WEBマガジン
「 BigData 第2回 ビッグデータ利活用、その環境 」
2013.03.12 株式会社オージス総研 杉野 真士/藤本 正樹
※ 本稿は、財団法人経済産業調査会発行 「特許ニュース」 No.13427 (2013 年3 月6 日発行)への寄稿記事です。
※ 前回の記事はこちら。
1. はじめに
昨今、各種メディアでビッグデータというキーワードを目にすることが多くなってきました。これは、ビッグデータの分析によって他社との差別化を図る企業が出始め、その利活用が本格化し始めたことを示しています。本文では企業においてビッグデータをいかに活用していくべきか、そのデータ分析を行うための環境とはどのようなものであるかをご説明してまいります。
2. ビッグデータの活用例
ビッグデータを事業の効率化や品質の向上に利活用するとはどういうことかを見ていきます。
ビッグデータというとまず頭に思い浮かぶのは「SNS(Social Netowork Service)」ではないでしょうか。SNS がなぜ企業のデータ分析利活用として注目されるかというと、消費者は自分と同じ消費者の声に最も影響されやすいことが挙げられます。例えば、マスメディアで広告費を多額にかけた映画でも、実際に映画を見た観客が映画館から出てきて「この映画、つまらない」と、SNS の一つであるツイッター(Twitter)でつぶやくだけで翌日から映画の観客動員数がマイナス傾向になってしまったりします。同様な例で対策した事例として、トヨタ自動車の北米でのプリウス・リコール問題では、ツィッターなどのSNS によるクレーム分析にテキストマイニングを駆使し対策を練ったと言われています。 逆に、攻めのデータ分析利活用として、ある食品メーカーや家具メーカーは、新商品を市場に出荷後、購買データのSNS の顧客の声を取り込み、改良品を市場に再投入して顧客の心をつかみ、ユーザ参加型のプロジェクトとして顧客とコラボレーションで共同商品企画・開発するコミュニティーを構成するにいたった例があります。
企業内に目を向けると、関連もなく管理されていた製品企画や設計、生産工程の製造プロセスログや品質管理データ、出荷後のユーザの声、サポート管理データなどの製品を包括するPLM(Product LifecycleManagement、製品ライフサイクル管理)にデータ分析の手法を取り入れ、企業競争力を高めている企業があります。この代表的な例はApple 社で、上記のPLM にマーケティングの要素を加えて、トラッキングすべきチャネルを卸売り店ではなく、消費者にダイレクトな量販店に絞り、そのセル・スルーのデータを分析利活用した上で商品にフィードバックして、直接消費者にうったえるビジネスモデルをワールドワイドに展開して大成功を収めています。
3. 従来のデータ分析
3.1 従来のBI(Business Intelligence)
データを分析しデータ利活用するBI(Business Intelligence、ビジネス・インテリジェンス)の考え方は従来からあるものです。ただし、日本におけるBI の多くはレポーティングや現状分析にとどまっており、分析を実施する部署や人数もスポット的で限られ、その分析対象となるデータソースも分散されたシステムの履歴・実績系のデータベースや手元にあるエクセルに纏め上げたデータがほとんどでした。
従来はアーカイブとしてテープ保管などになり、自由に利活用が難しかったデータソース群も、それを安価にストレージに格納したまま処理できるハードウェアやソフトウェアの進化により、これまでは不可能であったビッグデータのような大規模で多種多様なデータソースを分析対象とすることが可能となり、今後の企業の競争力向上に役立つと期待されています。
3.2 データ利活用の現状
