WEBマガジン
「 BigData 第1回 ビッグデータとは 」
2013.02.12 株式会社オージス総研 明神 知
※ 本稿は、財団法人経済産業調査会発行 「特許ニュース」 No.13250 (2013 年2 月 日発行)への寄稿記事です。
1.はじめに
ビッグデータというキーワードが2011年始めごろから急速に取り上げられるようになってきました。検索キーワードの人気度を見るGoogleトレンドによると日本語の「ビッグデータ」は2008年から、英語の「Big Data」はそれより古く2004年以前から現れています。いずれも2011年から急速に検索されるようになっています。
定義も曖昧な多くのバズワードがIT業界では増産されて来ましたが、ビッグデータは、これまでのデータとは何が異なるのでしょうか?
ビッグデータは単に量が多いだけでなく、TwitterやFacebookなどのソーシャルメディアやGPS位置情報や加速度センサーといったM2M通信(Machine to Machine)など様々な種類・形式が含まれる非構造化データ・非定型的データを含み、日々膨大に生成・記録される時系列性・リアルタイム性のあるようなものまでを指します。
2010年から2011年にかけて発生した「アラブの春」やニューヨーク・ウォール街を起点とする若者や失業者を中心とする抗議活動は、各国に飛び火しました。
最近の中国における言論統制に対する反対デモは一党独裁の共産党の報道規制に対する抗議です。これらの社会現象はFacebookや中国版Twitterとされるマイクロブログ「微博(ウェイボ)」などソーシャルメディアを駆使して抗議活動を展開するところに、共通点があると言われています。ビッグデータは先進国の民主主義のあり方すら変革するパワーを持つのです。
まさに大きなうねり「グランズウェル」です。実際、MITのメディア・ラボではソーシャルメディアを駆使した「討論型世論調査」などの相互作用によって高度な秩序を目指す、代議制を超えた創発民主主義の研究を始めています。
また、消費者やユーザーという、これまで受身であった人達が、スマートフォンやモバイル・デバイスの普及によってソーシャルメディアを介して情報発信・共有することによって強大なパワーを持ち始めています。ソーシャルメディアで繋がった強く変貌した消費者に対する新しい方法でのビジネスに対応できない企業は「The End of Business As Usual[1]」として退場させられます。
「Nielsen/NetRatings」によると、2012年5月時点の我が国におけるFacebook利用者数は1272万人となり、Twitterは1482万人に達したということです。昨年夏のロンドンオリンピック期間中のツイート数は1億以上と4年前の北京オリンピックの125倍以上にもなっています。
このようにモバイル端末の普及とソーシャルメディアの活用によってビッグデータの「情報爆発」が現実化し、益々拡大しています。IDCによれば2009年時点の世界のデータ総量は80万ペタバイト、2020年には35ゼタバイトになるということです。
また、「ビッグデータ」は新しい科学のパラダイムの歴史的な転換点であるという主張も出てきました。「ビッグデータ」の分析技術である「統計数理」の日本の総本山とも言える統計数理研究所の樋口所長がよく引用して、追い風だと言われているのが「第4の科学」です。
これは、2009年10月にマイクロソフト研究所が発表した「第4パラダイム:データ集約型の科学的発見」です[2]。
この第4とは、西洋での4段階(パラダイム)の問題解決方法のことを言っており、
第1:数学的手法と経験的手法(アリストテレス~)
第2:理論構築(ライプニッツ~)
第3:シミュレーション(ジョン・フォン・ノイマン~)
第4:データ(ジム・グレイ~)
というのです。
