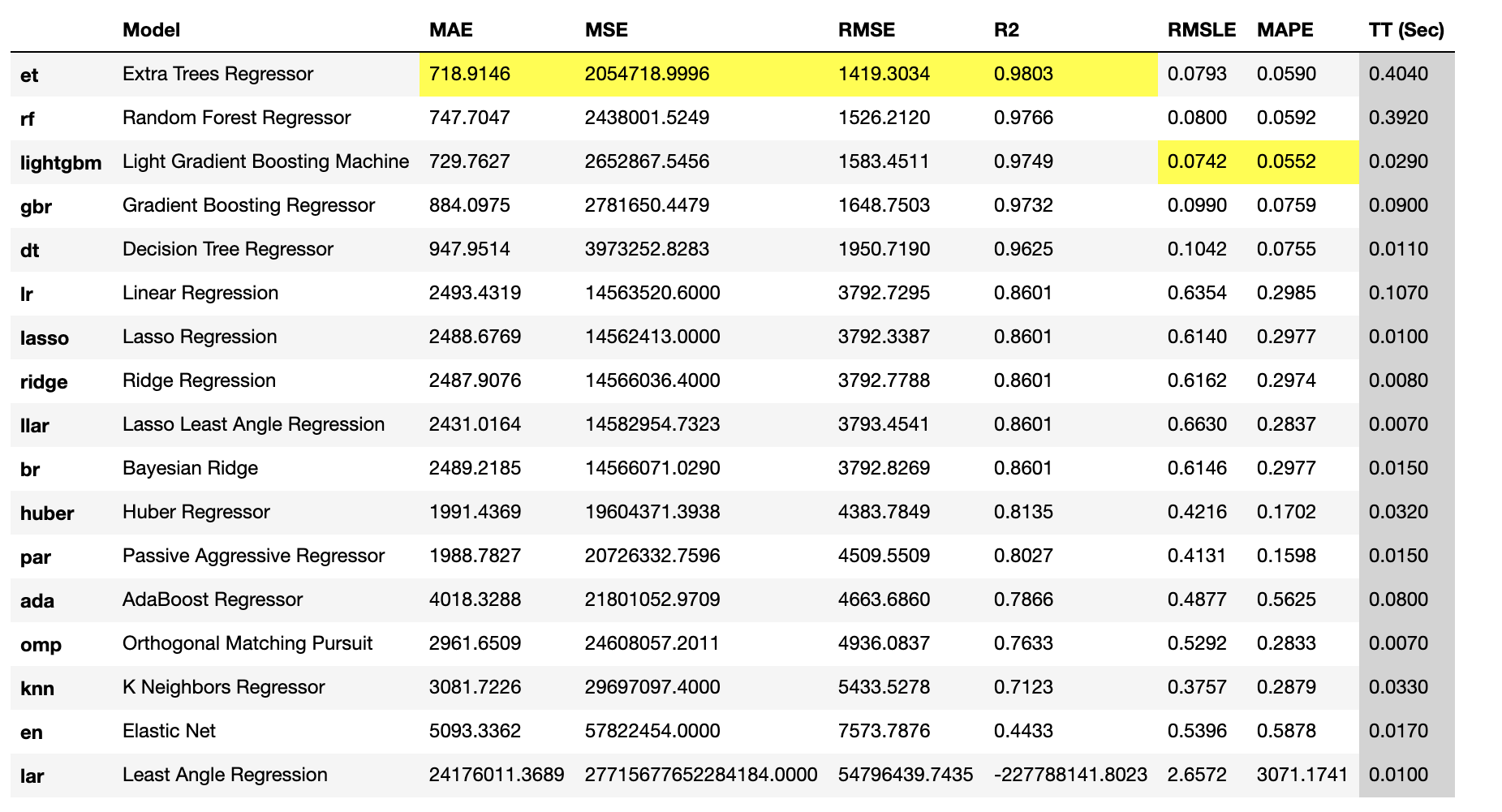
回帰分析の評価指標となる各種誤差( MAE、MSE、RMSE、RMSLE、MAPE )や決定係数 ( R2 ) がアルゴリズム毎に自動計算されています。指標毎に最も優れた値が、見るべき箇所として黄色で表示されます。今回は、各評価指標で最も優れた値を算出したExtra Trees Regressor ( et ) とLight Gradient Boosting Machine ( lightgbm ) の2つの機械学習アルゴリズムで予測モデルを作成し、後述するチューニング後の検証においてパフォーマンスが良い方を採用します。
モデル作成
以下のコードで、デフォルトのハイパーパラメータセットによるモデル作成を実行します。実行結果を図 9、図 10に示します。k分割交差検証( k=10 ) の結果が表示されます。
et = create_model('et')
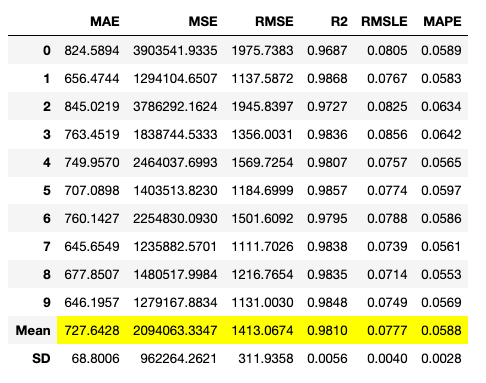
lightgbm = create_model('lightgbm')
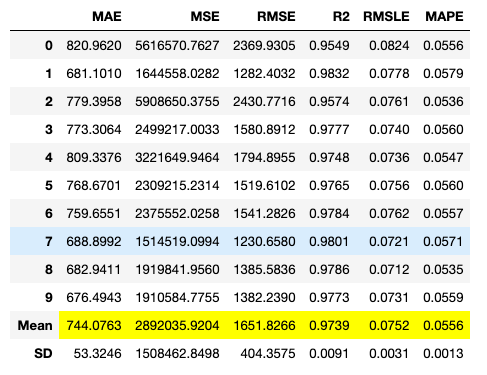
チューニング
次に、作成した予測モデルをチューニングします。
PyCaretではランダムグリッドサーチによって適切なハイパーパラメータを自動探索してチューニングを行います。コードの実行結果を図 11、図 12に示します。
tuned_et = tune_model(et)
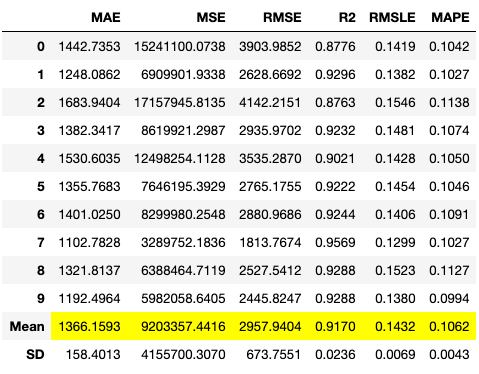
tuned_lightgbm = tune_model(lightgbm)
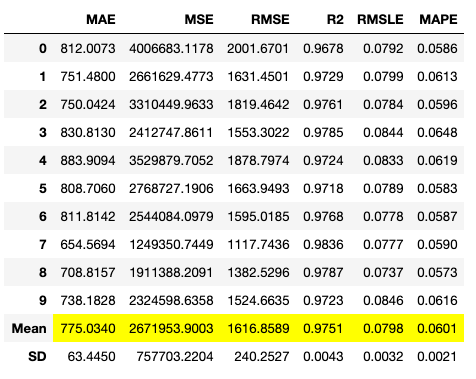