情報分析ツールについて、面白い調査結果があります(図1)。「情報分析ツールを利用している」が全体の約70%を占めますが、実際、「利用が進んでいる」が約30%しかなく、「ビジネスに貢献している」に到っては10%未満となっています。
![情報分析ツールの活用状況[1]要](images/rwm20130303_clip_image001.gif)
図1 情報分析ツールの活用状況[1]
先述のように、日本でもビッグデータの波が押し寄せる前に、第一期となるBI 普及時期がありました。「重点業績指標(KPI: Key Performance Indicator)とともに、経営の事業の舵取りするデータが得られるシステムとして大きく期待され導入されました。しかし、結果は先述の通りです。
定着しなかった原因としては、使用者が限定的であり、使用内容も従来どおりの特定業務のレポート機能がメインとなり適用範囲の広がりも無く、とりあえずのデータ収集となってしまっていったこと、同時期のJ-SOX適用も絡んでコスト圧縮のための電子帳票化手段に縮小した、などがあげられます。これらは、導入企業のデータ利活用の目的や目標が十分に認識されず、必要だと思われるデータソース群を寄せ集めたことで情報がオーバーフローしたことや、IT 導入時によく陥りがちなパターンとして、ツールを入れたことで目標を達成したという暗黙の誤認があるかと考えています。また、システム的には、情報利活用に適した安価なハードウェアや、大規模データ処理に適するデータベースがまだ出現していなかった点、そして、DWH(Data Ware House、データウェアハウス)設計時にデータの精度や粒度、鮮度をよく考慮して構築されなかった点があると考えています。
4. ビッグデータを含めたデータ分析
4.1 データ利活用のIT 潮流
オージス総研は、2011年度からデータ利活用ソリューションをご提供しています。ご提供に先立ちシリコンバレーで各ベンダーやユーザにデータ分析について情報収集をしたところ、米国ではBI というより、ビッグデータに対してのAnalytics が主流となってきているという回答が大筋でした。筆者らはデータ利活用ソリューションに、このIT 潮流を組み入れ、オージス総研のSI ノウハウも含めたネーミングとして「モデルベースBA(Business Analytics)」と名付けたのですが、期せずして日本でも、最近大手ベンダーの多くが従来のBIソリューションをBA として変更し、ビッグデータ分析のソリューションを立ち上げています。
4.2 オージス総研が考えるBA
今後のデータ分析の方向性として筆者らは次のように考えています。
- 企業競争力を強化するという目標に向けて、データ利活用が企業内において、全社レベルで戦略的に実施されていくべきである。
- 従来のBI の枠であるレポーティングや現状分析から、データマイニング技法を主軸として、将来予測や最適化・シミュレーションへステップアップすることが必要である。
それを実現する手段として、データ利活用のコンサルティング&ファシリテーションのご支援でBA利活用ポジショングリッドを策定し、現状のポジションから、ステップアップすべき将来像のポジションと達成すべき分析ターゲットを明確にします。これはシステムがカットオーバーされた後も継続的に改善を重ねて将来像への羅針盤となります。そして、SI で培ったモデルベース開発ノウハウにより、スモールスタート型の導入から開発、運用サポートまでを一貫して見える化とともにご支援するソリューションとしています。
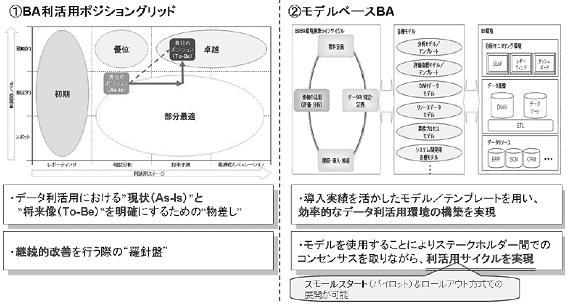
図2 オージス総研の考えるBA実現手段
4.3 BA利活用ポジショングリッドによるデータ利活用計画の設定
(1)目的の設定