これまでの科学的思考スタイルの王道は理論や定理に基づいた演繹的な事実や現象の解明や理解でした。ところが、基礎方程式や支配方程式もないところで大量データから関係式を近似的に作っていろいろな予測サービスが提供できる世界(帰納的推論)が生まれてきているというのです。その分野として、地球環境、医療、ライフサイエンスや生物科学、地球や宇宙の観測などにおける事例と利用できるITやインフラを紹介しています。これらは25年前ごろにAI(人工知能)で盛んに研究されたものに基礎を置くものです。当時との違いは高速(無線)インターネット網の普及とコンピュータの性能向上、高精度センサーのコモデティー化、ストレージの廉価化といった「ビッグデータ」の環境整備が整った結果、成果が出てきているのです。
筆者は、この帰納的アプローチをデータ項目辞書管理や意味管理といったメタデータ管理やMDM(マスターデータ管理)に使えないかと考えています。あまりにも膨大で発散してしまったデータ項目をトップダウン一辺倒のアプローチでは無理だからです。
このようにあらゆる分野でインパクトのある「ビッグデータ」について5回の連載の中で多面的に考えていきます。
まず第1回目の本稿では、ビッグデータの現状を踏まえ、その定義、有効性、位置づけ、課題等を中心に、次回以降で触れないビッグデータのメタデータについても解説したいと思います。
2.ビッグデータの定義
「ビッグデータ」はこれまでの情報システムが扱ってきたデータに比べ、3つの部分に違いがあります。1つめはデータ量が多いということ、2つめはデータの種類が多いということ、そして3つ目はデータの変化する頻度が高いということです。そして、これらの条件が重なることで、従来のシステムでは取り扱うことが困難であったデータ(狭義)と、それを扱うためのシステムや技術、さらにデータサイエンティストといった専門的人材や組織を含む包括的概念(広義)として「ビッグデータ」と呼んでいます。今までは管理しきれないため見過ごされてきた、そのようなデータ群を記録・保管して即座に解析することで、ビジネスや社会に有用な知見を得たり、これまでにないような新たな仕組みやシステムを産み出したりできる可能性が高まっているのです。
- 容量 (Volume)
ビッグデータの特長はその容量の巨大さです。企業内外にはデータが溢れており、数テラバイトから数ペタバイトにもおよびます。またデータが増大することによる計算量も非常に膨大となっています。 - 種類 (Variety)
ビッグデータは企業システムで通常扱っている構造化データとは限りません。テキスト、音声、ビデオ、クリックストリーム、ログファイル等のさまざまな種類の非構造化データも存在し、これらのデータをビジネスに活用する動きが世界中で広がってきています。 - 頻度、スピード(Velocity)
今この瞬間にも、大変な高頻度でICタグやセンサーからデータが生成されています。昨今の変化の著しい市場環境では、これらのデータによりリアルタイムに対応することが求められてきています。
図1のように「ビッグデータ」はITの進化の歴史でもあります。
- 当初は業務処理の情報システムから始まったITは、
- ハード&ソフトウェアの性能が向上するとともに小型軽量化モバイル化して価格が下がり、
- ソーシャルメディアやセンサーネットワークの進展により大量、多様なデータが生出され、
- クラウドの普及によって、必ずしも自前で蓄積、処理環境を持たなくてもよくなり
ビッグデータの普及に加速がついてきたのです。
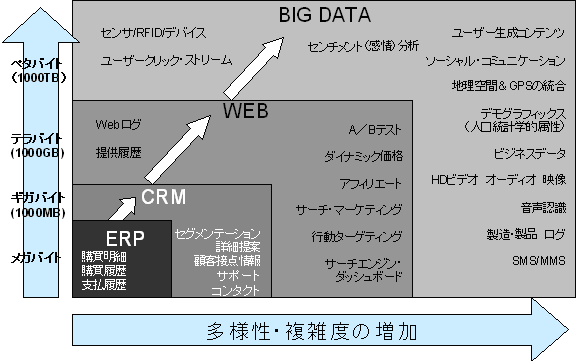
図1 ビッグデータ=トランザクション+インタラクション+オブザベーション(観察)
出典:Teradata&Hotonworksを日本語化[3]
3.ビッグデータの事例
ビッグデータの活用は今に始まったわけでなく、宇宙開発や飛行機の運行管制管理、バイオテクノロジーのゲノム解析や気象予報など高価なスーパーコンピュータを使った限定された利用でした。巨大な構造化データベースとして、Bank of Americaでは1.5ペタバイト以上のデータウェアハウス(DWH)を持ち、ウォルマートは2.5ペタバイト以上、インターネットのオークション・サイトであるeBayでは6ペタバイト以上のデータを格納したDWHが稼働しています。これらは図1では左下のERPからCRMの部分であり、個別でストックのデータ活用といえます。