チューニング後の決定係数 ( R2 )をみると、et は0.9810から0.9170とパフォーマンスが低下して、 lightgbmは0.9731から0.9751へパフォーマンスが向上しました。今回はlightgbmを選定します。
フェーズ5:評価
モデル解析
以下のコードでチューニング後の予測モデルの解析をします。予測誤差(図 13)、変数の重要度(図 14)といった様々な分析結果を確認できます。図の上部のPlotTypeから分析の種類を選択して表示することができます。
evaluate_model(tuned_lightgbm)
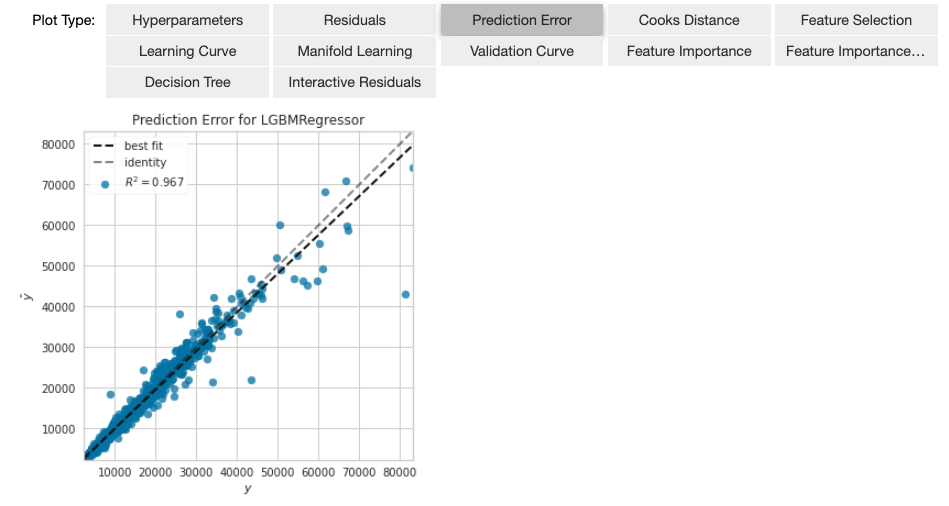
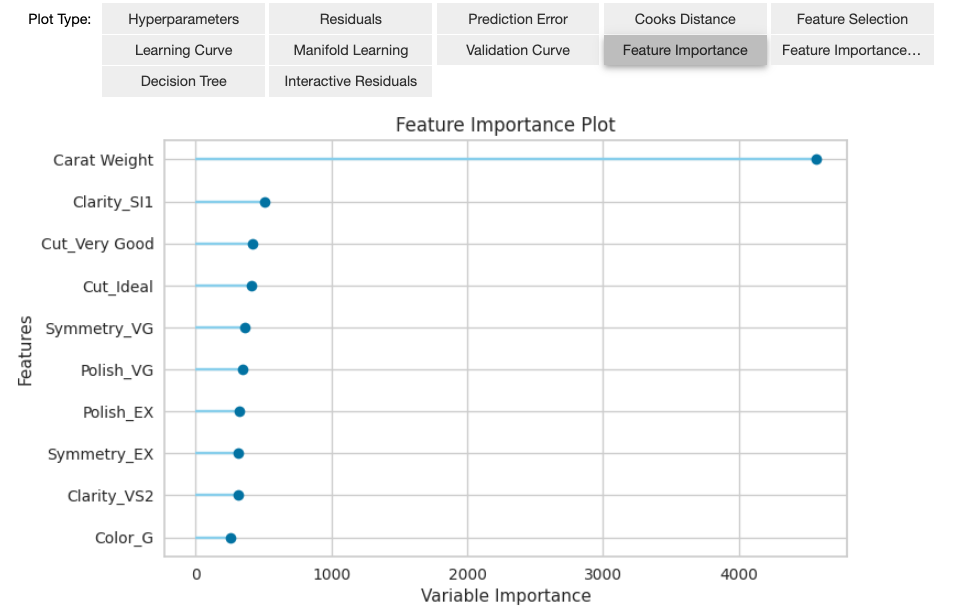
変数の重要度(図 14)の結果から、ダイアモンドの重量がダイアモンドの価格に大きく寄与することがわかります。この結果について特に違和感を覚えることはないと思います。他のビジネスケースだと意外な変数が重要であることに気づくこともあり、データアナリストのビジネス理解やデータ理解が進みます。
次に、フェーズ3での前処理済のテスト用データ( Transformed Test Set )を使って、チューニング後のモデルのパフォーマンスを測定します。以下のコードで、テストデータを使ったチューニング済モデルによる予測を実行します。図 15 に実行結果を示します。
predict_model(tuned_lightgbm)

決定係数 ( R2 )を見ると、学習時とほとんど変わらないパフォーマンスで予測ができていたので、前処理済の全データ(学習用データとテスト用データ)を使って学習を行い、予測モデルを完成させます。この作業は、ファイナライズと呼ばれます。
ファイナライズ
以下のコードにより、ファイナライズを実行します。これで予測モデルが完成しました。
final_lightgbm = finalize_model(tuned_lightgbm)