"目的"は組織、関係者間で共有してこそ意味があります。経営や事業における目的を設定、共有するには、「BSC(バランスト・スコアカード)」が効果的です(図3)。BSCの「戦略マップ」により会社としての成功シナリオを作成(経営戦略や事業戦略の可視化)し、その中で"何のためにデータ利活用を実施するのか"を明確にします。また、「スコアカード」によりモニタリングする対象が明確になります。
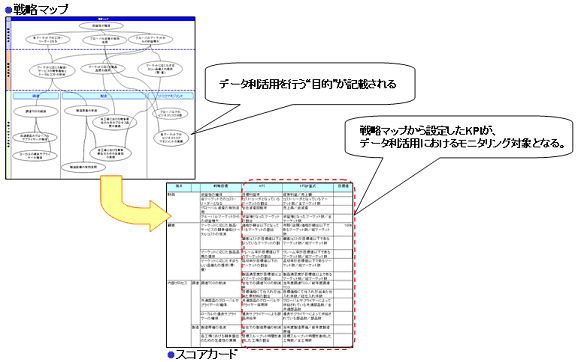
図3 BSCを使用した目的の設定
ここからは、国内展開している製造業として下記のモデル企業を設定し、その内容に沿ってご紹介します。
【概要】
- 一般的な組み立て型製造業である。
- 「インストールベース利益モデル」である。
(※)「インストールベース利益モデル」の例:かみそり、コピー機、浄水器とフィルター、プリンタとインク
【背景】
- 国内マーケットの成熟により、新規製品売上が芳しくない。
- 製品そのものよりも、消耗品、周辺オプション製品の方が利益率は高い。
- 製品は営業部、消耗品・周辺オプション製品はサービス部の管轄となっている。
【経営上の課題】
- 国内マーケットが広がらない中で、どうやって(国内で)売上を確保していくか。
まずは目的の設定です。前述の概要、背景、課題、あるいは外部情報をインプットとして、戦略マップを作成します。(図4)
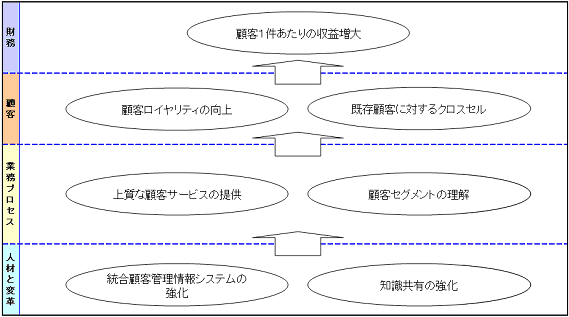
図4 モデル企業の戦略マップ
図4の戦略マップに記載されている内容が"BA導入の目的"となるべきものです。簡単に整理すると、「顧客に対する理解を深め、顧客に合った製品・消耗品・周辺オプション製品を提案・販売することにより、顧客のライフタイムバリューを高める」となります。
(2)"目的"に沿ったデータ利活用のあるべき姿(To-Be)を策定する。
前述の"目的"を基にデータ利活用のTo-Be像を明確にします。この手順では、「成熟度」の考え方を使用します。成熟度とは、企業の経営や情報化の現状などの実現レベルを多段階で評価し、段階に応じた施策を行っていくための度合いのことです。成熟度を測ることで企業の現在のレベルが明らかになり、今後どのような施策を実施していくべきかを明確にすることが出来ます。
データ利活用における現状(As-Is)とあるべき姿(To-Be)を明確にするときの"軸"については、企業や組織内におけるBAを展開する範囲(部門、全社、など)とデータ利活用レベル(レポーティングのみ利用、現状分析、など)は必ずしも比例していないため、展開レベルと利活用レベルの2軸によるポジショニングが必要と考えられます。
そのため、「BA展開レベル(BI/BAを適用する範囲)」(図5)と「BA利活用ステージ(BI/BAを利活用するレベル)」(図6)の2軸を使用して、"目的"に応じたBAの適切な利活用度合いを測ります。(図7)

図5 BA展開レベル
![BA利活用ステージ[2]](images/rwm20130303_clip_image006.gif)
図6 BA利活用ステージ[2]
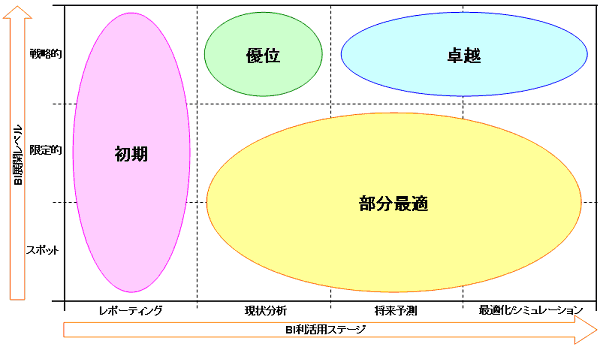
図7 BA利活用ポジショングリッド
1)As-Is設定
図5、6で示した内容を基に、今の企業・組織の状況がどこに当てはまるかをチェックします。ちなみにオージス総研では「BA利活用ポジショングリッド診断ツール」をご提供しており、20個程度の項目にご回答いただくことによりAs-Isを確認できるようになっています。
なお、部署や立場の違いによって、As-Isの認識が異なることがあるため、関係者全員のコンセンサスを得ながら決定していくことが重要となります。
さて、モデル企業においてはどうでしょうか。データ利活用の状況について、ヒアリングした結果が以下の通りとします。
【データ利活用に関する状況】
- 各部門の各業務システムから、月報、週報などのレポートを出力している。
