WEBマガジン
「<オージス総研をとりまく>人工知能技術の過去と現在(上)」
2018.02.20 株式会社オージス総研 乾 昌弘
1.はじめに
平成29年度4月より10月まで「<オージス総研をとりまく>人工知能技術の過去と現在」を連載してまいりました。年度末である今月と来月は、内容をふり返るとともに、年代順ではなく主にキーワードを中心に解説したいと思います。(年代順は下記参照)
2.人工知能技術の変遷
2.ニューラルネットワーク、ディープラーニング
まず、人工知能の中心的存在である(ディープラーニングを含む)ニューラルネットワークについて説明します。
2-1.ニューラルネットワーク(Back Propagation)
(1)1980年代後半を通してニューラルネットワーク(Back Propagation)がブームとなった。ニューラルネットワークは中間層(隠れ層)が多い場合、Back Propagationが前まで伝わらないという欠点もあり、中間層は1層~2層が中心であった。第2次AIブーム後もデータ解析(機械学習)の一手法などで使い続けられることになる。
(2)図1の重み付け(W1、W2)がすべての訓練データに対して誤差が最小になるように調整する。基本的には、2乗誤差の合計を最小にする。(Back Propagationの詳細は、以下を参照)
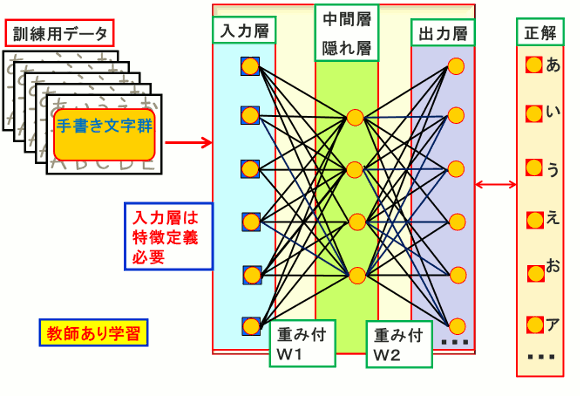
図1.Back Propagation
2-2.「教師なし学習」ディープラーニング
(1)2000年代に入り、まず、入力層と出力層に同じデータを対応させるAuto Encoderを多段階にした「教師なし学習」によるディープラーニングが有名になった。
(詳細は以下を参照)
「<オージス総研をとりまく>人工知能技術の過去と現在(5)」
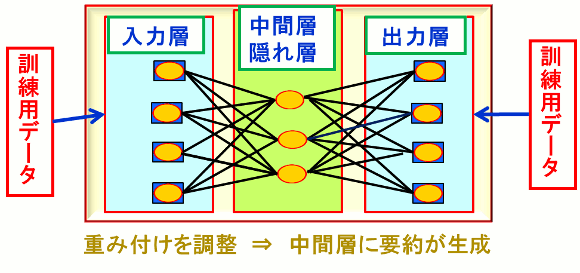
図2.Auto Encoder
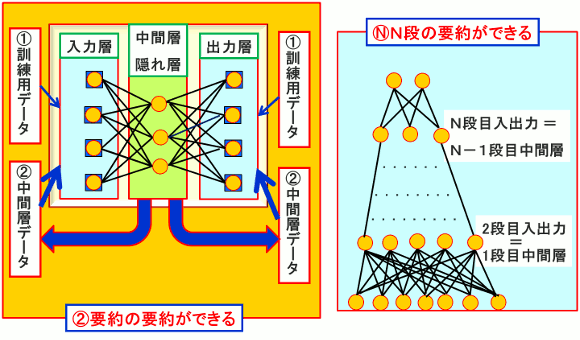
図3.Auto Encoder型ディープラーニング
(松尾豊著「人工知能は人間を超えるか」P161参考)
2-3.「教師あり学習」ディープラーニング
(1)その後「教師あり学習」が主流になっている。その代表格が、1979年大阪大学福島邦彦教授が提案したネオコグニトロンを原型とするCNN (Convolutional Neural Network) である。
(2)CNNは、画像データが利用しやすいようにConvolution(畳み込み演算)によるフィルタ(Smoothing、ノイズ除去、エッジ検出などの)機能が含まれている。
(3)各ノードの出力に用いられる活性化関数に、Rectified Linear Unitsを採用したのも、Back Propagationによる多層のディープラーニングが可能になった一因である。
(4)Grad-CAMという技術を使うと、画像のどの箇所を見て判断したかをヒートマップでわかる。
(5)3DCNN(2D空間+1D時間)を使えば、3DでConvolutionを行うので、動画を対象にすることができる。
(詳細は以下を参照)
2.CNN (Convolutional Neural Network)
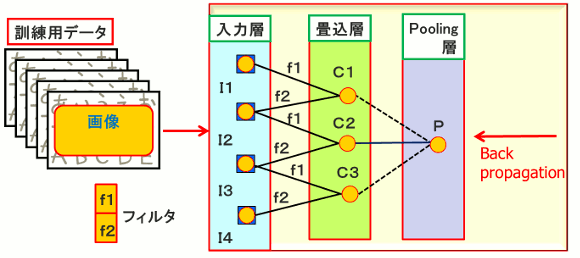
図4.簡単化したCNN(Convolutional Neural Network)
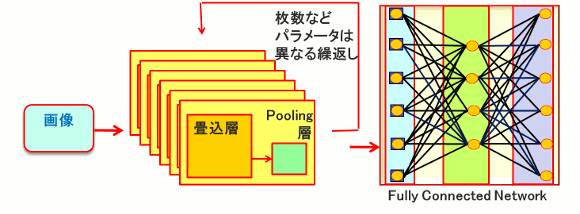
図5.一般化したCNN

図6.Grad-CAMによるCNNの注目箇所
(Citation from Reference 1. Fig. 1)
3.探索、最適化
3-1.数理計画法
数理計画法などの最適化手法はかつて人工知能に含まれ、エキスパートシステムが経験的解法に対して論理的解法と呼ばれていました。
(1)ある「制約条件」のもとで「評価関数」の最小値または最大値を求める。
(2)制約には「ハード制約」と「ソフト制約」がある。ハード制約は、条件を満たさないと解にはならない。ソフト制約は優先順位。
(3)通常は非線形の式を解く。すべて解くと図7のように、どこが最大値かわかるが、最初はまったくわからない(山に霧がかかった状態)解く方法には「メタヒューリスティック法」などがある。場合によっては極大値を結論としてもよい。
(4)「メタヒューリスティック法」には、山登り法などがあるが、広い意味ではBack PropagationやGenetic Algorithmも含まれる。
(数理計画法は、以下も参照)
「ビジネスを解析する手法とその比較(上)」