総務省のビッグデータの活用に関するアドホックグループの検討状況「4」には、25の国内外におけるビッグデータの事例が紹介されています。図2に示すように「ストックかフローか」「全体か個別か」という分類分けをしており、ビッグデータの基盤技術が整備され、活用例が増えるとともにより価値の高い全体でかつリアルタイムの社会的課題の解決や経済規模の拡大に貢献するとしています。
![ビッグデータ事例と方向性[4]](images/rwm20130201_clip_image002.gif)
図2 ビッグデータ事例と方向性[4]
4.ビッグデータの基盤技術
ビッグデータを収集して、分析して、価値を創出するまでの基盤技術について代表的なものを見てみます。その全体像は表1に示してみました。「価値の創出」は事例から分類しました。以下、代表的な基盤技術について解説します[5]
表 1.ビッグデータの基盤技術の位置づけ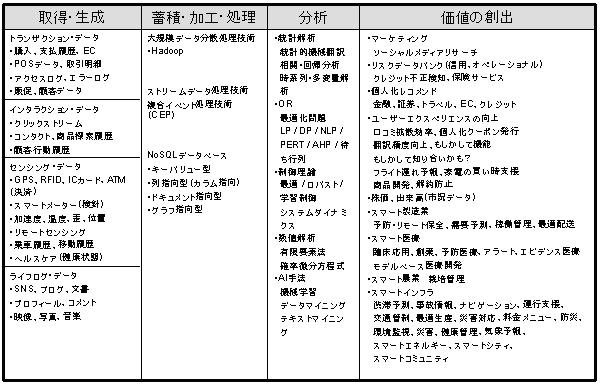
(1) NoSQL(Not only SQL)
表形式によるリレーショナルデータベース管理システム(RDB)とは異なる設計によって実装されたデータベースシステムのことで、RDBMSが定型データの処理を必要とする業務システムでの利用に適しているのに対し、NoSQLはセンサーやソーシャルメディア等の非定型データを含む多様なデータを大量にデータベース化するために利用されます。RDBMSが得意でない用途に補完的に使われるので、「Not only SQL」という意味からの名付けです。NoSQLデータベースではキーとそれに対応するバリューの組み合わせ、あるいはキー・バリューのペアと追加キーによって表現されるために単純で、スキーマの定義は柔軟に変更可能です。拡張性については、RDBMSがサーバの性能向上であるスケールアップが基本であるのに比べてNoSQLはサーバ数の増加によるスケールアウトによって容易に拡張可能なのでビッグデータに適しているといえます。
(2) Hadoop(分散処理技術)
米国NPOのApacheソフトウェア財団のプロジェクトで開発が進められている、大規模データの効率的な分散処理等のためのオープンソースソフトウェアフレームワークのことです。複数のサーバを通じた並列処理により、柔軟かつ継続的な大規模データの高速処理が可能です。
(3) CEP(複合イベント処理技術)
データをディスクに格納せずに、書込速度がディスクに比べて高速なメモリ上で逐次的に処理することにより、必要な情報をリアルタイムに抽出する技術のことです。ディスクにデータを蓄積して分析する手法と比べ、短時間で処理が可能であるため、クレジットカードの不正利用や防犯カメラ映像の異常検知等、短期間での対応が必要となる場合に利用されます。予め利用者が定義するリアルタイム処理の内容には、単一のデータ属性の閾値による判別に加え、複数の属性を組み合わせた処理の設定も可能です。FacebookやTwitter、LinkedInといったWeb系企業は自らのサービスのためにストリームデータ処理エンジンを開発しており、オープンソースとして公開しています。
(4) 推薦(レコメンド)システム
膨大な情報の中から欲しい情報を提供する情報推薦システム(recommender system)は1990年代に初めて登場して以来、アマゾンの推薦サービスに代表されるように今日では、オンラインショッピングには欠かせない存在となっています。推薦の個人化(personalization)には、全体の傾向について遍くすべての人に同じ情報を推薦する「非個人化」推薦と、個々の嗜好に合わせた個別の「個人化」推薦があります。「非個人化」の代表は編集者による推薦や、売上順位リストです。利用者の要求レベルが高くない初心者や利用頻度の少ない場合には「非個人化」の概要推薦でよいでしょう。アマゾンのビジネスモデルである細長いロングテールを太くして収益を上げているのは、ビッグデータの時代の要請であるとともに、「個人化」推薦が大きな価値を生むことを示しています。
「個人化」推薦の技法には、類似ユーザーの行動を推薦する「協調型推薦(協調フィルタリング)」や、情報の内容によって選択する「内容ベース型推薦」があります。さらに1回限りの購買者が大多数を占めるといった場合に有効な、ユーザーと商品アイテムに関する制約などの付加情報を活用する「知識ベース型推論」などがあります。