- データマイニングなどの分析業務は「出来る人がやっている」状態であり、その結果も共有されていない。
- 各部門の業務システムがバラバラであり、顧客や取引先の情報は各部門毎に管理されている。
「各部門のシステムからレポートを出力している」、「分析業務は出来る人がやっているだけで、結果も共有されていない」ということが記載されていますので、「BI展開レベル:スポット、BI利活用ステージ:レポーティング」であると思われます。
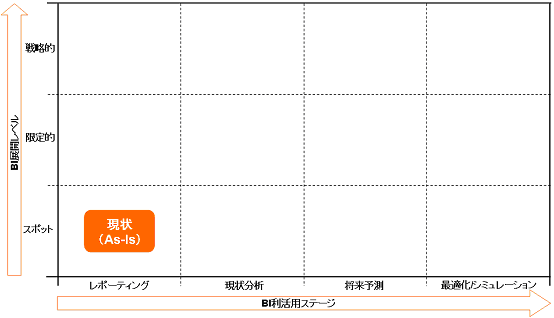
図8 モデル企業の"As-Is"
2)To-Be設定
"目的"を基にして「その"目的"を達成するためには、ポジショングリッド上のどこに位置していなければならないか」を、As-Isの場合と同じように図2、図3に示した内容を基に決定します。ここでもやはり、関係者全員のコンセンサスを取ることが重要となります。
さて、モデル企業を見てみましょう。モデル企業における"BA導入の目的"は、「顧客に対する理解を深め、顧客に合った製品、消耗品、周辺オプション製品を提案、販売することにより、顧客のライフタイムバリューを高める」でした。この"目的"を達成するためのTo-Beはどこに設定すれば良いのでしょうか?
- ・BA展開レベルについて
- 顧客を理解し、クロスセルを実施していくためには、顧客情報が部門(ここでは主に営業部、サービス部)を跨いで共有されている必要があります。また、データの分析結果についても共有し、業務内で活用していくことが求められます。
- ・BA利活用ステージについて
- クロスセルを効率的に実施するには、顧客毎に"そろそろ必要になりそうな消耗品"、あるいは"興味のありそうな周辺オプション製品"をこちらから予測して、お勧めすることが求められます。いわゆる「リコメンデーション」と呼ばれるサービスです。
よって、モデル企業が目指すべきTo-Beは「BA展開レベル:戦略的、BA利活用ステージ:将来予測」というポジションだと分かります。
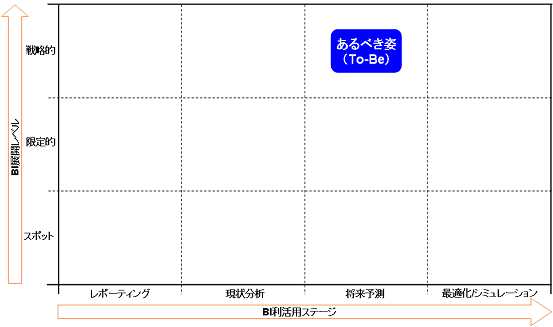
図9 モデル企業の"To-Be"
以上のように、データ利活用における"現状(As-Is)"と"将来像(To-Be)"を明確にするための"物差し"を用いて、今後どのような施策を実施するのかを明確にすることが重要なのです。
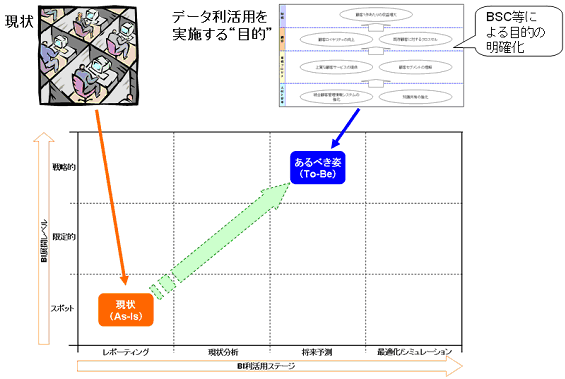
図10 「BA利活用ポジショングリッド」を使用したTo-Be設定のイメージ
(3)"実現可能なステップ(Can-Be)"を明確にする。
現状(As-Is)と将来像(To-Be)を決めたら「その将来像に向かって一直線に進む」となれば良いのですが、現実には様々な制約(要員、予算、リテラシ、等)が存在します。このように一足飛びに進めない場合には、実現可能なステップ(Can-Be)を段階的に立てることが必要となります。
さて、モデル企業についてはどうなるでしょうか。
中期計画として3ヵ年の計画が発表されているという仮定で、将来像への到達は3年後とします。また、現状(As-Is)のポジションから、データマイニングなどの高度なデータ利活用をする組織文化、人材は少ないということになりますので、方向性としては「まずは各部門内でデータ利活用の実績を作り、レベルを上げる。その後で部門をまたがった利用に発展させる」となるでしょう。それを3ヵ年での計画に落とし込むと、
1年目:現状分析などのレベルでのデータ利活用を各部門内で実施できるようになる
2年目:各部門において必要な将来予測などのデータマイニングが実施できるようになる
3年目:部門をまたいで(全社的に)データ利活用が出来るようになる
というCan-Be設定になります。
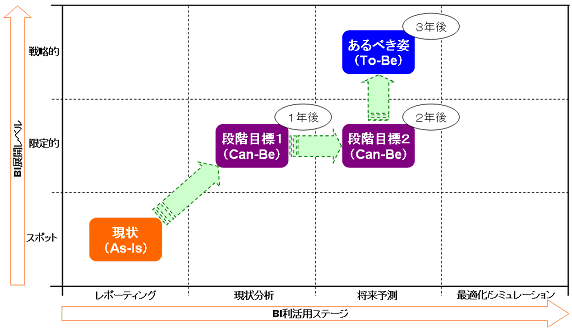