最後に、ホールドアウトデータを使って完成したモデルのパフォーマンスを検証します。
以下のコードにより予測を行います。データ準備の段階でホールドアウトとして残した1割のデータ ( data_unseen ) に対して予測を実施することで、未知のデータに対する予測を行い、その結果からパフォーマンスを検証できます。図 16にコードの実行結果を示します。
predict_model(final_lightgbm, data=data_unseen)
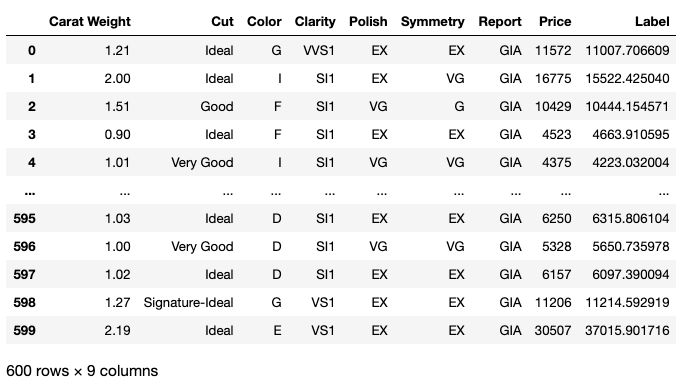
モデルが予測したダイアモンドの価格は「Label」に表示されています。ダイアモンド価格の正解データ ( Price ) を用いて決定係数 ( R2 ) を算出すると0.9919 でした。高パフォーマンスのモデルが作成できています。
フェーズ6:展開
以下のコードにより、予測モデルをpickleファイルとしてローカルに保存できます。
save_model(final_lightgbm,'Final_Lightgbm_Model_20210301')
また、以下のコードによって保存したモデルを読み込むことができ、アプリケーションなどで利用することができます。
saved_final_lightgbm = load_model('Final_Lightgbm_Model_20210301')
以上で、CRISP-DMの一連のフェーズを実施できました。
おわりに
本稿ではAutoMLのツールの1つであるPyCaretを利用して、CRISP-DMに準じたデータ分析を実践しました。データの前処理や機械学習アルゴリズムの選定、モデルの学習や検証といったタスクを1、2行のコードを記載するだけで実行することができ、データアナリストの作業効率の大幅な向上が期待できます。しかし、裏を返せば数行のコードを書いて実行する必要があり、プログラミングの知識がない人は敷居が高いと感じるでしょう。企業のあらゆる人材がデータ活用を行うためには、直感的に操作ができる優れたユーザインターフェースが必要であり、機械学習プラットフォームの導入を推奨します。
筆者は有償の機械学習プラットフォームをトライアルで利用してみましたが、先進的で非常に使いやすく、PyCaretよりも容易にデータ分析を実施できました。PyCaretによるデータ分析を実践してみて、もしAutoMLに興味を持たれたなら、機械学習プラットフォームをトライアルすることをお勧めします。
参考リンク
“Data Scientist: The Sexiest Job of the 21st Century” Thomas H. Davenport and D.J. Patil (2012) 2021年3月5日閲覧 https://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century
“Cross-industry standard process for data mining” Integral Solutions Ltd , Teradata, Daimler AG, NCR Corporation and OHRA 2021年3月1日閲覧 https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining
“Choosing the right estimator” scikit-learn.org 2021年3月1日閲覧 https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
“Light Gradient Boosting Machine” マイクロソフト 2021年3月1日閲覧 https://github.com/microsoft/LightGBM