サーバーダウンの原因と対策とは?システム障害を防ぐサーバー運用について解説
Webサービスを展開する企業において、サーバーダウンに備えたインフラを準備し、しっかりと対策を行っておくことが大切です。
サーバーダウンはさまざまな原因で発生する可能性があり、完全に防ぐことはできません。そのため、いかにサーバーダウンの発生を抑制し、サーバーダウンに備えた対策が行えているかが重要になってきます。
適切なサーバーダウンに対する対策が行えていないと、システム停止に伴うお客様からの信用低下や、停止時間の長期化に伴う機会損失が発生してしまいます。また、障害に対応するためのシステム運用スタッフの負荷が高まってしまうという課題があります。
本記事ではサーバーダウンの原因と対策から、システム障害を防ぐサーバー運用について解説いたします。
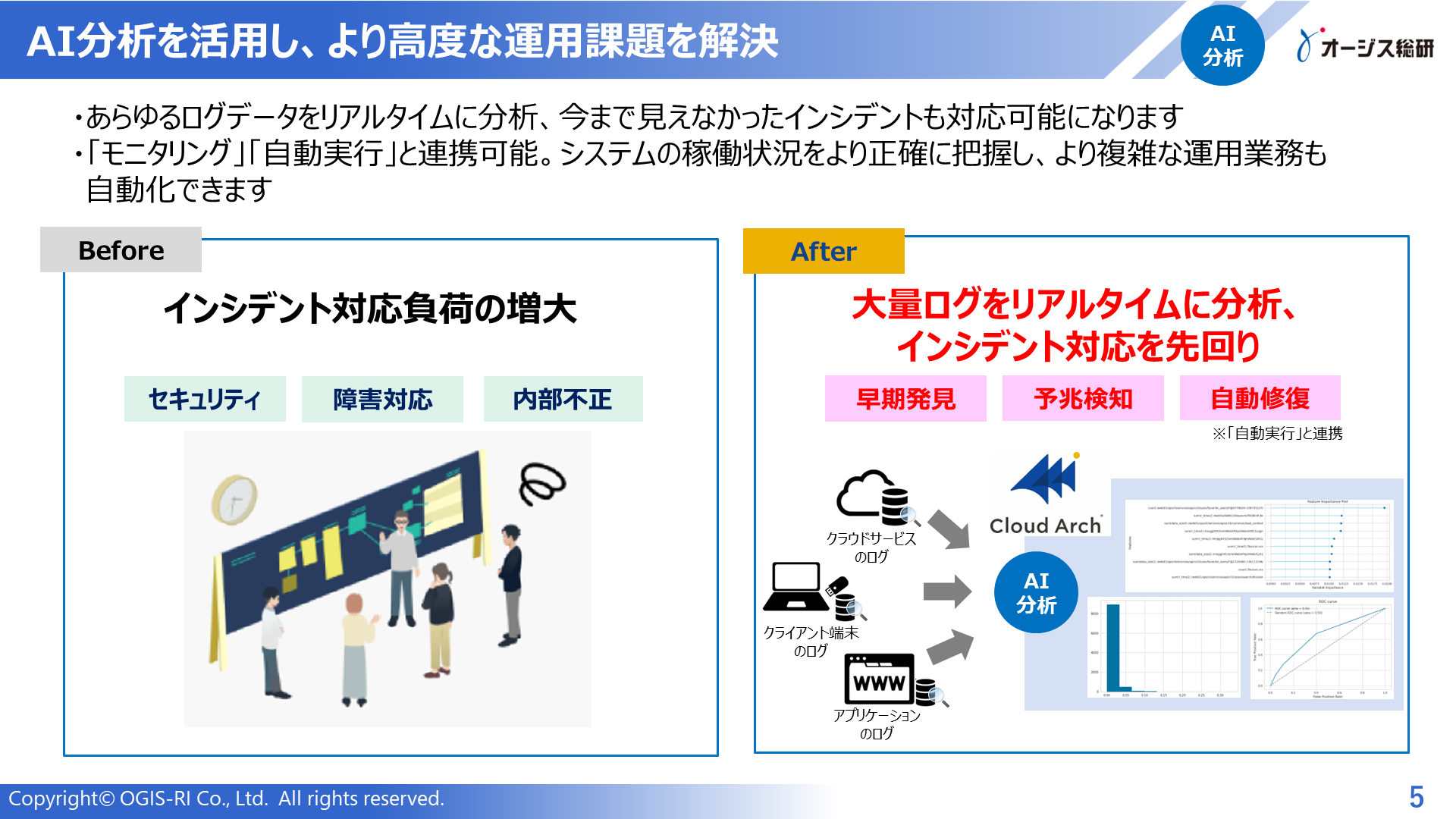
学べること
● 「Cloud Arch」で実現できることや主要機能
● コスト削減、人手不足解消、人為的ミス 0 の「Before/After」
● 導入後の運用イメージ
「Cloud Arch」の概要資料だけでなく、運用自動化の進め方やAIOpsの推進事例などの資料もございます。貴社の運用自動化やAIOps推進のヒントにぜひこれらの資料をご活用ください。
サーバーダウンの原因は?