図11 モデル企業の実現可能なステップ(段階目標)
このように、目的に対応した戦略的かつ現実的な計画を立てることが、データ利活用を成功に導く1つの要因であると考えています。
5 ビッグデータをデータ分析するためには
5.1 データを利活用するための重要3 大要素
データ利活用を進めるにおいては、下記の3要素が三位一体となって初めて精度のあるデータ分析を行える環境が整い、有効性のある分析結果が得られると考えています。(図12 )
- ビジネスプロセス指標の策定
- ビジネスデータとシステムデータの紐付け(データ属性マネジメント)
- DWH構築

図12 モデルベースBAと重要な3要素
5.2 ビッグデータのデータ利活用に適した情報分析ツールとは
データ利活用は、仮説& 検証型で継続的に進める活動となります。そのためにフロントの情報分析ツールは、まず機能が十分で、期間や範囲、コストの点において小さく始められ、全社規模へ利活用が発展してもユーザ数の増加に対してライセンスなどの費用が増加しない特徴を持っていることが重要です。
これに適合するソフトウェアの一つとして、OSS(Open Source Software)のJaspersoft 社のBI Suiteがあります。大手ベンダーのBI ソフトウェアと同等の機能を持ち、CPU ソケット数に対して課金する形態をとりますので、ユーザ数の増加で費用負担がなく、スモールスタートからの全社展開に適しています。またOSSのメリットとして他のオープン系ソフトウェア・システムとの高い接続性も、拡張面で優位性があります。
5.3 ビッグデータのデータ利活用に適したデータベースとは
5.3.1 従来のデータベース
従来、データベースが導入されるサーバについては、減価償却期間にほぼ時期を合わせ、ストレージやメモリの容量などを積算し、ハードウェアのモデルを最初に準備する方法を取ることが殆どでした。そして、もしその計算値を上回る想定外の事態が起こり、容量やパフォーマンスが耐えられない場合は、CPUの増強やサーバマシンの入替えを行ってシステム全体をスケールアップする対処が普通で、データベースも然りでした。また、従来のRDB(リレーショナル・データベース) は、OLTP(On-LineTransaction Processing オンライントランザクション処理)の更新系処理に向いているものの、参照型メインのDWHとして向いているものではありませんでした。
また、ビッグデータの時代になると、そもそも何年後かの推測の各種積算が困難であり、巨大なコストがかかるサーバ入れ替えのスケールアップを前提にすることができません。必要な時に必要な数の安価なサーバやストレージを追加することでデータを蓄積し、パフォーマンスやスケーラビリティを保つスケールアウト型のDBMS(データベース・マネージメントシステム)が必須要件となります。
5.3.2 従来のデータベースのDWH でのボトルネック
従来のRDB は、データベース・サーバ群から、ストレージを共有する形(シェアード型、もしくはシェアード・エブリシィング型と呼ばれる)をとっており、大規模データの並列検索処理ではデータ転送帯域で競合が起こり、パフォーマンスを確保することが難しい構造になっています。これに対して分散並列処理データベースではシェアード・ナッシング型を採用しており、それを回避することが可能で、セグメント・サーバと呼ばれる子サーバ機を追加することで、スケールアウトするメカニズムをもちます。(図13 )
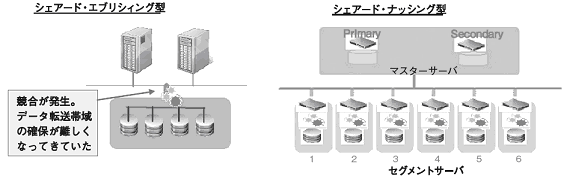
図13 シェアード・エブリシィング型とシェアード・ナッシング型の比較図
5.3.3 ビッグデータに適したデータベース