「内容ベース推薦」が基礎とする検索エンジンの進化の方向性として「セレンディピティ」だと言われます。
セレンディピティとは、知恵と偶然により、予期しない素晴らしい発見をする能力のことです。
18世紀の英国作家、ホレス・ウォルポールが、今のスリランカであるセレンディップの三人の王子のお伽話にちなんで名付けた言葉です。
KDDI総研のレポート[6]から、検索エンジンの進化と、最新の検索エンジンである「セレンディピティ・エンジン」の事例を紹介します。
検索エンジンの進化は、
第1期 検索エンジンがWebを支配
第2期 Web 2.0とソーシャルブックマーキングの登場
第3期 個性化したレコメンデーション
第4期 個性化したセレンディピティ
と言われます。
セレンディピティ・エンジンを使っていると言われるレストランやバーなどの飲食店情報をレコメンドする無料アプリAlfredでは「個人化された、状況把握型(context-aware)の発見エンジン」のことです。ユーザーの関心、嗜好の履歴、時間帯、曜日、お店の評判、同伴者など、複数のファクターを考慮して、その状況のそのユーザーに相応しいお勧めを紹介します。他の多くのサービスが使っているのは、連携フィルタリング(collaborative filtering)と呼ばれるもので、そのユーザーに似ている人たちの好みに関するデータを使用しますが、Alfredはこれにモデルベース学習(model-based learning)という別の技術を組み合わせて、個々のユーザー毎に最も相応しいお勧めリストを作り出しています。モデルベース学習は個々のユーザーに関する一段掘り下げた個人化を可能にします。「あなた」の好みに相応しいお店を絞り込むことができます。
(5) メタデータ
大量のデータが意味を持つにはメタデータが大きな役割を担います。メタデータとは何でしょうか?
私達が生きている現実世界には、金額や顧客情報、計測や性能などの構造的な情報のほかに、映像や音声、ドキュメントやプログラム、最近ではTwitterやFacebookといったSNS(Social Network)などにある非構造的、非定型な情報といった多種多様で莫大なデータが存在します。情報処理の観点からいうと、これらのデータはコンピュータで扱うために現実世界から切り取った情報ともいえます。これらのデータの中から必要な物を見つけて意味のある結果をもたらす(情報処理)ためには、データを処理するための、データに関するデータが必要になります。このようなデータを処理するためのデータのことをメタデータといい、メタデータを収集・登録・管理したものをデータディクショナリといいます。データディクショナリはデータの管理を主とします。一方、リポジトリはより広い範囲のソフトウェア開発における各工程での成果物を、実行プログラムを最終成果物として、その上位概念である設計や要件などのメタ情報を管理するデータベースです。
博物館、美術館、公文書館や図書館の所蔵品をデジタル化して保存、利用することをデジタル・アーカイブと言いますが、最近ではOA文書や電子出版、Web上のドキュメントなど最初からデジタルの「ボーンデジタル」が増えています。GoogleやMicrosoftも図書館に残されている過去の書籍のデジタル・アーカイブ化を進めており、学術論文ではGoogle Scholarというサービスがあります。
具体的にビッグデータのメタデータにはどのようなものがあるのでしょうか? ここでは、次の3つを紹介します。
| 1) | Dublin Core |
| 従来、社会にある膨大な情報の代表例は書籍でした。その書籍を保管、共有する代表的な機関は図書館です。各国の国立国会図書館のメタデータは、Dublin Core Metadata Element Set[DCMES]が多く利用されています。 これは、Web上に流れる情報群を目録化する目的で,1995年より策定が開始されました。 W3Cのメンバーの呼びかけによって,図書館員・アーキビスト・人文科学者・Z39.50の関係者,SGMLのコミュニティなどの関係者が,アメリカ・オハイオ州ダブリンに集まり,Webで公表される文書を記述するための,データ要素について議論しました。