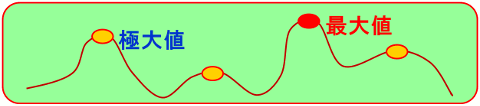
図7.非線形問題
3-2.組合せ最適化
(1)選べる組合せの中から最適なものを選択する。一般的に、ほとんどの最適化問題が範疇に入ると考えられる。数理計画法もそうである。
(2)学生時代に知能ロボットの研究の際、障害物回避を含め最短時間経路探索するのにダイナミックプログラミングで最短経路を決定した。(詳細は以下を参照のこと)
3.大学院時代の研究内容
3-3.ゲームの理論
(1)ゲームの先読みにおいて数手先の状況について、評価関数を使って正しく判断することが必要である。自分の手が最大値になり、相手も最大値(自分にとっては、最悪値)の手を打つと仮定して、自分の手を決める。この手法をMiniMaxと呼んでいる。
(2)コンピュータハードとコンピュータ科学の発展に伴い、強力なゲームソフトが出現するようになった。その一つがアルファ碁である。
(3)アルファ碁の戦略は非常に複雑なようなであるが、次のように単純化すれば理解しやすい。
(A)序盤:「(強い棋士の16万局を使ったCNNによる)次の各手の確率」を主に使用
(B)中盤:「(3000万データで強化学習した)局面での勝率予測値」を主に使用
(C)終盤:「モンテカルロ木探索」を主に使用
(4)昨年10月アルファ碁ゼロが発表された。これは教師なしの強化学習だけで、アルファ碁を圧倒した。現実の世界への応用の可能性がある。
(詳細は以下を参照)
「<オージス総研をとりまく>人工知能技術の過去と現在(7)」
※続きは次号で述べます。
「Reference」
1. Ramprasaath R. Selvaraju, Michael Cogswell , et al,: "Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization", Mar 2017
*本Webマガジンの内容は執筆者個人の見解に基づいており、株式会社オージス総研およびさくら情報システム株式会社、株式会社宇部情報システムのいずれの見解を示すものでもありません。
『WEBマガジン』に関しては下記よりお気軽にお問い合わせください。
同一テーマ 記事一覧
 「人工知能技術の過去と現在(最終回)」
「人工知能技術の過去と現在(最終回)」
2019.03.15 製造 株式会社オージス総研 乾 昌弘
「<Part 2>人工知能技術の過去と現在(5)」
2018.11.12 製造 株式会社オージス総研 乾 昌弘
「<Part 2>人工知能技術の過去と現在(4)」
2018.09.13 製造 株式会社オージス総研 乾 昌弘
「<Part 2>人工知能技術の過去と現在(3)」
2018.08.10 製造 株式会社オージス総研 乾 昌弘
<Part 2>人工知能技術の過去と現在(2)
2018.07.19 製造 株式会社オージス総研 乾 昌弘
「<Part 2>人工知能技術の過去と現在(1)」
2018.06.15 製造 株式会社オージス総研 乾 昌弘
「人工知能技術の過去と現在(下)」
2018.03.19 製造 株式会社オージス総研 乾 昌弘
「スマートグリッド社会成熟度モデルと人工知能」
2018.01.24 製造 株式会社オージス総研 乾 昌弘
「AIなどを通じて経験したGlobal Business」
2017.12.15 製造 株式会社オージス総研 乾 昌弘
「ビジネスを解析する手法とその比較(AI含めて)」
2017.11.17 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(7)」
2017.10.25 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(6)」
2017.09.15 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(5)」
2017.08.28 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(4)」
2017.07.20 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(3)」
2017.06.19 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(2)」
2017.05.19 製造 株式会社オージス総研 乾 昌弘
「<オージス総研をとりまく>人工知能技術の過去と現在(1)」
2017.04.17 製造 株式会社オージス総研 乾 昌弘