このスケールアウトするシェアード・ナッシング型の代表的な分散並列処理データベースの一つとして、EMC Greenplum Database があります。これはビッグデータのような大規模データを同時に複数のセグメント・サーバで分散並列処理することをコンセプトとしたDBMS です。
他の分散処理データベースは、専用ハードウェアを使った高額なアプライアンスになりますが、このGreenplum Database はソフトウェアのみでの販売もされていて、まずは安価なコモディティ・サーバと組み合わせ、順次構成を拡張していくというスモールスタートが可能です。商用のDWH 用DBMS の中では安さと速さが両立されており、コストパフォーマンスが高く、スケーラビリティの柔軟性にも優位性があります。
EMC Greenplum Database には下のような特徴があります。
- シェアードナッシング・アーキテクチャ
- 分散処理を実現するMapReduce を実装
- スケールアウト型で、スモールスタートからの柔軟な拡張性をもつ
- 行指向ストレージ・列指向ストレージのテーブルとして使用可能
- 高速なデータロード
- 参照系データに特化したパフォーマンス特性で、検索処理は超高速
- 操作系もRDB と同じSQL 対応
- ストレージ容量や性能の拡張はサーバのオンライン追加で実現
- Hadoop との独自I/F を実装し、Hadoop 連携を実現
5.4 さらなるデータ利活用に向けた技術 ~Hadoop~
ビッグデータの利活用を考えた時に、キーワードの1つとして「Hadoop」というものがあります。HadoopはOSS(Open Source Software)として開発された分散処理を行う際に必要となる機能を備えたフレームワークです。元をたどるとこの技術はGoogleが検索の前処理として開発したものです。Googleがこの技術を「GFS& MapReduce」という論文として発表し、それをもとに開発されたソフトウェアがHadoopです。
Hadoopが注目されているポイントは3つあります。
1つ目にOSSであること。OSSで開発されることによって多くのエンジニアが無償で利用することが可能であり、利用した有能なエンジニアが意見を出し合う事により、さらに良いものに仕上がってきています。Hadoop自体を便利に使うためのエコシステムの開発が盛んなことも注目されていることを裏付けています。
2つ目にはスケーラブルにサーバやストレージの追加ができるスケールアウト型であることです。大容量データを保存し、かつ解析時に高速に読み出すためには従来であればハイエンドサーバを用意する必要がありました。Hadoopではコモディティ・サーバを利用することを前提に開発されていて、コモディティ・サーバを数台、数十台、数百台と並べて大きな一つのストレージとして、さらにプロセッサとして利用することができます。それを実現するためにHadoopでは「HDFS」と「MapReduce」という大きく2つの技術要素を提供しています。
まず「HDFS」は、Hadoop Distributed File Systemという名の示す通りファイルシステムです。
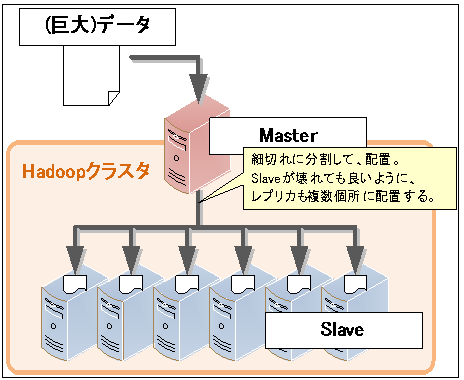
図14 HDFSのイメージ
データを配置する際に、たとえば大容量のデータを1つのDiskに配置した場合、性能の低いDiskから大量にデータを読み出すのには膨大な時間がかかります。HDFSでは巨大なファイルをある程度の大きさ(100MB程度)に細切れ(ブロック)にして、複数のサーバ及びDiskに保存します。複数のDiskから少しずつ並列に読むことで個々のDiskは高性能でなくても早くデータを読み出すことができるからです。加えてデータの消失はもっとも避けたい障害ですが、Hadoopでは1つのデータを複数のサーバおよびDiskに配置することで、サーバの障害が発生してもデータの消失は発生しません。同じデータは他の複数のサーバにも配置しているからです。このようにHDFSは「細切れにして配置」、「複数のサーバに同じものを持つ」という機能で、ビッグデータを扱うためのベースを担っています。