この地にちなんで,ダブリン・コアと名付けられました。その後,1997年に,15の基本的なメタデータセットからなる要素表が作成されたのです。 簡単に記述できることを目指して、簡易なメタデータを作成するとの意図から作られたため、必ず記述しなければならない必須項目や、各項目の記述順序は無く、同一項目を複数回使用することも自由であるために、利用する側での留意が必要です。ただ、内外の図書館で広く利用されているためにメタデータ共通化の取り組みが図られています。2003年にISO 15836及び NISO Z39.85の国際標準となりました。DCMIの最近の活動ではメタデータ語彙とOWLオントロジーへのマッピングを整備しており、利便性の向上にセマンティックWebを取り込もうとしています。 | |
| 2) | EAD(Encoded Archival Description) |
| SAA(米国アーキビスト協会)、米国議会図書館が制定して推進している、世界共通の文書館・公文書館などアーカイブズのためのメタデータのセットです。アメリカアーキビスト協会において作成された,アメリカの公文書を検索し,かつ記述するための文書タイプ定義(DTD)のセットでした。もとは,独自の規定でしたが,その整備の過程において、国際標準記録史料記述の一般原則ISAD(G)との互換性を意識し,作成されるようになりました。そのため、公文書館が目録類のデジタル・アーカイブを行うのに最も適したメタデータとして策定されました。現在はEAD2002ですが、改訂版策定に当たりEADからデータのWebと言われるLOD(後述)の記述法であるRDFへの変換を推奨する方向が打ち出されており、2013年夏を目指して策定中です。 日本では国立公文書館・国文学研究資料館アーカイブズ系など各地で用いられており,タグが同一となるため,共通検索が可能となります。公文書をデータベース化するためのメタデータであり、適用が比較的容易です。媒体と内容が一対一で対応しない場合は構造を記述することが困難なので、EADが資料の完全な構造を記述しうるものではないことには留意が必要となります。 | |
| 3) | LOD(膨大な情報を共有する仕組み) |
| LOD(Linked Open Data) は個々の情報や事象にグローバルなIDとしてURIを与え、領域を横断して任意の種類のリンクを付与した、Web上のデータ集合を言います。文書ではなくデータがハイパーリンクでつながったもので、データのWebやデータクラウドとも呼ばれます。 Web がHTML という標準言語を必要としたようにこの「データのWeb」にも標準言語が必要であり、それがRDF(Resource Description Framework)です。LinkedData とは、様々な情報源のデータがRDF で記述され、それらが結びついて作られるデータの集合です。 RDF は元々メタデータ記述言語ですが、LinkedData ではこれを使ってデータを記述します。RDF では、データは(主語、述語、目的語)という単純な関係として記述されます。 オープンでボトムアップな特性からリンクが広がり、公開ツールやWebのAPIの整備と相俟って制限のない情報源に標準的なアクセスが可能となっており、提供者と利用者ともに情報の価値向上につながります。 LODの原則を適用した代表的なデータのWebとして成長著しいのがW3CのセマンティックWeb教育普及グループが支援し、コミュニティの努力によって2007年1月に始められたLODプロジェクトです。図3の「LODクラウド」には2011年9月時点で公開されている個々のデータセットを表しています。このコミュニティが集めたデータセットは316億のRDFトリプルがあり、およそ5億400万のデータセット間のRDFリンクによって結合されています。図3の左には英国政府、左上にはBBCがあり、左下には地理情報、右にはACMやIEEEといった論文が、上部にはWebドキュメントがあります。日本の国会図書館は右上のアメリカ議会図書館(LCSH)の上下にあるNDL Subjects(件名典拠)とndlna(名称典拠)として公開されています。