サーバーダウンの原因として、ハードウェアの障害やシステム不具合などの内的要因と、アクセス集中やサイバー攻撃などの外的要因があります。
ハードウェア障害
サーバー機器は特に24時間365日の連続稼働が求められ、さまざまな機器パーツが劣化することで故障する可能性があります。
サーバーは5年~6年程度の耐用年数により償却費の計算を行っていることが一般的ですが、システムがこの期間を越えて更改されずに利用されるケースがあり、耐用年数を越えて利用を続けることで、経年劣化による故障のリスクが高まってしまいます。
さらに地震や災害などの天災や、火災などの事故でサーバーダウンしてしまう場合もハードウェア障害として分類されます。
ソフトウェア不具合
サーバー上ではサービスを提供するソフトウェアが稼働していますが、これらがソフトウェアの不具合により、搭載メモリを超えるメモリ要求(OOM / Out Of Memory)や、CPUの演算性能を上回る処理(ループ処理)などが発生し、サーバーダウンしてしまう可能性があります。特にサービスを提供するアプリケーションのソフトウェア不具合やバグは、入念な設計や構築、テストを行うことでリスクを低減できますが、完全になくすことはできません。
人為ミスによる不具合
サーバーは日々のメンテナンスや、監視アラート対応などで運用スタッフによるサーバー操作が発生する場合があります。作業におけるサーバーの誤操作や、設定ミス、メンテナンス不備など人為的なミスは完全に防ぐことは難しく、人為ミスによってサーバーダウンしてしまう可能性があります。
アクセス集中
テレビなどのメディアに取り上げられたり、ECサイトでセールを実施するタイミングでアクセスが集中し、サーバーの性能を上回る処理性能が必要となることでサーバーが応答不可状態に陥ったり、サーバーダウンしてしまう可能性があります。あらかじめサーバー台数を増やすことや、仮想基盤やクラウドの場合は割り当てリソースを増強するなどで備えることができますが、必要なパフォーマンスを各ケースで最適に需要予測を行うことは容易ではありません。
サイバー攻撃
インターネット上に公開してサービス提供を行うということは、全世界のあらゆる場所から悪意のある攻撃者によりサイバー攻撃を受ける可能性があります。
特にサービス妨害攻撃である「DoS攻撃」は、サーバーやネットワークに過剰に負荷をかけることでサービスの運用や提供を妨げる攻撃であり、複数のクライアントから一斉に攻撃を仕掛ける分散型サービス攻撃である「DDoS攻撃」などは完全に防ぎきることは難しく、クラウドサービスと組み合わせることなどで、その影響を緩和する必要があります。
サーバーダウンによる障害影響とは?