次に「MapReduce」は、実際にHDFSに分散配置したファイルに対して解析等を行う際に利用する分散処理フレームワークです。
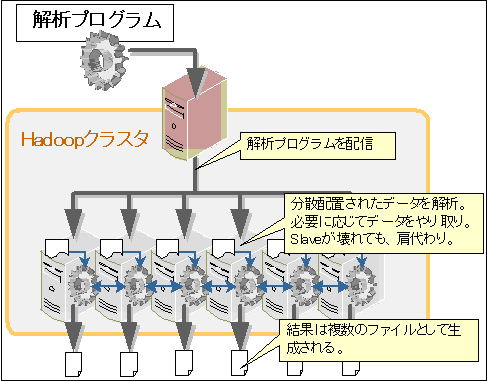
図15 MapReduceのイメージ
先ほどHDFSで複数のサーバにファイルを細切れ(ブロック)にして配置すると述べましたが、複数のサーバに同じものも配置されているブロックのそれぞれに対して解析処理を行おうとした場合、以下のような問題があります。
- どのサーバに配置されている、どのブロックに対して処理を行うかという処理の配置
- 処理途中でサーバに障害が発生した時の処理の再実行や再配置
同じファイルのブロックが複数サーバに分散されていますので、すべてのサーバで同じように処理をしてしまっては解析処理に重複が発生してしまいます。1つのブロックに対しては1回の処理だけが実行されることを担保しないといけません。
また処理の途中であるサーバに障害が発生し、ダウンしてしまった場合はどうでしょうか?すでに処理が終了している結果データが読めなくなってしまいます。またそのサーバで実行するように割り振られていた処理が実行されないことになりますので、違うサーバに肩代わりをしてもらわないと対象データのすべてに対して解析が行えませんので結果が変わってしまいます。
MapReduceはこういった分散処理を行う際にプログラムとして実装しないといけないポイントをフレームワークとして持っています。ですから解析を行うプログラムは、ファイルの配置場所や解析サーバの場所、サーバ障害といったことを意識せず解析をどのように行うかということだけに注力して作業を行うことができます。
3つ目には非構造化データ・非定型的データの扱いが可能という点があげられます。データベースへ情報を格納する際には、事前に設計する必要があります。たとえば1カラム目にはIDが、2カラム目には名前が、といったように事前に定義を行い、格納するデータを整形した上で格納する必要があります。Hadoopは前述したHDFSの名前の通りファイルシステムですので、どんなファイルもそのままで配置することができます。カラム数がバラバラでも、画像でも、動画でも配置することができます。そしてそうしたファイルに対してそのまま解析をかけることができます。もちろん解析の際には分散処理されますので、大容量のファイルの解析も短時間で行うことが可能です。今後はセンサーからのデータに代表されるような非構造化データが膨大に生み出されていきます。そうしたデータを格納し、そのまま解析に利用できるという点は大きなポイントです。
このようにHadoopでは構造化データのみならず、非構造化・非定型的データを含めたデータを大量に保管でき、必要なときにはすぐに利用することができます。元々分析する際には、「何を目的として分析するか」を考え、「それに必要なデータは何か」を決定した後にデータを集めていました。Hadoopの考え方は「まずデータをありのままの形で一箇所に集める」ことを推奨しています。発生するデータを一箇所にリアルタイムで溜めていくことで、それらのデータを横串で見ることができます。そうすることで今までは気づけなかった傾向などを見つけることができます。その上でその溜まったデータを対象として分析していくことが今後のデータ利活用に必要です。
6.ビッグデータ時代の情報分析統合基盤
6.1 データベースのレイヤー分けとデータの鮮度
企業内でビッグデータを格納して情報分析する環境として、データの鮮度を加味し、次のようなレイヤーに分ける必要があると考えています。
- 基幹システムのデータベース層 (更新系処理をメイン)