LODは機械が読めるための形式的、統制的な側面とメタデータ標準の負荷があり、サービスとしての魅力の向上、収益の向上といかに結びつけるかが大きな課題です。日本では情報公開・共有の文化の醸成、コミュニティの未成熟、日本語リソースの記述といった課題もあります。ただし、学術情報に限らず、産業界や社会での活用も始まっており、ビジネスや社会に大きな変革がもたされようとしています。
|

5.ビッグデータの課題
(1)プライバシー問題
ネット上の大量データを処理することで個人の識別が可能になります。これまで非個人情報とされたものであっても、消費者はプライバシーが脅かされ、従来の個人情報保護対応の見直しが必要になってきます。例えば、航空写真、街路写真、統計データ、行動履歴といった従来なら個人を特定できない非個人情報が、他の情報との照合によって個人を特定できるようになってきました。
米国ではGoogleやFacebookでプライバシー侵害事件も生じており、Androidにおける不正アプリも急増しています。そのような状況で、2012年初めに欧米ではプライバシー保護法制の見直しが大きく進展しました。EUは「人権」としてのプライバシー保護をオプトイン(事前同意を原則)で強化しました。新たに「忘却される権利」の付与などが行われた。一方、米国では消費者の「自己情報コントロール権」を明確化するとともに、消費者は、自身が意図した脈略に沿って、事業者による個人データの収集・利用・開示が行われることを期待する権利を有するという、「プライバシー保護期待権」も包含しました。こうした欧米諸国の動向を踏まえて、日本でも今後対応が必要な論点を、公開されているレポート[8]から紹介します。
- 行動ターゲテイング:個人の意向を尊重するメカニズムを同意なしに構築してよいかが論点
EUはCookie指令でオプトイン規制を指向、米国は[Do Not Track]という自主規制 - プロファイリング(個人データ売買):本人が同意しない不正確な人物像創出の規制
EUは「プロファイリングされない権利」の創設、米国はデータブローカ-への罰則で規制強化 - 子どもの保護:子どものプライバシー保護
EUは親権者の同意義務付けと「忘却される権利」の創設、米国は現行法の監督強化
以上の論点に対する、プライバシー保護を実現させるためのポイントとしては、次のようなものになります。
1)ユーザー期待に応える初期設定、同意取得(オプトアウト・インの組合わせ)
2)事前評価によるリスクの特定・最小化
3)ポリシーによる自主規制と第三者チェック
4)若年層、子どものプライバシー保護とリテラシー向上
5)マイナンバー制度の仕組みの導入と拡大
(2)人材、組織
表1に見たように、ビッグデータの基盤技術のなかでもデータ分析の専門家である「データサイエンティスト」の人材不足が課題となっています。米国でデータサイエンティストと言えば、一般的には「統計解析や機械学習、分散処理技術などを用いて、大量のデータからビジネス上意味のある洞察を引き出し、意思決定者に分かりやすく伝えたり、データを用いた新たなサービスを作り出したり出来る人材」のことです。この人材に求められる知識とスキルは、「数学、統計、データマイニング」「コンピュータサイエンス」、「データの可視化」「コミュニケーションスキル」と幅が広いのです。一方、日本では「数学、統計、データマイニング」だけを強調する嫌いがありますが、これだけでは業務側とも、IT側ともコミュニケーショが取れない恐れがあります。特に業務側への価値提供が最も重要であることから業務への理解も必要になります。積極的に業務部門とコミュニケーションを取り、ビッグデータを分析、加工、処理することによって出てくるビジネス価値創出までのシナリオが描けることが必須です。
組織的にはビジネス・インテリジェンス(BI)のコンピテンスセンターであるBICCが必要になってきます。業務部門の相談に乗り、サンプル的にデータ分析して可視化を行い、問題の定義と、解決に向けたシナリオづくりを業務部門と二人三脚で進めていくことができる組織になります。
(3)企業文化