上記のように内的要因・外的要因により発生するサーバーダウンですが、これらに対して対策が不十分だと、システム障害を引き起こし、さまざまな悪影響が懸念されます。
ブランド力の低下
Webサービスがサーバーダウンによって閲覧・利用できない状態に陥ると、その原因にかかわらず、障害期間はユーザーの利便性を損なうことになります。信用低下やブランド力の低下の恐れがあります。
販売機会の損失(売上が減る)
ECサイトの運用や、通販サイトなどへの販売チャネル誘導などを該当のサーバーが行っている場合、障害が発生すると販売機会の損失につながり、結果として売上が減少してしまいます。
運用スタッフの負荷が高まる
サーバーダウンに対して即座に対応が求められる状況の場合、障害の対応は常に高い優先度のタスクとして運用スタッフの業務負荷を高めてしまいます。また夜間休日対応の運用スタッフの緊急対応などが頻発すると、日中時間帯の業務運営にも悪影響が懸念されます。
学べること
● 「Cloud Arch」で実現できることや主要機能
● コスト削減、人手不足解消、人為的ミス 0 の「Before/After」
● 導入後の運用イメージ
「Cloud Arch」の概要資料だけでなく、運用自動化の進め方やAIOpsの推進事例などの資料もございます。貴社の運用自動化やAIOps推進のヒントにぜひこれらの資料をご活用ください。
サーバーダウンに備える対策とは?
サーバーダウンを完全に防ぐことはできませんが、あらかじめ対策を行うことで障害に対して影響を受けにくく、レジリエンス(回復力や弾性)を持ったシステムを運用することができます。
サーバーのスペックを上げる(スケールアップ)
最も基本的な対策となりますが、サーバーはリソース(CPU/メモリ)に余裕を持った運用によりシステム稼働が安定します。過剰なリソースを割り当てる必要はありませんが、ピークで求められる性能をしっかりとサーバーサイジング(必要な規模や性能を見積)し、中長期での利用率の向上を見据えたリソースの割り当てを行うことが大切です。
サーバーを冗長化する(スケールアウト)
こちらも近年のサーバー運用では欠かせない対策ですが、2台以上のサーバーでシステムを構成することで、たとえ1台のサーバーがダウンしてしまったとしても、継続してサービスを提供することが可能な構成をとることが可能です。サーバーの冗長化方式にはさまざまなものがあり、使用するOS、ミドルウェア、アプリケーションによって最適なものを選択することが重要です。
また、スケールアウトに欠かせないのがロードバランサであり、サーバーの冗長化構成を制御する役割を担います。ロードバランサと組み合わせることでサーバーダウンが発生したサーバーが復旧するまでの間、システム影響がでないようにユーザーからのアクセス経路を適切に制御することが可能となります。
クラウドサービスを活用する
先述したスケールアップやスケールアウトは、サーバーが物理的な機器に依存する場合は追加の調達が必要になりますが、クラウドサービスを活用することで必要なタイミングに従量課金でリソースを追加することが可能です。
そして、クラウドでは負荷に応じたスケールアウトやロードバランサとの連携もあらかじめ機能として提供されている場合が多く、専用のネットワーク機器を調達する必要もありません。
さらに主要なパブリッククラウド(AWS/Azure/GCP)のサーバーは自動復旧機能などが提供されており、運用スタッフの作業を介することなく直ちに障害復旧を行うことができます。このことで人為ミスを抑制できますし、運用スタッフ負荷を低減することが可能となります。
また、クラウドサービスは非常に大規模なインフラで運用されているため、サイバー攻撃に対して耐性のあるネットワーク基盤や緩和技術が提供されています。
テストを自動化する
サーバーダウン対策が難しい要因の1つとして、アプリケーションが抱えるソフトウェア不具合があります。この問題には、アプリケーション開発においてCI/CDパイプライン(継続的なインテグレーションとデリバリーを実現するソフトウェア開発支援技術)を整備することで大きな対策効果が得られます。CI/CDパイプラインのなかで自動テストを各フェーズで設定することで、各アプリケーションリリースで常に一定の品質テストをクリアしたアプリケーションを開発することが可能です。
また、テストを自動化することで人為ミスを抑制し、ソフトウェアバグが発生しにくい開発環境を実現することができます。
サーバーの可観測性(Observability)を確保する