- 統合されたDWH 層
- 鮮度の高いデータ群
- 鮮度を気にしないデータ群
鮮度を気にしないデータ群とは、現時点では分析対象としないが蓄積する必要があるというデータ群のことであり、例としてはWeb サーバのログや生産工程の設備のセンサーログなどが挙げられます。
これらはコストの面から安価なストレージに蓄積しておきたいニーズが生まれますし、必要に応じて分析対象データとして取り扱いたい、というニーズも発生します。
このニーズに応えるのが、上記のビッグデータに適したデータベースとして取り上げたEMC GreenplumDatabase のHadoop 連携機能です。鮮度の高い基幹系にはDBMS 機能をもつGreenplum Database を設置し、鮮度を気にしないデータ群は、Hadoop 連携機能により安価なサーバー・ストレージにデータを蓄積の上、RDB と同様の操作で、導入および運用のコストを大きく削減することが可能となります。将来的には機密データを含まない鮮度を気にしないデータは、クラウド環境に徐々に移行していくものと思われますが、指数関数的と比喩される新たなビッグデータの一時的な保管場所の役割も期待できます。
おわりに
ビッグデータのような多種多様な大規模データを無駄なくフル活用できれば、競合他社を凌ぐ競争力を獲得できる可能性を秘めています。まずはスモールスタートから始めてみては、いかがでしょうか。本文が皆様のビッグデータ利活用のご理解の一助になれば幸いでございます。
※オージス総研はお客様の環境や諸条件を考慮した上で、独立かつ中立的な立場としてハードウェアやソフトウェアを選択し、SI のご提案を行っております。本文での製品名などはその一部のご紹介でございます。
※この記事はWebマガジン(2011年12月号~2012年3月号)に掲載された「今度こそ、"データ利活用による継続的業務改善"を実践しよう!」をもとに加筆修正したものです。そちらも合わせてお読み下さることをお勧めします。
(参考文献)
| [1] | ITMedia エンタープライズ「情報分析ツールの利用は進まず - 解決のきっかけとなるソフトウェア導入」から引用 |
| [2] | BeyeNETWORK and Decision Management Solutions.「Operational Analytics:Putting Analytics to Work in Operational Systems」(2010/05) を基に追記 |
*本Webマガジンの内容は執筆者個人の見解に基づいており、株式会社オージス総研およびさくら情報システム株式会社、株式会社宇部情報システムのいずれの見解を示すものでもありません。
『WEBマガジン』に関しては下記よりお気軽にお問い合わせください。
同一テーマ 記事一覧
 「 BigData 第4回 ビッグデータ時代の情報連携基盤 」
「 BigData 第4回 ビッグデータ時代の情報連携基盤 」
2013.05.21 共通 OGIS International, Inc. 大村伸吾/株式会社オージス総研 大場克哉
「 BigData 第3回 ソーシャルメディアとBIGDATA 」
2013.04.17 共通 株式会社オージス総研 竹政 昭利
「 BigData 第1回 ビッグデータとは 」
2013.02.12 共通 株式会社オージス総研 明神 知
「今度こそ、”データ利活用による継続的業務改善”を実践しよう!(4)」
2012.03.07 製造 株式会社オージス総研 藤本 正樹
「今度こそ、”データ利活用による継続的業務改善”を実践しよう!(3)」
2012.02.08 製造 株式会社オージス総研 藤本 正樹
「今度こそ、”データ利活用による継続的業務改善”を実践しよう!(1)」
2011.12.12 製造 株式会社オージス総研 藤本 正樹