新しく起こったビッグデータ活用の流れは、昔から精巧な手法を構築してきた業界経験者にとっては信用できるものではないでしょう。ところが業界素人のほうが、正確なデータ分析ができるという実例が出てきています。例えば、全米の大都市圏の不動産価格の推移です。全米不動産協会(NAR)の精巧な手法による公式予測よりも通常のWeb検索で得た直近のデータによる予測のほうが精度の高い短期予測ができたのです。また、Googleのインフルトレンドによると疾病対策センターが公式な警報が出る1週間前に予測できるのです[9]。このように、新たな手法にも理解をして、業務専門家が協力できる体制が取れることが望ましい。
6. ビッグデータはどこへ向かうか
過去の見える化であったBIを進化させて将来予測につなぐものとして、ビッグデータは、その価値を生むビジネスモデルを探りながら、クラウドサービスの進展と相俟って、益々量的、質的、時間的に広がり、企業にも、個人にも、社会にも有用なスマートシティやスマートコミュニティにおけるIT基盤として定着していくものと思われます。その過程では、データ・アグリゲータというような新たな役割を担う付加価値提供業者を生み出しながらも発展していくものと思われます。
7. おわりに
本稿では、ビッグデータの位置づけと課題について、考察しました。
次回は、DWH、BI、データマイニング、テキストマイニング、Hadoopなどを中心に解説する予定です。
(参考文献)
| [1] | The End of Business As Usual,Brian Solis |
| [2] | The Fourth Paradigm: Data-Intensive Scientific Discovery |
| http://research.microsoft.com/en-us/collaboration/fourthparadigm/ | |
| [3] | Hotonworks |
| http://hortonworks.com/wp-content/uploads/2012/05/bigdata_diagram.png | |
| [4] | 総務省、ビッグデータの活用に関するアドホックグループの検討状況、平成24年4月27日 |
| http://www.soumu.go.jp/main_sosiki/joho_tsusin/policyreports/joho_tsusin/shinjigyo/02tsushin01_03000104.html | |
| [5] | ビッグデータの衝撃、城田真琴、東洋経済新報社 |
| [6] | 進化する検索エンジン-キーワードはセレンディピティ |
| [7] | 日本におけるLinked Dataの現状と普及に向けた課題、武田英明、情報処理、Vol.52 No.3 Mar.2011 |
| [8] | ビッグデータ社会におけるプライバシー |
| [9] | ビッグデータ競争元年、DIAMONDハーバード・ビジネス・レビュー、2013年2月号 |
*本Webマガジンの内容は執筆者個人の見解に基づいており、株式会社オージス総研およびさくら情報システム株式会社、株式会社宇部情報システムのいずれの見解を示すものでもありません。
『WEBマガジン』に関しては下記よりお気軽にお問い合わせください。
同一テーマ 記事一覧
 「 BigData 第4回 ビッグデータ時代の情報連携基盤 」
「 BigData 第4回 ビッグデータ時代の情報連携基盤 」
2013.05.21 共通 OGIS International, Inc. 大村伸吾/株式会社オージス総研 大場克哉
「 BigData 第3回 ソーシャルメディアとBIGDATA 」
2013.04.17 共通 株式会社オージス総研 竹政 昭利
「 BigData 第2回 ビッグデータ利活用、その環境 」
2013.03.12 共通 株式会社オージス総研 杉野 真士/藤本 正樹
「今度こそ、”データ利活用による継続的業務改善”を実践しよう!(4)」
2012.03.07 製造 株式会社オージス総研 藤本 正樹
「今度こそ、”データ利活用による継続的業務改善”を実践しよう!(3)」
2012.02.08 製造 株式会社オージス総研 藤本 正樹
「今度こそ、”データ利活用による継続的業務改善”を実践しよう!(1)」
2011.12.12 製造 株式会社オージス総研 藤本 正樹