上記の通り内的要因には事前に対策を行うことができますが、アクセス集中やサイバー攻撃などの外的要因は完全に予測することは困難です。そのため、サーバーが適切なリソースで稼働していることを確認する稼働統計や監視、ログの収集は、安定したサーバー運用に欠かせません。特に近年のサーバーはクラウドサービスと組み合わせることで柔軟にリソースが変化し、サーバー台数が増減する可能性があることから、クラウドに対応した監視基盤を準備することが大切です。
このような現在のシステムの健全性を計測し、変化に対して追従することができる状態を可観測性(Observability)があると呼ばれ、サーバーの安定稼働のために重要な要素となっています。
SLO(サービスレベル目標)を持って対策を検討する
上記に記載した対策は、それぞれに対策コストが発生するため、コストと対策効果を両立する必要があります。そのためにもシステムに求められるSLO(サービスレベル目標)をあらかじめ設定しておくことで、設計の段階から適切なサーバー構成や対策を検討することが可能になります。
まとめ
サーバーダウンには内的要因と外的要因があります。対策によってサーバーダウンによる影響を防ぐことができることをご紹介しました。
オージス総研が提供する運用自動化ソリューション「Cloud Arch」は、ハイブリッドクラウドに対応したモニタリングサービスで、各クラウドベンダーが提供する監視サービスと連携し可観測性(Observability)をご提供します。
さらに「Cloud Arch」は監視アラート対応などを自動化処理することが可能な運用自動化ソリューションをご提供しています。これまで培ってきた運用実績をもとに、豊富な自動化メニューを取り揃えていることに加え、お客様環境に合わせて有資格エンジニアがカスタマイズすることも可能です。また、無料で試行いただける環境(障害アラート自動コール試行版)もご用意しておりますので、ご興味のある方はぜひともお問い合わせください。
2022年6月8日
学べること
● 「Cloud Arch」で実現できることや主要機能
● コスト削減、人手不足解消、人為的ミス 0 の「Before/After」
● 導入後の運用イメージ
「Cloud Arch」の概要資料だけでなく、運用自動化の進め方やAIOpsの推進事例などの資料もございます。貴社の運用自動化やAIOps推進のヒントにぜひこれらの資料をご活用ください。
関連サービス
-
 運用自動化ソリューション「Cloud Arch」
運用自動化ソリューション「Cloud Arch」
オンプレミスシステムやプライベート / パブリッククラウドの複数サービスを利用しているシステム環境に対し、シームレスな運用自動化と統合監視の環境をご利用いただくことで複雑化するシステム運用の負担低減を実現します。
-
Cloud Arch『障害アラート自動コール』試行版のご紹介
運用自動化ソリューション Cloud Archの『障害アラート自動コール』試行版を無料でお使いいただけます。
関連記事一覧
- 死活監視とは?外形監視との違いや方法、監視後の対応について
- NewRelicとは?機能と特徴、できることをわかりやすく解説
- メインフレームとは?撤退か進化か、現状の課題と今後の選択肢
- ITOM(IT運用管理)とは?ITSMやITAMとの違いやツールの機能・概要を解説
- 【AWS】Amazon CloudWatch Logsとは?ログ収集・監視など何ができるのかや他のツールとの違いを解説
- 外形監視とは?死活監視との違いやおすすめツール
- オブザーバビリティとは?意味や監視との違い、IT運用における必要性を解説
- Splunkとは?ログ監視や分析、セキュリティー強化などを解説【スプランク入門】
- APM(アプリケーション性能管理)とは?意味や性能監視の重要性、APMツールの選び方
- AIOpsを始めるために必要なことを解説
- AIOpsとは?メリットや導入手順、効果の把握方法、運用事例を解説【相性チェックリスト付き】
- システム・サーバー運用業務の自動化が進まない理由と運用自動化を成功に導くポイント
- 運用自動化プラットフォームKompiraとは?特長と導入メリット、事例について
- サーバー監視とは?目的やツールの選び方、自動化について解説
- 運用自動化の事例紹介-システム運用をラクにする運用自動化を実現するには?
- 運用自動化とは?自動化のメリットと方法、効率の良い進め方を解説
- システム運用管理とは?保守管理との違いや仕事内容、業務効率化の方法を解説